페이퍼 및 기타 리뷰들만 읽어서 머리에 정리가 되지 않는 것 같아 정리를 하는 겸 기록한다.
기존의 SFT(Supervised Fine tuning)으로는 한계점이 많고, 데이터의 편향성을 그대로 표출한다. 즉, 학습 데이터를 통해 attention score를 계산하여 토큰 간에 관계를 학습하고, 이러한 데이터가 많았다면 생성을 할 때도 그대로 생성을 하게 된다.
어떻게 보면 비슷한 느낌의 비슷한 데이터를 자주 학습하게 되면 모델 자체가 편향되어 비슷한 말만 뱉어내고 다채롭지 않은 것도 같은 이유라고 볼 수도 있을 것 같다.
그렇다면 말을 다채롭게 하고자 한다면 어떻게 해야할까? 그리고 데이터의 편향성을 줄이려면 어떻게 해야할까?
OpenAI의 InstructGPT가 후자의 질문에 대한 답변으로 제시한 것이 RLHF(Reinforcement Learning from Human Feedback)이라는 방법론이다.
Method
그렇다면 어떻게 모델을 학습하는 와중에 강화학습을 활용하여 인간의 피드백을 반영할 수 있을까?
다음과 같은 3단계로 학습을 진행한다.
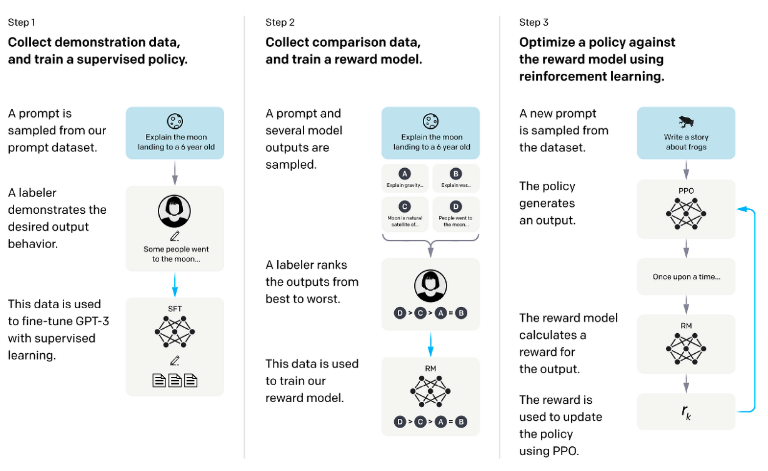
Step1.
기존에 어떤 prompt가 오면 어떤 completion을 했으면 좋겠는지에 대한 SFT용 데이터셋을 준비한다. 데이터셋의 예시는 이렇다.
prompt:임진왜란이 어떻게 하여 발생했어?
completion:임진왜란은 ~~~~~~~~~~~~~이러한 데이터를 활용하여 초기 사전학습만 진행된 모델을 SFT를 진행한다.
Step2.
이번 단계에서는 어떤 출력이 더 적절한지 rank가 매겨져 있는 데이터셋이 필요하다. 그림에도 나와있듯이 여러 모델(예를 들어, Llama, claude 등등)이 출력한 답변들의 rank를 매긴다.
chosen
prompt:임진왜란이 어떻게 하여 발생했어?
completion:임진왜란은 ~~~~~~~~~~rejected
prompt:임진왜란이 어떻게 하여 발생했어?
completion:잘 모르겠는데?위와 같이 같은 prompt에 여러 답변이 rank된 데이터셋이 필요하다. hallucination문제를 푸는 것 뿐만이 아닌, 문맥에 맞지 않은 답변이 데이터셋에 들어갈 때 더 적절한 답변이 나올 수 있도록 reward model을 학습하는데 사용된다.
Step3.
새로운 프롬프트를 SFT가 된 모델에 집어 넣고(이 모델의 파라미터를 PPO로 업데이트한다.) 그로 인해 나온 출력물을 다시 reward model에 집어 넣어 reward를 추출한다. 이 값은 scalar다. 이 값과 여러 수식들을 통해 loss를 구해 SFT가 된 모델의 파라미터를 업데이트한다.
그림으로 조금 더 자세히 알아보자.
Step1.
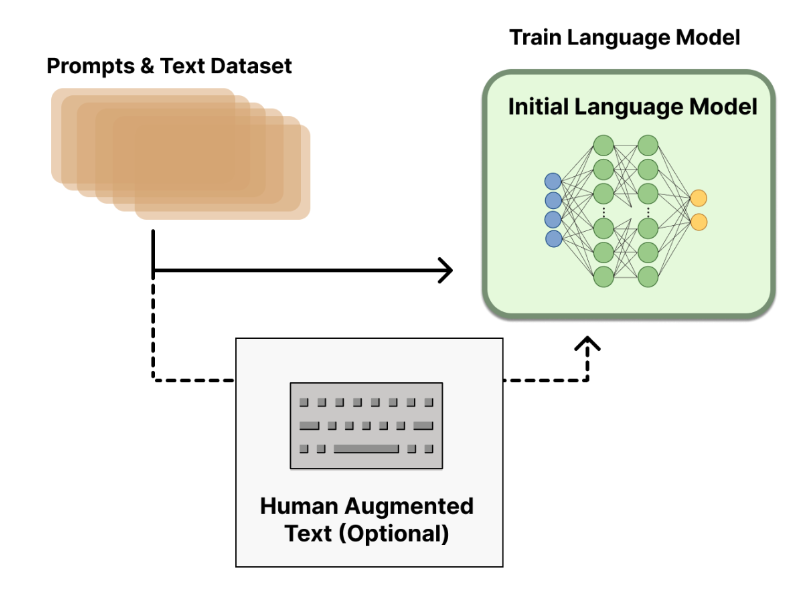
Prompts와 Completions로 이루어진 SFT용 데이터셋을 준비한다. 이 데이터셋을 활용하여 초기 사전 학습만 된 LM을 학습을 한다.
Step2.
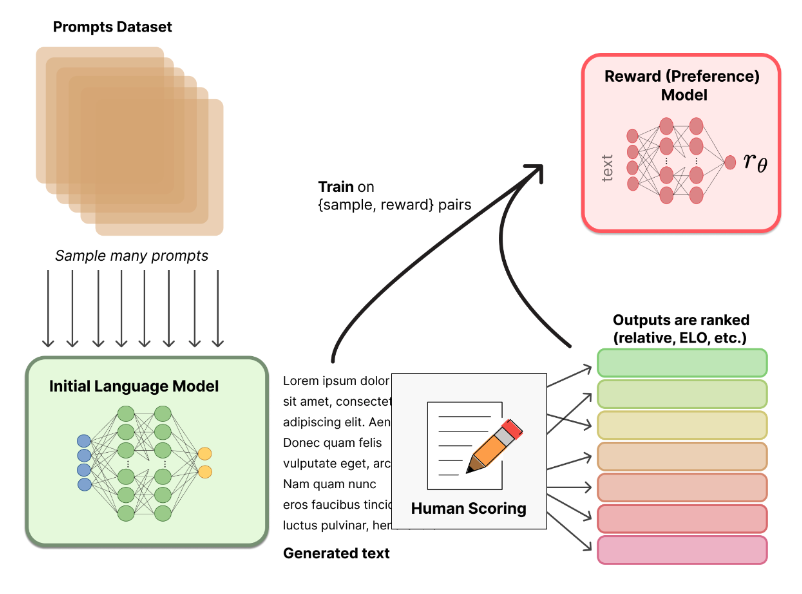
Prompts 데이터셋 풀에서 샘플링을 진행하여 이러한 것을 가지고 step1에서 SFT를 한다고 하였다. 이제 SFT가 된 모델을 가지고 생성을 한다. 생성을 하게 되면 출력으로 Generated text가 나오게 될텐데, 이를 Human annotator들이 랭크를 매기게 된다. 어떤 답변이 주어진 프롬프트에 더 적절한지, 이런 것들을 랭크를 매기게 된다. 그림에는 sample과 reward가 pair가 되어 리워드 모델의 학습 데이터셋으로 구성된다고 되어 있는데, human annotator에게 단순히 리워드 스코어를 작성하라고 하면 사람마다 기준이 달라서 정확하지 않다. 그래서 랭크를 기반으로 스코어를 매긴다.
그렇다면 스코어는 어떻게 측정할까?
같은 프롬프트에 대해 여러 답변을 평가하게 하여 랭크를 매긴뒤, ELO와 같은 rating system을 통해 점수를 매긴다. 이러한 것을 바탕으로 {샘플, 리워드}를 pair로 하여 데이터셋을 구축한다.
이러한 데이터셋을 기반으로 리워드 모델의 output은 scalar 값이 되어야 한다.
Step3.
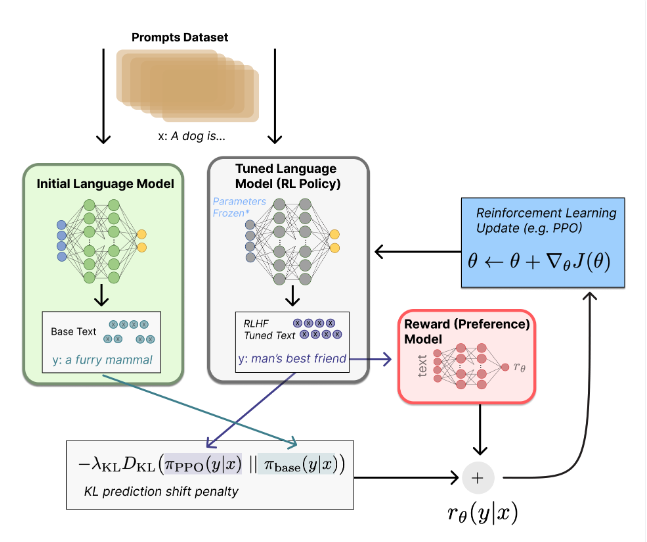
일단 기본적으로 step3의 목적은 최종적으로 튜닝된 모델을 만들기 위해 리워드 모델을 활용하여 기존의 SFT만 된 모델을 추가 튜닝을 진행한다. 그렇다면 튜닝을 하기 위한 update rule은 무엇이 될까?
그림에서 볼 수 있듯이 PPO방식으로 현재 배치 단위마다 업데이트된다. 전체적인 구조는 다음과 같고, 각각의 부분은 왜 실행하는지를 한 번 살펴보자.
그림에서 보면 KL divergence를 수행하는 것을 볼 수 있다. KL divergence는 기본적으로 두 확률 분포가 주어졌을 때, 두 분포가 얼마나 유사한지 비교할 수 있는 metric이다.
이므로 유의해야 한다. base모델을 기준으로 PPO로 업데이트 되고 있는 모델의 분포가 얼마나 차이나는지 계산하는 식이다. 그 값을 최종 reward에 더해줘서 초기 모델을 너무 벗어나지 않도록, 너무 편향되지 않도록 막아주는 값이다.
