
EDA란,
데이터 분석을 위해 데이터를 다양한 각도로 관찰하고 이해하는 과정을 탐험적 데이터 분석, EDA(Exploratory Data Analysis) 라고 한다.
-
데이터의 특징과 내재하는 구조적인 관계를 알아내기 위한 분석기법이다.
-
이론적 모형을 적용하기보다 데이터를 있는 그대로 보려는데 중점을 두고 데이터 스스로 말하도록 유도하는 분석법이다.
-
자료의 구조 및 특징 파악을 위하여 자료의 요약과 그래프 기법의 활용한다.
환경설정
Jupyter를 이용한 파이썬 환경설정
✅ MiniConda
Conda는 오픈 소스의 패키지 관리 및 환경 관리 시스템으로 패키지 설치, 업데이트, 제거, 패키지 간 종속성 관리, 가상 환경 생성 등을 처리한다.

-
Miniconda는 Anaconda의 간소화된 버전으로, 콘다 패키지 관리자와 몇 가지 핵심 라이브러리만을 포함한 경량화된 배포판이다.
-
콘다를 사용하여 필요한 패키지를 선택적으로 설치할 수 있어 개별 프로젝트에 필요한 최소한의 패키지만을 설치하고자 할 때 유용하다.
작업에 맞는 최적화된 환경을 구성할 수 있다. -
콘다를 활용해 가상 환경을 생성하고 관리할 수 있다. 이는 각각의 프로젝트가 독립적인 환경을 유지하고 필요한 패키지를 관리하는 데 유용하다.
< Conda 가상환경(ds_study) 생성 >
- MiniConda 설치 후 콘다 버전 확인 및 업데이트
(base) conda env list
(base) conda --version
(base) conda update conda
(base) conda --version- 가상환경 생성 및 활성화
(base) conda create -n ds_study python=3.8
(base) conda activate ds_study
(ds_study) conda deactivate✅ Jupyter Notebook
Jupyter Notebook은 대화형 컴퓨팅과 데이터 시각화를 지원하는 웹 응용 프로그램이다.

-
코드를 작성하고 실행하는 데 있어서 대화형 환경을 제공하므로 코드 셀에 코드를 입력하고 실행하면 결과가 즉시 표시되어 실시간으로 코드를 확인하고 수정할 수 있다.
-
matplotlib, seaborn, bokeh 등의 시각화 도구와 연동하여 데이터를 시각적으로 탐색하고 표현하는 데 용이하다.
< 설치 및 실행 >
(ds_study) conda install jupyter
(ds_study) ··· 패키지들 설치 ···
(ds_study) jupyter notebook✅ Packages
< 설치 >
- 내 가상환경(ds_study)에 필요한 패키지들을 설치한다.
(ds_study) conda install -y ipython
(ds_study) conda install -y pandas
(ds_study) conda install -y matplotlib
(ds_study) conda install -y seaborn
(ds_study) conda install -y scikit-learn
(ds_study) conda install -y xlrd❕ IPython
IPython(Interactive Python)은 Python 인터프리터의 강화된 버전으로, 대화형으로 Python 코드를 작성하고 실행할 수 있도록 해주는 도구이다.
-
Python 기본 인터프리터의 대화형 기능을 향상시켜 코드를 한 줄씩 입력하고 실행할 수 있으며, 결과를 즉시 확인할 수 있다.
-
!로 시작하는 셸 명령어를 실행할 수 있어 셸 명령어와 Python 코드를 함께 사용할 수 있다. -
IPython은 Jupyter Notebook과 통합되어 있다.
Jupyter Notebook은 IPython을 기반으로 한 대화형 문서 형식으로, 코드와 문서를 통합하여 데이터 분석 및 시각화 작업을 하는 데 용이하다.
❕ Pandas
Pandas는 Python에서 데이터 조작과 분석을 위한 라이브러리로, 특히 데이터프레임(DataFrame)이라는 자료 구조를 중심으로 설계되어 있다.
-
DataFrame: 2D 테이블 형태의 데이터 구조로, 엑셀 스프레드시트나 SQL 테이블과 유사하다.
-
Series: 1D 데이터 구조로, DataFrame의 열이나 행을 나타낸다.
Series는 단일 열이나 행의 데이터를 다루는 데 사용한다.
❕ Matplotlib
파이썬에서 2D 그래픽을 생성하는 데 사용되는 라이브러리로 데이터 시각화에 널리 사용되고 있다.

-
선 그래프, 막대 그래프, 산점도, 히스토그램, 원 그래프 등 다양한 종류의 그래픽을 그릴 수 있다.
-
다양한 맞춤 설정 옵션을 제공하여 색상, 선 스타일, 레이블 등을 사용자가 원하는 대로 설정할 수 있다.
< matplotlib 한글 설정 >
-
먼저 설정할 폰트 이름을 알아낸다.
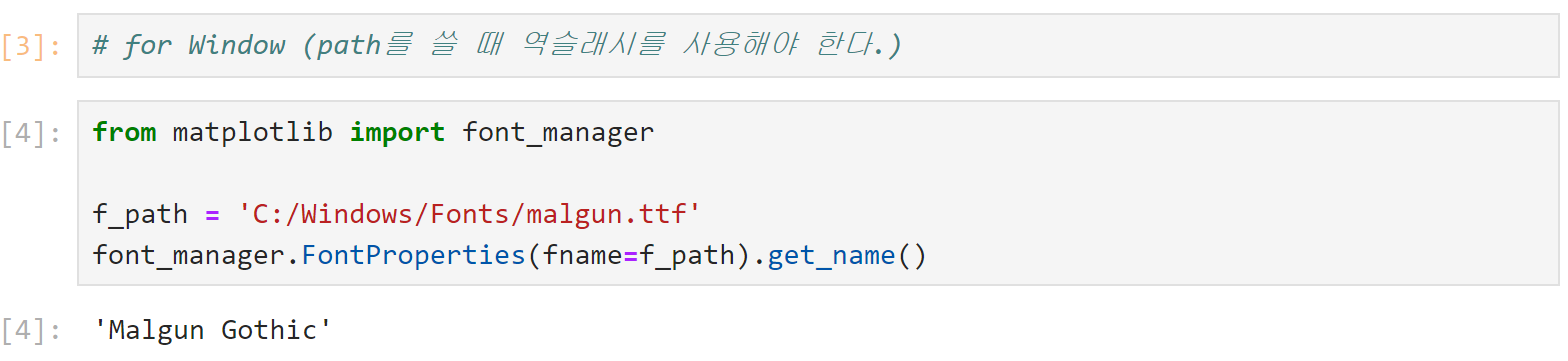
-
matplotlib의 font family로 설정하고 다시 실행한다.
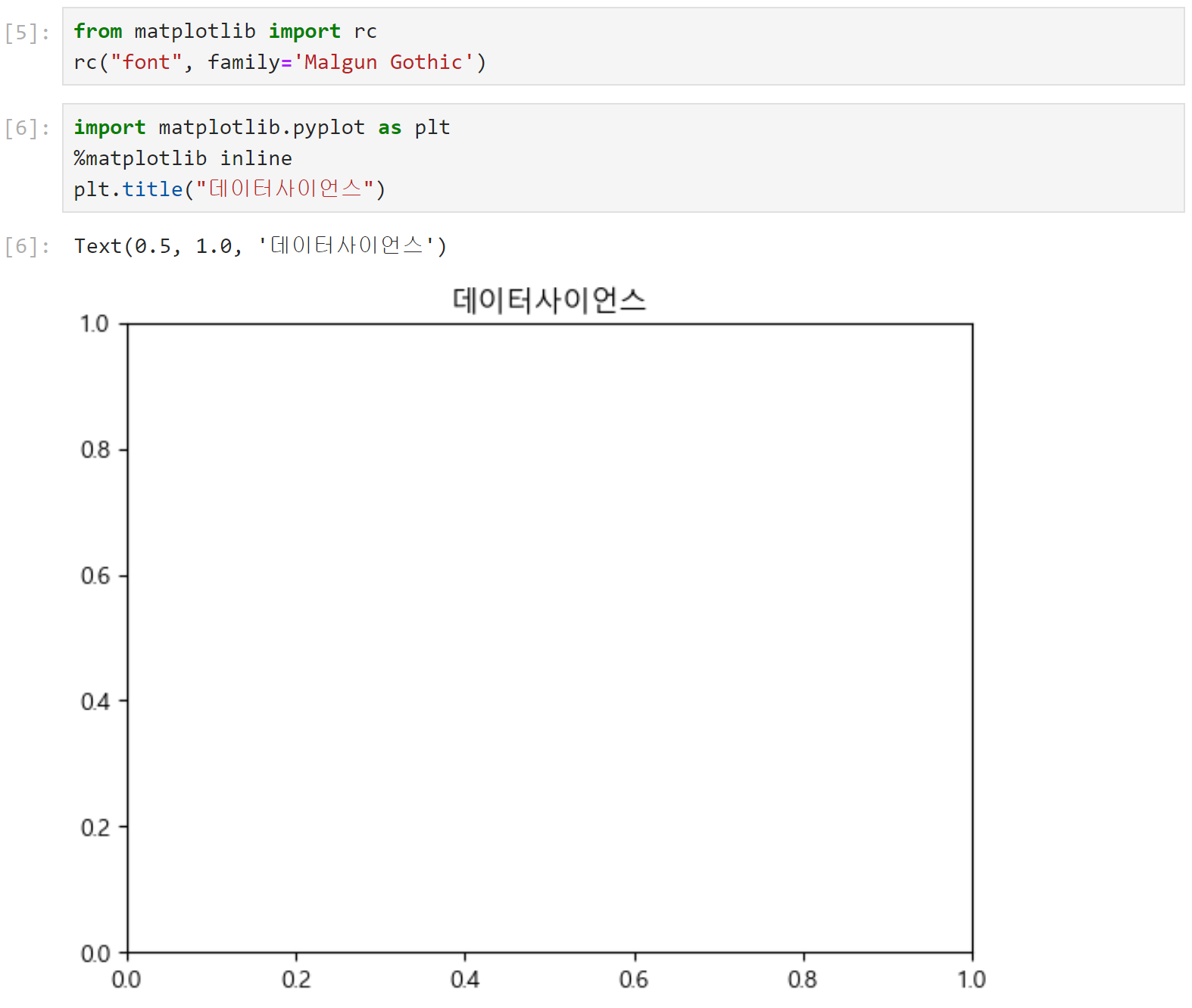
❕ Seaborn
Python의 데이터 시각화 라이브러리 중 하나로 통계 데이터를 시각화하는 데 사용한다.
-
히스토그램, 커널 밀도 플롯, 박스 플롯, 회귀 선과 같은 통계적인 시각화를 간편하게 생성할 수 있다.
-
Matplotlib에 기반하고 있어 Matplotlib을 통해 그림을 그리는 데 좀 더 간편한 높은 수준의 인터페이스를 제공한다.
-
Seaborn은 데이터프레임과 같은 Pandas 데이터 구조와 잘 통합되어 있어 데이터프레임을 바로 시각화 함수로 전달할 수 있어 데이터를 쉽게 시각화할 수 있습니다.
❕ scikit-learn
scikit-learn은 파이썬에서 사용할 수 있는 머신러닝 라이브러리로 다양한 머신러닝 작업을 수행하는 데 편리하게 사용될 수 있는 강력한 도구이다.
-
분류, 회귀, 클러스터링, 차원 축소 등 다양한 머신러닝 알고리즘을 제공한다.
-
누락된 값의 처리, 스케일링, 범주형 데이터 처리 등 데이터를 전처리하고 준비하는 데 사용되는 다양한 도구를 제공한다.
-
모델의 성능을 평가하고 선택하는 데 사용되는 다양한 지표와 도구를 제공한다.
-
다른 파이썬 라이브러리들과의 상호 운용성을 제공하여 NumPy, Matplotlib 등과 통합하여 사용할 수 있다.
❕ Xlrd
파이썬에서 Excel 파일(.xls)을 읽기 위한 라이브러리이다.
- .xlsx 형식은 지원하지 않습니다.
.xlsx 형식의 파일을 읽기 위해서는 openpyxl, pandas와 같은 다른 라이브러리를 사용할 수 있다.
❕ Openpyxl
파이썬에서 Excel 파일(.xls, .xlsx)을 읽기 위한 라이브러리이다.
-
Pandas는 엑셀 파일을 손쉽게 읽고 데이터프레임으로 변환하는데에 사용된다.
-
Pandas에서 엑셀 파일 형식(.xls 또는 .xlsx)을 읽어올 때
read_excel함수를 사용하는데 이 함수가 내부적으로 xlrd나 openpyxl과 같은 엑셀 읽기 라이브러리를 사용한다.
