Conditional Generative Model
Conditional generative model
주어진 조건에에 따라 이미지를 생성하는 모델이다.

기존의 generative model은 noise로 부터 random한 sample을 생성하지만 conditional generative model은 noise + condition을 함께 입력 받아 주어진 condition 내에서 random한 sample을 생성한다.

- Loss를 MAE/MSE로 한다는 것
loss를 mae, mse로 하면 average looking image를 생성한다. → blur한 이미지
gan loss는 discriminator가 구분할 수 없게끔 얼마나 진짜처럼 보이는 가를 확인해야 한다. 아래와 같이 회색이 들어오면 ‘real data 중에 너같은 애는 본적없는데?’ 같은느낌임..→ sharp한 이미지를 생성할 수 있다.
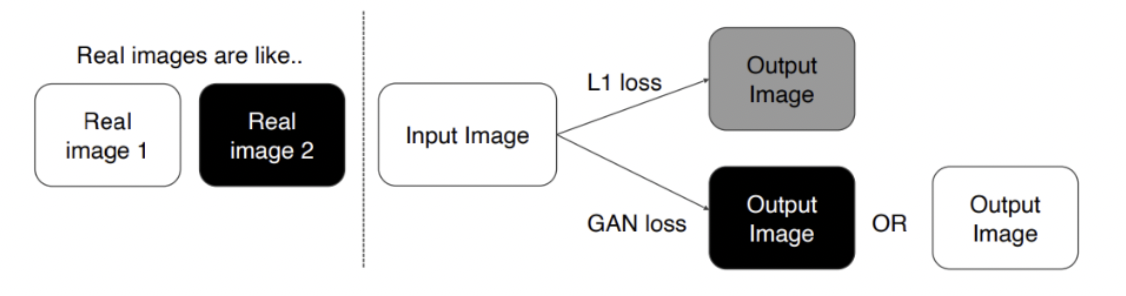
Image translation GANs
Pix2Pix
한 이미지를 그에 상응하는 다른 도메인의 이미지로 바꿔준다.
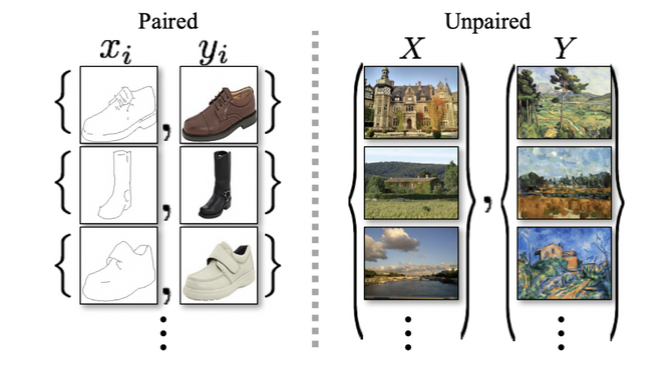
supervised learning으로 pair한 데이터셋이 필요하다.
L1 loss + gan loss 둘 다 사용한다. L1 loss만 쓰면 blur한 이미지가 나오므로 gan으로 실제 이미지같은 결과물을 얻게될 수 있다. 또한 gan loss만으로 학습시키는 것은 매우 어렵다.

CycleGAN
pix2pix에서는 pair한 데이터셋을 얻어야 했는데 이는 굉장히 구하기 어렵다.
CycleGAN에서는 non pair한 데이터셋으로 도메인간 translation이 가능하다.
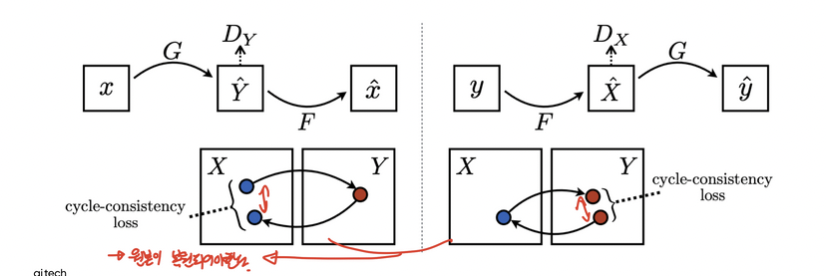
gan loss + cycle consistency loss를 사용한다.
Lgan(X→Y) + Lgan(Y→X) + Lcycle(G, F)
x에서 y로 갔다가 다시 x로 생성했을 때 원본과 유사해야한다.
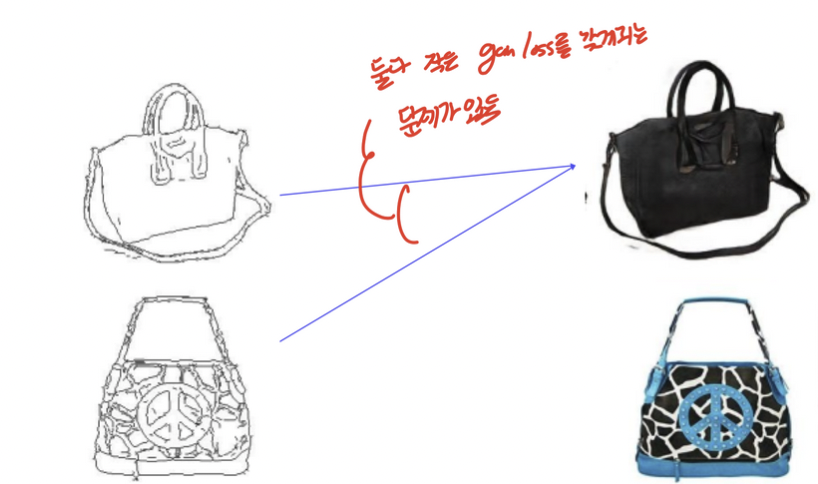
gan loss만을 사용하게 되면 input에 상관없이 하나의 output만 생성할 수 있다.
GAN Loss만 사용할 경우
cycle consistency loss사용시
Perceptual loss
GAN 학습시키는건 어렵다. 그래서 GAN Loss없이 high quality의 이미지를 생성하는 다른 방법은 없을까?
GAN loss
학습과 코딩이 어렵고
pre trained된 network가 필요하지 않다.
pre trained된 network가 필요하지 않아서 다양한 어플리케이션에 적용이 가능하다.
Perceptual loss
코딩과 학습이 쉽다.
learned loss를 측정하기 위한 pre trained network가 필요하다.
pre-trained모델은 사람의 시각인지와 비슷하다.
pre trained된 perception을 사용해 우리는 한 이미지를 perceptual space로 바꿀 수 있다.
image tranform net: input으로부터 변형된 output을 만든다.
loss net: 생성된 이미지와 target 사이의 style과 feature loss를 구한다.
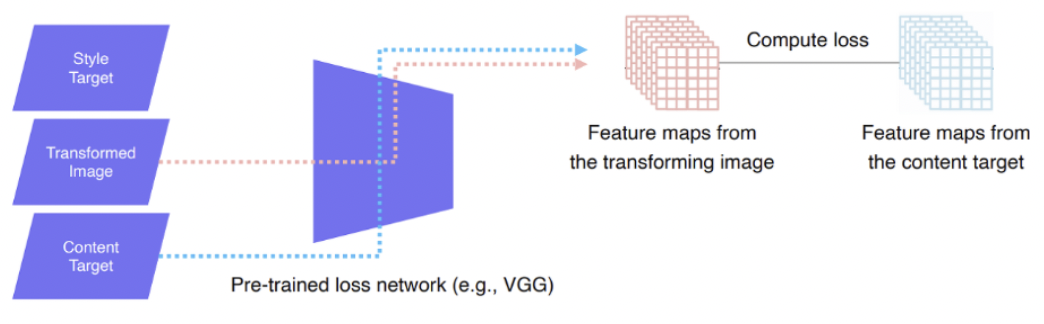
Feature Reconstruction loss: output image와 content target image 각각 loss network에서 만든 feature map을 이용해 L2 Loss를 계산한다.
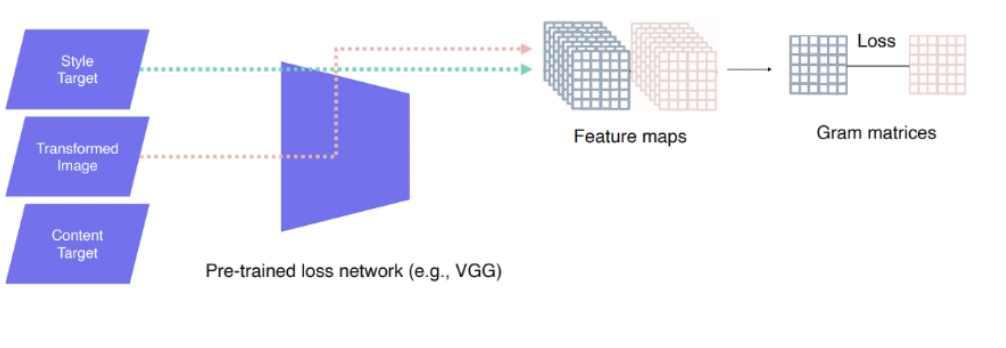
Style reconstruction loss: output image와 style target image 각각이 loss network에서 만든 feature map을 이용해 gram matrix를 만들고 이들 사이의 L2 loss를 구한다.
gram matrix는 공간적인 정보없이 통계적인 정보만 갖는다.
참고: boostcamp ai tech 4기 cv강의
