구현코드보단, KHU 필기 시험을 대비해 SVM 모델 구축하는 과정 및 이론적인 내용에 대해 정리해보고자 한다.
💯 SVM이란?
Support Vector Machine은 decision boundary 즉 hyperplane을 경계로 분류를 진행하는 기법. 따라서 hyperplane을 정의하는 것이 상당히 중요하다.
만일, 2개의 feature가 존재한다면 다음과 같은 선 형태로 hyperplane이 두 feature를 구분할 것이다.
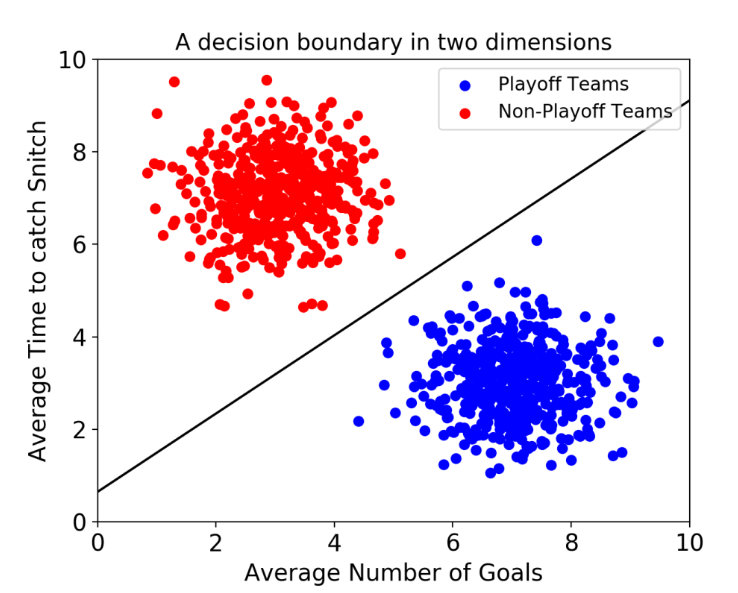
그러나 이는 단순한 2차원을 표기한 것으로 차원이 늘어난다면 다음과 같이 표현된다.
이때의 hyperplane은 평면으로 구성될 것이다.
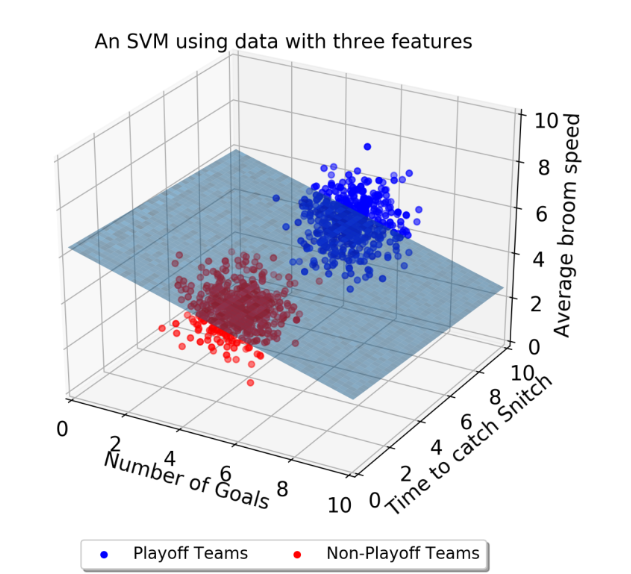
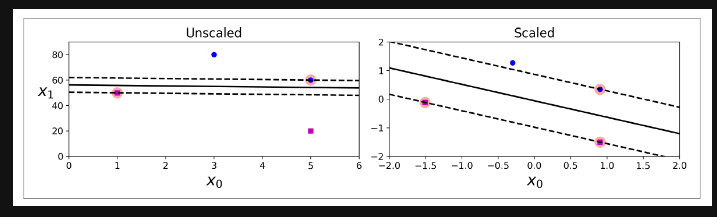
Feature Scaling
SVM에서 Feature scaling은 편향된 결과를 도출하지 않도록하는 가장 중요한 방법이다.
위 그림처럼 scale이 다른 두 feature에 대해 모델학습을 하는 경우, scale이 큰 쪽에 weight가 똑같이 커지는 비정상적인 현상이 발생할 수 있다.
따라서 오른쪽 그림과 같이 주어진 feature에 대해 scaling을 진행하여 편향되지 않도록 전처리를 진행해야 한다.
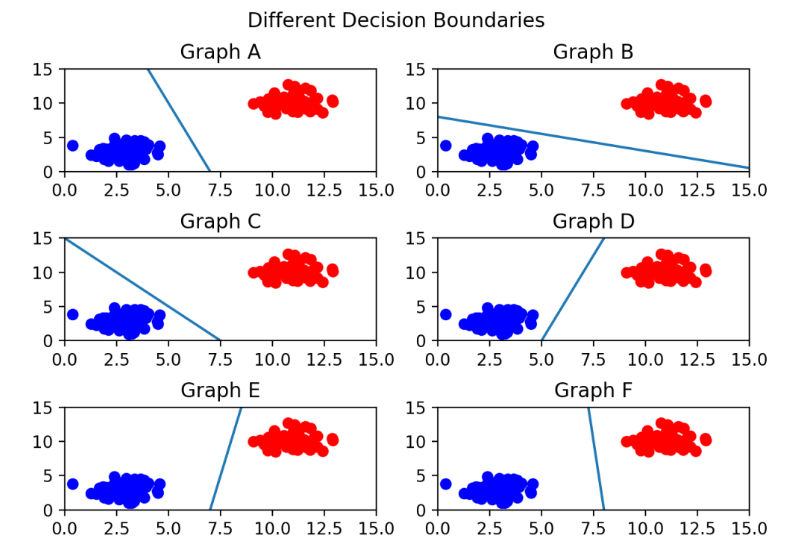
최적의 hyperplane
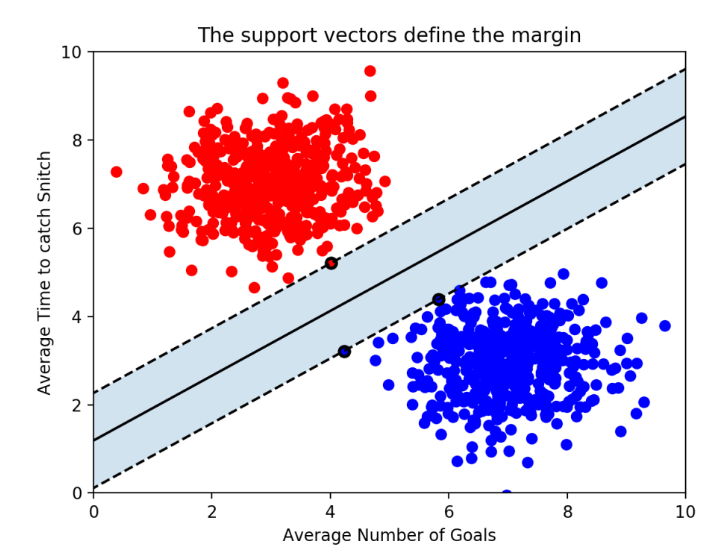
Graph C의 경우 파란색 feature로 hyperplane이 쏠린 모습이고, 가장 적절하게 분류가 진행된 도표는 Graph F로 확인된다.즉, hyperplane은 데이터 군집으로부터 거리가 최대로 떨어져있는 것이 좋다.
그렇다면, 최적의 hyperplane은 어떻게 결정하나? 바로 답은 마진.
마진이란 hyperplane과 서포트 벡터 간 사이 거리를 의미
Support Vector
서포트 벡터란, hyperplane과 가장 가까운 데이터 포인트를 의미한다. n개의 feature를 가진 데이터에는 최소 n+1개의 서포트 벡터가 존재함을 알 수 있다.hyperplane 경계를 두고 위쪽 선을 plus plane, 아래 쪽 선을 minus plane이라 부른다.
이때 이를 수리적으로 Lagrangian Formulation을 이용하여 수학적으로 계산한 결과는 다음과 같다.
이때 w,b를 모르는 임의의 수로 두었으므로 우변에 존재하는 상수로 위 식을 전부 나누어 표현해도 다음과 같이 표현할 수 있다.
plus plane과 minus plane, support vector를 알고 있는 지금 우리가 구하고자 하는 마진을 최대로하는 SVM의 hyperplane을 구하는 목적함수 및 제약식은 아래와 같다.
여기에 Lagrangian Formulation을 진행하면 아래와 같은 목적함수에 대한 보조방정식을 얻을 수 있다.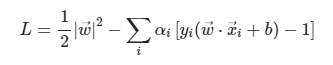
- SVM의 나름 장점?
대부분의 머신러닝 지도 학습 알고리즘은 학습 데이터 모두를 사용하여 모델을 학습한다. 그런데 SVM에서는 결정 경계를 정의하는 게 결국 서포트 벡터이기 때문에 데이터 포인트 중에서 서포트 벡터만 잘 골라내면 나머지 쓸 데 없는 수많은 데이터 포인트들을 무시할 수 있다. 그래서 매우 빠르다.
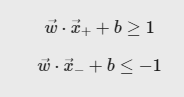

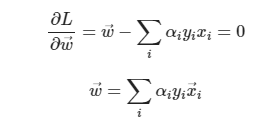
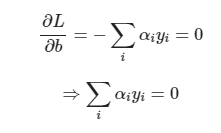
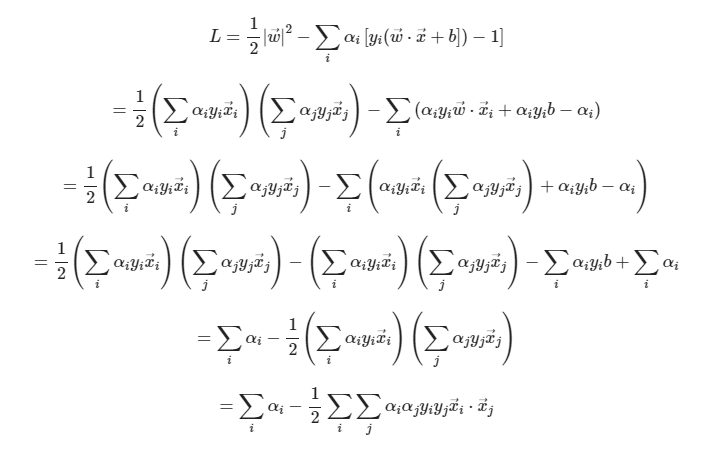
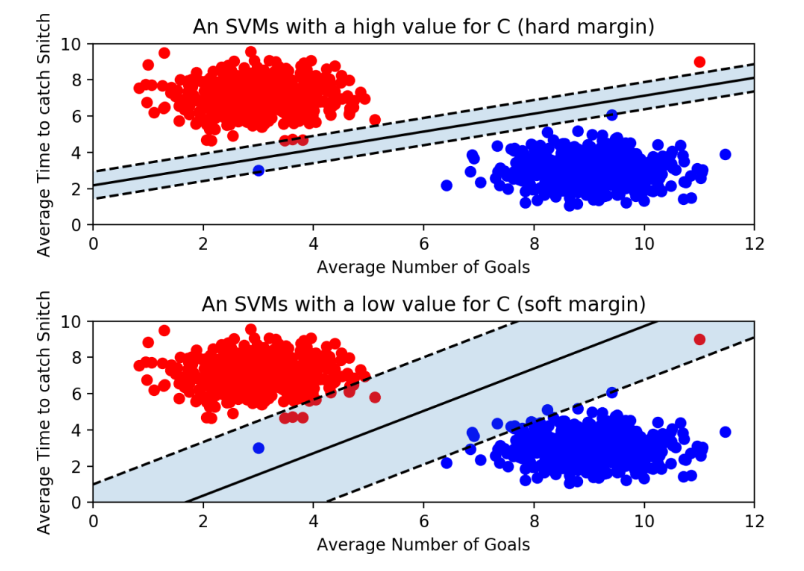
Outlier detection
hard margin SVM의 경우 outlier를 1개도 허용하지 않는다는 점에서 오버피팅의 문제가 발생할 수 있고, soft margin SVM의 경우 error를 일부 허용한다는 부분에서 hard margin에 비해 마진은 커질 수 있으나, 어쩌면 언더피팅의 문제가 발생할 수도 있다.
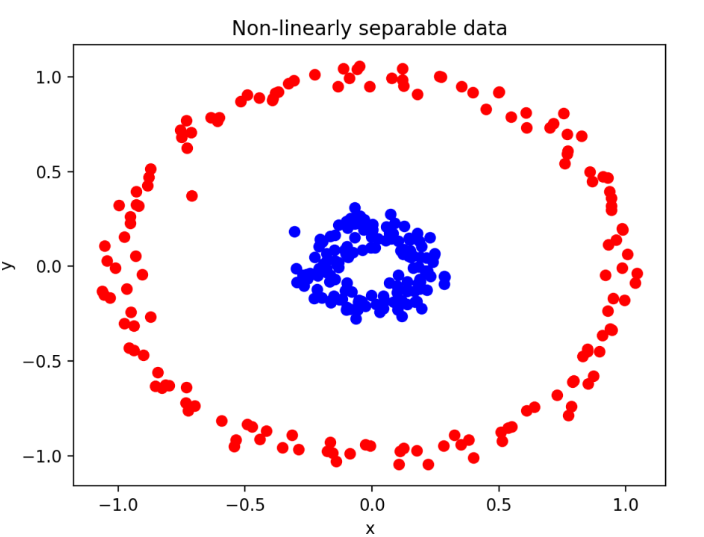
nonlinear - SVM
위 그림과 같이 단순 선형 분류가 아닌 비선형으로 분류를 해야하는 경우도 있다.
SVM에서는 선형으로 분류할 수 없는 경우 kernel trick을 이용하여 문제를 비선형으로 해결한다.
이 경우 현재 주어진 차원보다 이를 늘려 표현하는 방법이 2가지 존재한다.1 ) Polynomial Kernelized SVM
kernel trick을 이용하여 현재의 데이터가 주어진 차원에서 더 높은 차원으로 변형(확장)하여 나타냄으로써 hyperplane을 얻을 수 있다.
2 ) Gaussian RBF
가우시안 커널로 불리며, 현재 데이터가 주어진 차원을 무한대로 확장하여 hyperplane을 얻는 과정
hyperparameter
SVM 모델을 실제 Python 코드로 구현하는 과정에서 모델 구축에 있어 하이퍼파라미터로 C와 gamma가 사용된다.
C는 SVM 모델이 오류를 어느정도 허용할 것인지를 결정하는 hyperparameter
- C값이 클수록 하드마진, less violation & less regularized, narrower street, slack_variable 낮음을 의미.
- C값이 작을수록 소프트마진, wider street, more violation, more regularized를 의미.
gamma는 hyperplane을 얼마나 유연하게 그을 것인지 결정하는 hyperparameter. 즉 train data에 얼마나 민감하게 반응하는지를 결정!!
- gamma가 클수록 train data에 많이 의존하게 되어 hyperplane이 비선형에 가깝게 되어 오버피팅을 초래할 수 있다.
- gamma가 작을수록 train data에 별로 의존하지 않으므로 hyperplane이 직선에 가깝게 되고 언더피팅을 초래할 수 있다.
