
빅데이터 처리 기술인 hadoop에 대해 학습하기전, 빅데이터에 대해 간략하게 알아보자.
(이미 알고 있지만 정리)
- 빅데이터를 처리하고자 hadoop open source 등장
- 분산 파일 시스템 (HDFS) 분산 컴퓨팅 시스템 (map reduce, YARN)으로 구성
- map reduce programming의 제약성으로 인해 SQL 재등장
- spark는 대용량 데이터 분산 컴퓨팅 기술 (pandas + scikit learn)
- spark는 이외에도 실시간 데이터 처리(stream data), 그래프 처리도 제공
✍️ 빅데이터 정의
- 서버 한대로 처리할 수 없는 규모의 데이터
- 기존 SW(oracle, MySQL과 같은 RDBM)로는 처리할 수 없는 규모의 데이터
- 4V (Volume, Velocity, Variety, Varecity)
- 예시로는 웹 페이지, device data (IoT, networking device 등이 존재)
✍️ 빅데이터 처리
- 빅데이터를 손실없이 보관할 방법이 필요 : storage
-> 큰 데이터 저장이 가능한 분산 파일 시스템 필요 - 병렬처리 (처리 시간 오래걸리므로 직렬 X), 로그 파일 등 비구조화된 데이터 -> SQL만으로 부족
-> 병렬처리 및 비구조화 데이터를 처리할 방법 필요결국 다수의 컴퓨터로 구성된 Framework이 필요
✍️ 대용량 분산 시스템?
- 분산 환경 기반
- Fault Tolerance (소수 서버 고장에도 이상 X)
- 확장이 용이한 scale-out이 되어야 함.
✅ Hadoop
- 다수의 노드로 구성된 클러스터 시스템 (다수의 컴퓨터들이 복잡한 SW로 통제됌)
- 분산 파일 시스템 (HDFS), 분산 컴퓨팅 시스템 (MapReduce)로 구성된 오픈 소스 플랫폼
-> HDFS 위에 MapReduce라는 분산 컴퓨팅 시스템이 도는 구조 (1.0)- 2.0 부터 아키텍처가 크게 변경. (YARN이란 이름의 분산 처리 시스템 위에서 동작)
🎈 HDFS
- 데이터를 블록단위로 나누어 저장 (128MB)
- 블록 복제 방식 (Replication) - (각 블록은 3군데에 중복 저장, Fault tolerance 보장)
- 하둡 2.0 네임노드 이중화 지원 (Active & Standby, secondary 네임 노드 존재)
🎈 MapReduce (1.0)
- 하나의 잡 트래커와 다수의 트래커로 구성된다.
- 잡 트래커가 일을 나누어 다수의 트래커에게 분배 후 각 태스크 트래커에서 병렬처리 진행
- MapReduce만 지원하고 제너럴한 시스템 X
🎈 Hadoop 2.0
- 세부 리소스 관리가 가능한 범용 컴퓨터 프레임워크로 spark가 해당 프레임워크 위에서 구현됌.
- 하나의 리소스매니저(Job scheduler, Application manager)밑에 컨테이너/Application 마스터로 구성된 여러 노드매니저가 존재.
- YARN : 클러스터 자원 관리자
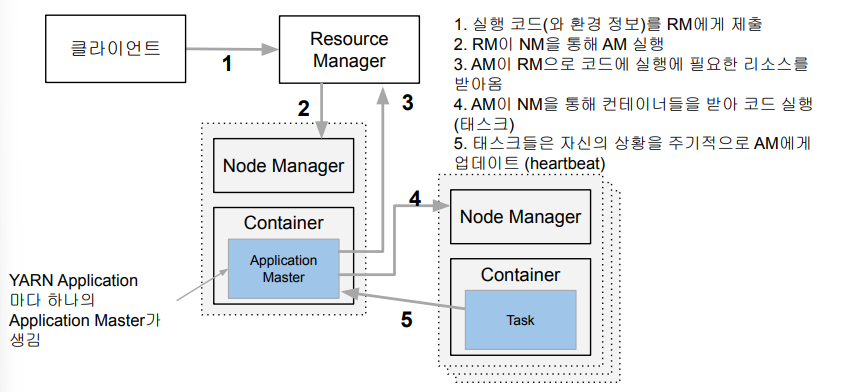
🎈 YARN 동작
- 실행하려는 코드와 환경정보를 RM(리소스 매니저)에게 전달 (실행에 필요한 파일들은 Application ID에 해당하는 HDFS 폴더에 미리 복사됌)
- RM은 NM(노드 매니저)으로부터 컨테이너를 받아 AM(application manager) 실행 (AM은 프로그램마다 하나씩 할당되는 프로그램 마스터에 해당)
- AM은 입력 데이터 처리에 필요한 리소스를 RM에게 요구 (RM은 data locality 고려해 컨테이너 할당)
- AM은 할당받은 리소스를 NM을 통해 컨테이너로 론치하고 그 안에서 코드 실행 (실행에 필요한 파일들이 HDFS에서 컨테이너가 있는 서버로 먼저 복사)
- 각 태스크는 상황을 주기적으로 AM에게 보고
🎈 Map Reduce Programming
- 데이터 셋은 key, value의 집합, Immutable 형태
- 데이터 조작은 map, reduce 2개의 operation으로만 가능 (셔플링 - map 결과를 reduce단으로 모아줌)
- Map : (k,v) -> [(k', v')*] (입력은 시스템에 의해 주어지고 입력으로 지정된 HDFS 파일에서 넘어오고 새로운 key, value 페어 리스트로 변환, 출력은 입력과 동일한 키)
- Reduce : (k', [v1', v2', v3', v4'] -> (k'', v'') (SQL의 GROUP BY와 유사, 출력이 HDFS에 저장)
결과적으로, 작동 순서는 다음과 같다.
- HDFS 파일에서 각 파일 별로 map task가 1개씩 할당 (파일 블록 크기에 따라 다르긴 함)
- 블록 수만큼 생성된 mapper에서 개발자가 작성된 코드에 따라 입력이 리스트 형태인 key, value 페어로 변하고 shuffling 후 sorting(모든 mapper 출력을 key별 정렬)되어 reducer로 보내줌
-> shuffling : mapper 출력을 reducer로 보내는 과정, 데이터 크기 크면 vottleneck 발생가능
-> sorting : 다수의 mapper의 출력을 reducer가 받으면 이를 key별 정렬하여 한 리스트로 저장-> 해당 개념은 spark 작업을 위해 반드시 이해하고 넘어가야 함
- ❗ 만일 각 태스크가 처리하는 데이터 크기가 상이한 경우?
병렬처리는 크게 의미가 없고, 가장 느린 태스크가 전체 처리 속도를 결정하므로 data skew 문제를 처리할 필요성 존재.
- ❗ 문제점.
- 낮은 생산성 (튜닝/최적화 - skew문제)
- batch 작업 중심 (low latency가 아닌 Throughput에 초점이 맞춰졌기에)
- shuffling 후 data skew 발생 쉬움. (reduce task 수 지정 必)
-> 대안 : Hive, Presto, YARN, Spark 등

✅ Hadoop 설치 데모
- 하둡 3.0을 의사분산 모드(Hadoop 관련 프로세스들 개별 JVM으로 실행)로 리눅스 서버에 설치 - AWS EC2 t2.mediu 인스턴스 사용 (java 8 필요), pem 파일 다운로드 필요
- ssh로 spark-dev.pem 계정@ec2-서버 .amazonaws.com 이동
- java 설치 (java -version으로 확인)
(sudo apt update, sudo-apt install openjdk-8-jre-headless)- sudo adduser hdoop으로 하둡 클러스터 동작할 전용 계정 생성
- su - hdoop으로 pwd 입력해 스위칭 후 ssh keygen으로 키 생성
- ssh localhost로 pwd없이 로그인 되는 지 체킹
- wget 명령어로 hadoop-3.3.4 download, tar 명령어로 다운받은 하둡 home-local에 설치
- HDFS 포맷 처리(initialize) 후 sh 이동 후 YARN 실행
✅ spark
하둡에 이어 2세대 빅데이터 처리 기술로 YARN 등을 분산환경으로 사용하며 scala로 작성된다.
(apache-spark 라이브러리로 다양한 빅데이터 처리 기능 보유)
spark 3.0은 다음으로 구성
-> sparrk core, spark sql, ML, streaming, GraphX 등map reduce와의 차이
- spark은 map reduce(디스크 기반)와 달리 메모리 기반.
- map reduce는 하둡(YARN)위에서만 동작하지만 spark는 여러 분산 컴퓨팅 환경 지원(k8s, mesos)
- spark는 df와 개념적으로 동일한 데이터 구조 지원 가능하고 다양한 방식의 컴퓨팅 기능 지원
🎈 spark programming API
- RDD : 로우레벨 프로그래밍 API로 세밀 제어 가능하지만 코드 복잡도가 높음.
- DF & Dataset : 하이레벨 프로그래밍 API, 구조화 데이터 조작은 spark SQL 사용. (보통 ML 엔지니어링 시 사용)
🎈 spark SQL
- 구조화된 데이터 처리 시 사용하며 DF를 테이블처럼 SQL로 처리
- Hive query보다 최대 100배 빠른 성능 보장. (Hive도 최근 메모리 사용)
🎈 spark ML
- ML 관련 다양한 알고리즘 ,유틸리티로 구성된 라이브러리로 clustering, regression, filtering 등 존재.
- RDD 기반(spark.mllib)과 DF 기반(spark.ml) 중 spark.ml만 사용
- ML관련 다양한 기능 한 곳에서 처리 가능하고, 크기가 큰 훈련데이터도 처리 가능!
-> spark는 기본적으로 대용량 데이터 배치처리(ETL, ELT), stream 처리, model building 등에 사용된다.
✍️ spark 프로그램 실행 환경
- 주로 노트북 (주피터, 제플린), spark shell 에서 실행 (개발/테스트/학습 환경)
- 프로덕션 환경은 주로 spark-submit에서 가장 많이 사용되며 REST API에서도 사용하곤 함.
프로그램 구조는 master - slave 구조로 다음과 같다.
- Driver : 코드의 마스터 역할 수행 (YARN - application master), 보통 sparkcontext 만들어 spark cluster와 통신 수행
- Executor : 태스크 실행하는 역할 수행 - JVM (YARN - container)
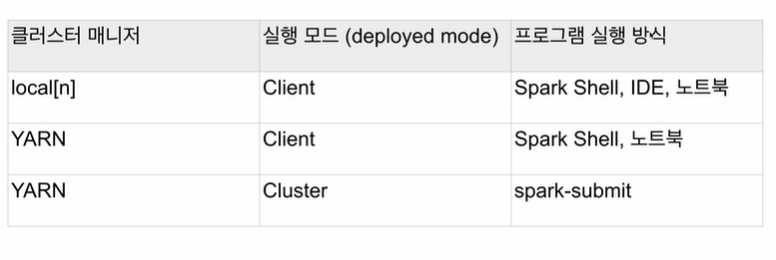
🎈 spark cluster manager options
- local[n] : n은 executor 수
- YARN : client(driver가 클러스터 밖에서 동작)와 cluster(driver가 클러스터 내에서 동작)로 2개 실행 모드 존재

To be a DataScientist