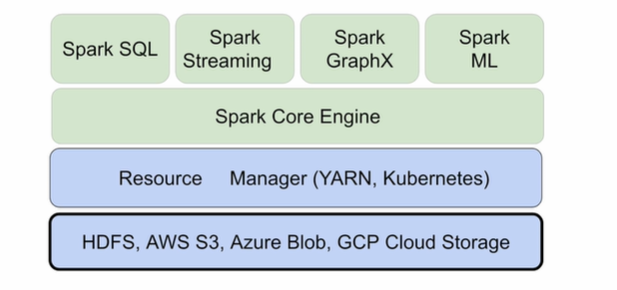
✅ spark data system architecture
하나의 system (spark)으로 다양한 처리 기능 지원 가능!
외부 데이터(RDB) 등을 연동하는 방법은 2가지가 존재한다.
1. 주기적인 ETL로 Core Engine에 적재 후 내부데이터로 전환한 다음 다양한 기능 처리
2. 필요한 타이밍에 따라 바로 처리(batch, spark sql 등)하여 core engine에 적재해 처리🎈 데이터 병렬처리가 가능하려면?
- 데이터가 먼저 분산되어야 함. (spark에서는 파티션이라 부르며 기본 크기는 블록과 동일한 128MB) - spark.sql.files.maxPartitionBytes: HDFS 등에 있는 파일 읽을 때만 적용
- 다음으로 나눠진 데이터를 각각 따로 동시 처리
-> 맵리듀스에서 N개의 데이터 블록으로 구성된 파일 처리 시 N개의 Map 태스크 실행되고 spark에서는 파티션 단위로 메모리로 로드되어 executor 배정.처리하려는 데이터 파일을 파티셔닝 하되 JDBC 소스 내 파라미터를 수정해 여러 개의 파티션 생성필요.
(이때 파티션이란 데이터가 physical하게 분리되어 있는 것을 의미!, 적절한 파티션 수는 executor 수 * executor 당 cpu 개수)spark와 pandas DF와의 가장 큰 차이는 크기이다. spark는 DF를 작은 파티션으로 나누어 구성하고 원하는 결과 도출까지 계속해서 DF를 변환하는 작업을 진행한다. 그렇다면, 파티션 간 데이터 이동없이 계속 변환이 가능한가?
-> 셔플링 : 파티션 간 데이터 이동이 필요한 경우 발생하고 셔플링이 발생할 때 네트웍을 타고 데이터가 이동하게 되며 spark.sql.shuffle.partitions로 파티션 수가 결정된다. 그러나 이때 역시, 데이터 불균형 문제가 발생할 수 있어 skew 문제 해결이 필요하다.data skewness를 해결하기 위해선 셔플링을 최소화하는 것이 중요하고 파티션 최적화가 가장 중요하다.
셔플링 방법은 다음과 같다.
1. hashing partition
-> 입력 데이터를 aggregation 오퍼레이션을 통해 각 해시 값을 기준으로 partition 구분
✅ spark data structure
총 3가지가 있는데, 하나씩 살펴보자.
- RDD
- 모두 파티션으로 나뉘며 Immutable 분산 저장된 데이터, 로우레벨 데이터이며 생산성이 가장 떨어짐. 로우레벨의 함수형 변환(map, filter, flatMap 등 지원)
- 구조화된 데이터, 비구조화된 데이터 모두 지원하지만 스키마가 존재 X
- 파이썬 데이터를 parallelize 함수로 RDD 변환, 반대는 collect로 변환
- DataFrame
- 파이썬으로 코딩하는 경우 사용, RDD보다 조금 더 구조화 (레코드에 필드가 존재)
- PySpark는 해당 DF 사용, RDD와 다르게 RDB 테이블처럼 컬럼으로 나누어 저장.
- Dataset
- scala, java 코딩 시 사용, 타입이 지정되어 compile 언어에서도 사용 가능
✅ spark program structure
- spark 프로그램의 시작은 SparkSession을 만드는 것. 프로그램마다 session을 하나 만들어 spark cluster와 통신.
- spark session을 통해 DF, SQL, Streaming, ML API 모두 객체로 통신 가능하며 config 메소드 이용해 다양한 환경설정 가능.
- 단 RDD 관련 작업 시 Session 밑의 sparkContext 객체 사용 必
- SparkSession은 pyspark.sql 라이브러리 밑에서 호출
- SparkSession 생성 시 다양한 환경설정 가능 (executor 별 메모리, cpu 수, driver 메모리, shuffle 후 partition 수 등.) - 사용하는 RM에 따라 환경변수가 많이 다름
- 환경변수 설정 방법 4개 ($SPARK_HOME/conf/spark_defaults.conf, spark-submit 명령의 커맨드라인 파라미터, SparkSession 생성 시 지정, 코드로는 Sparkconf 라이브러리 호출 후 config로 사용)
전체적인 flow는 다음과 같다.
1. SparkSession 생성
2. 입력 데이터 로딩
3. 데이터 조작 작업 (pandas와 유사) DF를 원하는 형태로 계속해서 DF API, Spark SQL 사용해 변환하여 df 생성
4. 최종 결과 HDFS, RDBMS, Hive 등으로 저장
✅ colab에서 PySpark 사용하기
- 설치 - local standalone spark
-> !pip install pyspark==3.3.1 py4j==0.10.9.5- 아래코드로 spark 변수 지정
from pyspark.sql import SparkSession # Spark에게 명령을 내리는 엔드포인트 session을 통해 객체와 통신 진행 spark = SparkSession.builder\ .master("local[*]")\ .appName('PySpark Tutorial')\ .getOrCreate() # single턴 (여러 개 생성)
- spark 변수, !lscpu로 설정 확인
- 아래 colab에서 실습진행!
spark 실습
-> spark SQL로 빅데이터 DataFrame을 다룰 수 있을 뿐만 아니라, 판다스 라이브러리는 물론, 쿼리를 활용해 구조화된 데이터에 한해 더 다양한 처리 가능!