
기존 학습했던 spark의 기타 기능에 대해 알아보고자 한다.
✅ sparkml
- Broadcast Variable : 룩업 테이블등을 broadcast해 셔플링을 막는 방식. (대부분 DB에서 스타 스키마 형태로 fact table과 dimension table로 분리)
-> JOIN을 하기엔 데이터가 커서 힘들고, udf를 사용해야 한다면 해당 variable 사용하는 것이 best practice.
-> 룩업 테이블 자체를 udf로 broadcasting 하면서 셔플링 하지 않고 특정 엔티티만 룩업.
-> 결국 JOIN과 동일한 테크닉🎈 broadcast (serialization이 worker node단위로 발생)dataset 특징
- worker node로 공유되는 변경 불가 데이터
- worker node별로 한번 공유되고 캐싱됨.
- 제약점은 task memory안에 들어갈 수 있어야 함.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
def my_func(code: str) -> str:
# return prdCode.get(code)
return bdData.value.get(code)
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Demo") \
# cluster : 3
.master("local[3]") \
.getOrCreate()
prdCode = spark.read.csv("data/lookup.csv").rdd.collectAsMap()
bdData = spark.sparkContext.broadcast(prdCode)
data_list = [("98312", "2021-01-01", "1200", "01"),
("01056", "2021-01-02", "2345", "01"),
("98312", "2021-02-03", "1200", "02"),
("01056", "2021-02-04", "2345", "02"),
("02845", "2021-02-05", "9812", "02")]
# Spark로 df 생성
df = spark.createDataFrame(data_list) \
.toDF("code", "order_date", "price", "qty")
# UDF로 등록
spark.udf.register("my_udf", my_func, StringType())
df.withColumn("Product", expr("my_udf(code)")) \
.show()🎈 Accumulators
- spark 전용 전역변수 (특정 이벤트 수 기록, 레코드 별 합산에 사용) - hadoop counter와 흡사
- 스칼라로 만들면 이름을 줄 수 있지만 그 외는 불가.
- 두 가지 방법으로 사용 가능하며 값의 정확도도 다름 (transformation에서 사용, df/rdd foreach에서 사용.)
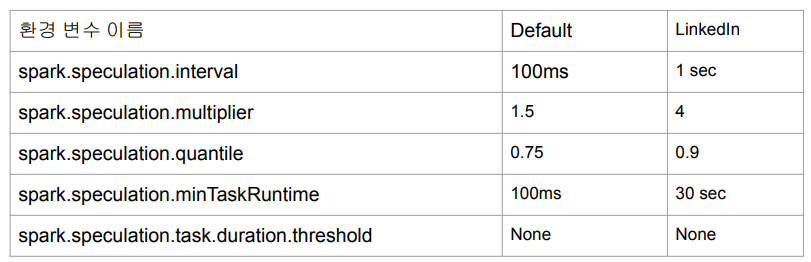
🎈 Speculative Execution
느린 태스크를 다른 worker node에 있는 executor에서 중복 실행
-> 이를 통해 worker node의 하드웨어 이슈 등으로 느려지는 경우 빠른 실행 보장
-> 하지만 data skew문제로 인해 오래 걸릴 수 있고 리소스만 낭비할 수 있음.
아래 환경변수로 제어 가능.
spark 리소스 할당 (스케줄링)
- spark application들 간의 리소스 할당 (YARN : FIFO, FAIR, CAPACITY)
- 한번 리소스 할당 시 해당 리소스를 끝까지 들고 가는 것이 기본 (리소스 사용률에 악영향 가능성 높음)
-> dynamic allocation : spark application이 상황에 따라 유동적으로 executor를 릴리스, 요구
-> 다수의 spark application들이 하나의 리소스 매니저를 공유하면 활성화하는 것이 좋음리소스 할당 방식은 spark scheduler의 일종.
- 1) FIFO : 리소스를 처음 요청한 Job에게 리소스 우선 순위가 감.
- 2) FAIR : 라운드로빈 방식으로 고르게 리소스 분배
병렬성 증대로 인해 Thread 활용이 필요하고 (Scheduler가 FAIR모드인 경우 더 효과적이다.)
✅ Driver
SPARK APPLICATION : 하나의 Driver와 하나 이상의 Executor로 구성
- main 함수를 실행하고 sparksession/sparkcontext를 생성
- 코드를 태스크로 변환하여 DAG 생성
- 이를 execution/logical/physical plan으로 변환
- 리소스 매니저의 도움을 받아 태스크를 실행하고 관리 (task 수 많아지면 driver 메모리 에러 발생)
- 위 정보를 web UI로 노출
# Driver 메모리 구성
# JVM 메모리 용량 지정, default는 1GB
spark.driver.memory = 4GB
# core 수 지정 (CPU 수, default는 1)
spark.driver.cores = 4
# 이외의 JVM 외부 메모리 지정 (최소 크기는 384MB)
spark.driver.memoryOverhead = 0.1 (spark.driver.memory의 10%)
# Executor 메모리 구성
# JVM 메모리 용량, CPU 수 지정
spark.executor.memory = 8GB
spark.executor.cores = 4
# 외부메모리 지정
spark.executor.memoryOverhead = 0.1
# yarn
yarn.nodemanager.resoure.memory-mb
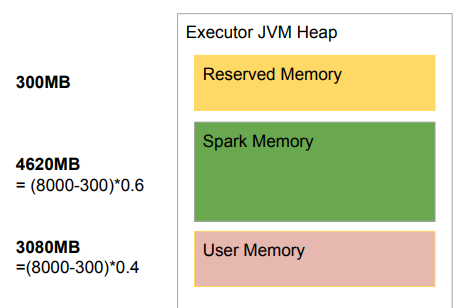
USER Memory : 기본적으로 40% 할당, 다음 용도로 사용 (자신이 만든 data structure가 존재, UDF 사용, RDD 바로 조작하는 경우)
-> USER MEMORY 사용할 일이 별로 없다면 spark.memory.fraction을 증가시키는 것이 더 나음.SPARK MEMORY : df operation, df caching으로 나뉘어 사용 (storage memory pool : 캐싱에 사용 / executor memory pool : operation일어날때 사용, FAIR 모드로 실행 중인 태스크가 모든 메모리 가져가는 구조)
RESERVED MEMORY : spark engine 전용 메모리 (수정 X)
Executor가 메모리를 관리하는 방법
-> unified memory manager를 사용해 동작중인 태스크를 대상으로 FAIR로 스케줄 동작. (실행중인 태스크가 모든 메모리를 가져감)
-> Executor 메모리가 부족해지면 storage에 남은 메모리를 사용하고, 그래도 더 이상 남는 메모리가 없다면, 데이터를 메모리에서 디스크로 옮김 (해당 작업을 spill이라 부름)
-> 결국 executor에 할당되는 메모리는 spark.executor.memoryOverhead + spark.executor.memory + spark.memory.offHeap.size + spark.executor.pyspark.memory(python 프로세스) + (spark.python.worker.memory - Py4J)로 구성.off heap memory의 경우 spark.executor.memoryOverhead + spark.offHeap.size로 크기 구성.
✅ Memory Issue
기본적으로 메모리 이슈는 버그와 연관성이 높다. 로직상 에러, pyspark 개발의 경우 type, 메모리 용량 초과 등이 있을 수 있다. 대개 java heap space error가 태반.
🎈 driver oom
- 큰 데이터셋에 collect를 실행하는 경우 (spark df가 driver쪽으로 download)
- 큰 데이터셋을 broadcast JOIN (driver에 fit이 안되는 경우)
- python이나 R 등으로 작성된 코드 (typing error)
- 너무 많은 태스크 존재하는 경우. (overhead 발생)
🎈 executor oom
- 너무 큰 executor.cores 값 (High concurrency)
- Data skew (Big 파티션)
pyspark 사용 시 driver program은 python이지만, JVM으로 작성이 됀 Spark cluster와 통신을 해야하고 그 과정에서 sparksession을 만들 때 spark context(JVM)도 생성된다. 따라서 driver program은 spark context(JVM)와 Py4J를 통해 driver로 전달하는 방식이다.
즉 Py4J(JVM과의 통신 프레임워크)라는 파이썬 라이브러리를 통해 다음 2가지 통신이 이루어진다.
- Driver program <-> Spark context (JVM)
- Executor(JVM) <-> Python
한번 정리를 하면 다음과 같다. Spark의 경우 JVM Application이지만, Pyspark은 Python 프로세스이기에 JVM에서 바로 동작하지 못하고 Py4J가 Serialize, Deserialize 역할을 해 통신을 진행한다.
pyspark은 기본으로 Overhead.memory를 사용하고 이 환경변수가 사용되면 pyspark가 사용할 수 있는 메모리는 해당 환경변수 값으로 고정.
spark.python.worker.memory의 디폴트 크기는 512MB로, JVM과 파이썬 프로세스 간 통신을 하는 Py4J가 사용할 수 있는 메모리 양을 의미한다. 해당 512MB를 넘기면 Spill발생.Py4J 통신 절차는 다음과 같다.
1. 드라이버 위의 파이썬 프로세스에서 실행할 코드, 기타 데이터를 Serialize해 Executor에게 전송
2. JVM Executor는 파이썬 프로세스를 실행 (pyspark script)
3. executor는 파티션을 serialize하고 2에서 받은 코드와 함께 파이썬 프로세스로 전송
4. 파이썬 프로세스에서 계산이 끝나면 결과가 다시 executor로 serialize되어 전송.
✨ caching
- caching 기본 개념
자주 사용되는 df의 메모리를 유지해 처리속도를 증가시킨 방법이다.
단, df가 메모리 위에 있는지를 반드시 확인해야 하고 메모리 크기가 늘어나는 것을 방지하기 위해 모든 것을 캐싱할 필요는 없다.
- df를 caching 하는 방법
-> cache(), persist() 2가지 방법으로 df를 메모리/디스크/offheap에 보존하는 방법, 모두 lazy execution 기법으로 필요해질 때까지 캐싱하지 않는다. caching은 항상 파티션 단위로 메모리에 보존한다. (한 개의 파티션 내 partial caching X)
-> persist는 기본적으로 caching 되는 df를 메모리와 디스크에 보관 후 복제도 수행🎈spark sql 활용 caching
-> spark.sql("cache table table_name") : 캐싱처리
-> spark.sql("cache lazy table table_name") : 필요해질 때까지 캐싱 대기, 필요한 순간 캐싱해 메모리에 올라감
-> spark.sql("uncache table table_name") : 캐싱 필요 X
- caching 취소 방법
-> DataFrame.unpersist(LRU - Least Recently Used)
-> spark.sql("uncache table table_name")
-> spark.catalog.isCached("table_name") : 어떤 테이블이 캐싱?
-> spark.catalog.clearCache() : 사용중인 모든 캐시 취소
- caching best practice
-> 캐싱된 df 재사용 분명히 할 것.
-> 컬럼 많은 경우 정말 필요한 컬럼만 캐싱
-> 불필요한 경우 uncaching 필요.
-> 때론 매번 새로 df계산하는것이 캐싱보다 빠를 수 있음. (소수 df만 캐싱, 큰 df는 캐싱 X)
