
✅ dynamic partition
🎈 partition pruning
Logical plan optimizaiton 단계에서 발생하는 최적화 방식의 일종으로 optimizer가 필요한 데이터, 불필요한 데이터를 구별해 읽는 것을 의미한다.
static partition pruning이란 데이터소스가 필터링 컬럼을 중심으로 파티셔닝되어 있는 경우를 의미한다.
-> 큰 fact테이블과 dimension테이블 조인 시 필터링(where 절)이 dimension테이블에 적용되어 있다면 문제가 될 수 있다. (파티션닝은 보통 fact테이블에 적용되어 있으므로)이때 등장한 것이 dynamic partition pruning
: 비 파티션 (FACT)테이블에 적용된 필터링을 파티션 테이블에 적용해보는 것으로 후자가 작은 dimension 테이블인 경우 broadcast JOIN까지 진행한다면 최적화 효과를 극대화할 수 있다.
✅ repartition
- 전체적으로 파티션 수를 늘려 병렬성을 증가시켜 처리속도 빠르게 하기 위해 사용
- 굉장히 큰 파티션이나 skew문제 해결위해 파티션 크기를 조절하고자 사용
-> 파티션을 분석 패턴에 맞게 재분배 (write once, read many)repartition은 2가지 방식이 존재하고 셔플링이 무조건 발생하기에 반드시 사용하는데 분명한 이유가 있어야 한다.
-> 컬럼이 사용된다면 균등한 파티션 크기를 보장할 수 없고 파티션 수를 줄이는 용도로 사용할 수 없다. (파티션 수를 줄이는 것이 목표라면 coalesce 사용)-> coalesce는 파티션 수를 줄이는 용도로써 셔플링이 발생하지 않아 skew 파티션을 만들 수 있음. 또한 column이 사용되어 균등한 파티션 크기 보장 X
- repartition(numpartitions, *cols) : hash 기반 파티셔닝
- repartitionByRange(numPartitions, *cols) : 지정된 컬럼 값 범위 기준 파티션 진행, 데이터 샘플링 기반으로 나누기에 결과가 매번 다름
🎈 dataframe partitioning 관련 힌트
- COALESCE : 파티션 수 줄이기
- REPARTITION
- REPARTITION_BY_RANGE
- REBALANCE : DF를 테이블로 저장할 때 유용한 방법으로 AQE 필요 (파일 크기 최대한 비슷하게 만들어 저장)
🎈 DF JOIN 관련 힌트
- BROADCAST, BROADCASTJOIN, MAPJOIN : 작은 DF를 큰 DF가 있는 파티션들로 통째로 보내 셔플링 없이 조인
- MERGE, SHEFFLE_MERGE, MERGEJOIN : Spark 기본 조인
- SHUFFLE_HASH : full outer join에는 사용 X, 셔플링을 피하고자 BROADCAST JOIN과 유사
- SHUFFLE_REPLICATE_NL : cross joi과 유사 (잘못 사용 시 performance impact 매우 큼)
-> 아래로 내려갈수록 우선순위 낮음✍️ AQE란?
- spark.sql.shuffle.partitions 변수 하나로 다양한 상황의 셔플링 해결 X
- 적은 수의 파티션은 병렬성을 낮추고 oom, spill 가능성 높임
- 많은 수의 파티션은 task scheduler와 task 생성 관련 오버헤드, 네트웍 I/O요청으로 병목 초래
-> AQE의 목적은 spark engine optimzer가 알아서 파티션 수를 결정하기 위함.앞선 이슈를 해결하기 위해선 parsing time 최적화와 runtime 최적화를 병행하는 것이 기본적인 아이디어이다. -> UDF가 많이 사용되면 문제가 오히려 더 심각해질 수 있음.
AQE : dynamic query optimization that happens in the middle of query execution based on runtime statistics.
-> 쿼리 중간에 실시간, dynamic이 핵심
-> 중간 stage를 추가해 셔플링, 브로드캐스팅이 job을 stage들로 나누어 작업 실행.AQE 사용가능한 시나리오
1. 셔플링 후 파티션 수를 동적으로 조정 (내부적으로 파티션을 일부러 많이 생성한 후 줄여나감)
2. JOIN 방법 변경
3. Skew된 JOIN 시 최적화 진행AQE 동작 방식은 다음과 같다.
1. Stage DAG를 순차적으로 실행
2. 매번 새로운 최적화 기회가 있는지 조사하여 필요 시 다시 실행 또는 쿼리 플랜 변경
앞서 AQE가 사용가능한 시나리오 2번을 자세히 설명하겠다.
앞선 2번의 경우 Dynamically switching join strategies를 의미하며 해당 전략은 static query plan이 브로드캐스트 해시 조인 기회를 놓친 경우에 필요하다. (JOIN 대상에 대한 통계정보가 부족하거나 UDF가 사용된 경우)동작 방식은 다음과 같다.
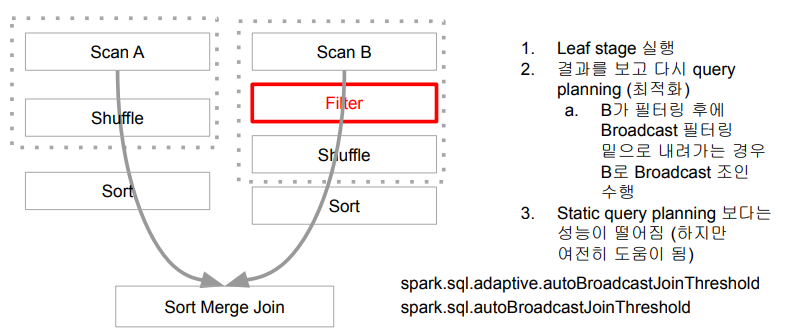
AQE의 해법으로는 다음과 같다.
- Runtime 통계정보를 바탕으로 조인 전략 변경 (stage 끝나고 조인 전에 쿼리플래닝 수행)
- BROADCAST JOIN, Shuffle Hash Join 2가지 옵션으로 위 조인 전략 변경 수행

정보 감사합니다.