
오늘부터 실제 사용해볼 AWS Redshift에 대해 학습하고자 한다.
우선, Redshift의 특징에 대해 살펴보자
✅ Redshift
- AWS에서 지원하는 DW 서비스
- 2 PB 데이터까지 처리 가능, 최소 160GB부터 시작
- OLAP (volume이 큰 데이터 처리에 용이)
- 컬럼 기반 스토리지
- 벌크 업데이트 지원 (레코드 들어있는 파일 S3로 복사 후 COPY 커맨드로 일괄 복사 진행)
- 고정 용량/비용 SQL 엔진
- Datashare 기능 (타 AWS계정과 특정 데이터 공유 가능 - Snowflake 기능)
- 타 DW처럼 Primary key Uniqueness 보장 X. (Production DB만 보장)
- Postgresql 8.x와 SQL이 호환되지만 모든 기능 지원 X
🎈 Scaling method
- 용량이 부족해질 때마다 새로운 노드를 추가하는 방식으로 scaling
- scale out : 동일 서버 추가 / scale up : 용량 업그레이드
- 이는 snowflake나 Bigquery와 굉장히 다름 (snowflake, Bigquery가 훨씬 더 큰 범위임)
- 가변비용 옵션 존재. (Redshift Serverless)
❗ 최적화 복잡
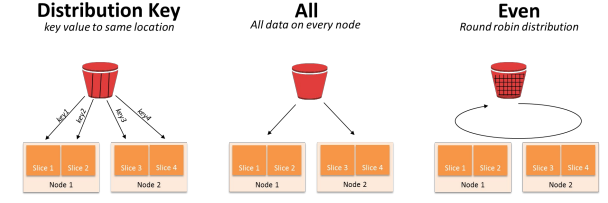
Redshift가 2대 이상의 노드로 구성된다면, 한 테이블의 레코드들은 분산저장 되어야 하며, 한 노드 내에서는 순서가 정해져야 한다.
-> 이를 해결하지 못한다면 Data secure문제 발생 가능 높음.🎈 레코드 분배 & 저장 방식
- Diststyle : 레코드 분배가 어떻게 이뤄지는지 결정 (all, key, 디폴트는 even)
- Distkey : 레코드가 어떤 컬럼을 기준으로 배포되는지 나타냄. (기준되는 컬럼 지정, Diststyle : key인 case)
- Sortkey : 레코드가 한 노드 내 어떤 컬럼 기준으로 정렬되는지 나타냄. (ex. TimeStamp)
-> 만일, Diststyle이 key인 경우 컬럼 선택을 잘못한다면?
: 레코드 분포에 Skew가 발생 -> 분산처리 효율성이 떨어짐. (Redshift의 문제로, bigquery나 snowflake에서는 자동 선택됌.)
- 테이블에서 Diststyle, Distkey, Sortkey 기준 주는 방법!
CREATE TABLE SAMPLE ( column1 INT, column2 VARCHAR(50), column3 TIMESTAMP, column4 DECIMAL(18,2) ) DISTSTYLE KEY DISTKEY (column1) SORTKEY (column3); -> SAMPLE 테이블의 레코드들은 column1을 기준으로 분배되고 같은 노드 내에서는 column3 기준 정렬❗정리
-> 결국, 특정 컬럼을 기준으로 JOIN, GROUP BY를 많이 진행한다면 해당 키를 DISTKEY로 지정하는 것이 좋으나, Skew발생 여부를 잘 판단하는 것이 핵심.
✅ Bulk Update
앞서, Redshift는 벌크업데이트(레코드 들어있는 파일 S3로 복사 후 COPY 커맨드로 Redshift에 일괄 복사 진행)를 지원한다고 했는데, 방식에 대해 자세히 살펴보면 다음과 같다.
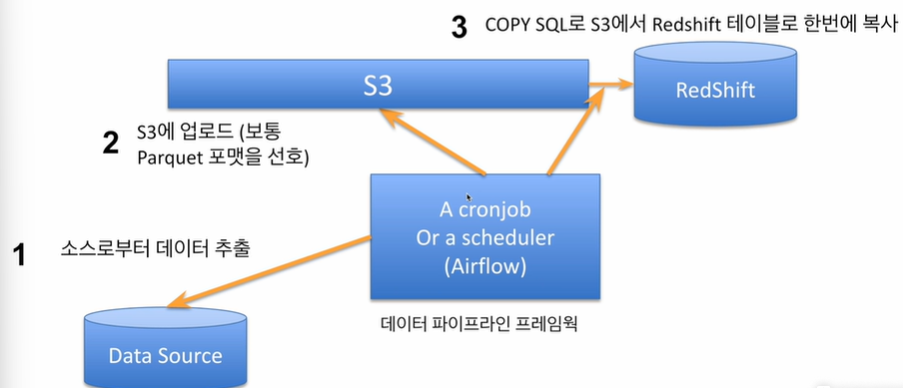
출처 : Programmers
🎈 일반적으로 데이터를 DW에 적재하는 방식
만일, 수많은 레코드를 보유한 데이터를 DW에 적재한다면, Network Transfer이기에 시간이 오래걸린다.
-> 이를 해결하기 위해선, 압축률이 좋은 binary file로 변경 후 클라우드 스토리지(S3)에 업로드 후 Redshift DW에 한 queue에 원하는 테이블로 벌크 업데이트 진행.
✅ Redshift training
snapshot : 백업 느낌. 과거 테이블로 복구 가능, 새로운 redshift cluster launch도 가능
추가로 현 cluster내 데이터가 타 AWS 계정과 공유되었는지도 확인 가능.이후, Google colab과 setup끝난 cluster와 연결
- redshift cluster의 endpoint(host, port number, DB name)알기 : workgroup
- access 가능한 account 생성. (admin 생성 or admin 생성 후 aws 내 IAM 기능으로 별도 account 생성)
- 필요한 정보 : endpoint, account 정보(name, PW)
연결 방법
%load_ext sql !pip install SQLAlchemy==1.4.47 %sql postgresql://account_name:password@endpoint # 위코드 실행 전, # 추가로 외부 연결 시 VPC Group에서 Inbound rules에 포트번호 5439, 0.0.0.0/0 으로 rule add 해주기
✅ Redshift base setting
redshift의 스키마는 타 RDB와 동일한 구조로 이중구조를 가짐.
- DEV라는 DB 밑에 기본 스키마(public)가 존재. (스키마를 이름없이 만든다면 포함됨)
- training에선 4개의 스키마 추가 생성.
(raw_data : ETL 결과 포함. / analytics : ETL 결과 포함. / adhoc : test용 테이블 / pii : 개인정보)
-> 결국, 테이블이 어느 스키마에 있는지만 알아도 유의미한 효율 보일 수 있음.# 모든 스키마 리스트해서 확인 SELECT * FROM pg_namespace; # 스키마 생성 (단, AWS Redshift에 access한 user가 admin 권한을 받아야만 실행 가능) CREATE SCHEMA raw_data; # 모든 사용자 리스트업 SELECT * FROM pg_user; # user 생성 - 추후 사용자별 테이블 access 권한 부여하는 복잡성 존재 -> 그룹 생성 CREATE USER 유저명 PASSWORD '...'; # 그룹 생성 CREATE GROUP; # 그룹에 사용자 추가 ALTER GROUP 그룹이름 ADD USER 유저명; # 모든 그룹 리스트업 SELECT * FROM pg_group; # 모든 역할 리스트업 SELECT * FROM SVV_ROLES; # role 생성 및 유저에게 부여 CREATE ROLE staff; CREATE ROLE manager; GRANT ROLE staff to 유저명; # manager는 staff이 가진 역할 계승 + manager에게 별도 권한 추가 부여 가능 GRANT ROLE staff to ROLE manager;
✅ Using copy-command to load record in Redshift
raw_data 스키마 밑에 3개의 테이블에 레코드 하는 방법
1. CREATE TABLE raw_data.~~ 명령으로 해당 스키마 밑에 테이블 생성
2. 1번 이전에 각 테이블의 입력이 되는 CSV파일을 우선 S3로 복사 (S3 버킷 미리 생성할 것.)
3. Redshift가 S3 access 권한 갖도록 역할 만들고(IAM) cluster에 만든 역할 부여하기(Redshift)
- copy 명령어 예시
COPY raw_data.user_session_channel FROM 's3://keeyong-test-bucket/test_data/user_session_channel.csv' # aws_iam_role값은 각자 Redshift cluster에 지정한 S3 읽기 권한 ROLE의 ARN 지정 credentials 'aws_iam_role=arn:aws:iam:xxxxxxx:role/redshift.read.s3' delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1 removequotes; # copy 도중 에러 발생하면 아래 코드로 확인 SELECT * FROM stl_load_errors ORDER BY starttime DESC # 이후 테이블 생성 - CTAS 문법 (ELT 과정임) CREATE TABLE analytics.mau_summary AS SELECT TO_CHAR(A.ts, 'YYYY-MM') AS month, COUNT(DISTINCT B.userid) AS mau FROM raw_data.session_timestamp A JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid GROUP BY 1 ORDER BY 1 DESC;
