
이번주차는 ETL, ELT 등 데이터 인프라 과정에 대해 학습한다.
그동안 학습한 Web service 구축, DB설계, AWS를 기반으로.
특히 데이터 웨어하우스인 AWS RedShift를 설계하고 구축하는 과정을 주로 진행한다.
데이터 팀의 일원으로서 분석과정, 개인화, 추천화 등의 머신러닝 기법을 활용하기 전, 데이터 인프라를 구축할 줄 알아야 한다.
데이터인프라를 구축하는 ETL(데이터를 가공해 DW에 적재)은 요즘 파이썬으로 작성되며 대표 stack으로는 Airflow가 있다.
이러한 인프라를 구축하는 업무는 Data Engineer가 수행하게 된다.
DW(OLAP)와 Production DB(MySQL, PostgreSQL 등의 OLTP)의 차이는 기존의 학습한 아래 링크를 참고하자.
OLTP VS OLAP
✅ Data Warehouse
데이터 엔지니어가 인프라를 구축해 최종적으로 완성해야 할 최종본을 의미한다.
(최근에는 클라우드...)
즉, 회사에 필요한 모든 데이터를 모아놓은 중앙 DB를 뜻한다.
이때 데이터 크기에 따라 DB 선택하는데, AWS Redshift(고정비용), BigQuery, Snowflake(가변 비용)와 오픈소스 기반인 Hive/Presto/스팍 등이 존재한다.
- ETL 기술을 활용해 DW에 데이터를 적재한다.
그 기술을 다음 3가지로 나뉘는데 Extract(외부 데이터로 부터 추출), Transform(원하는 형태로 처리), Load(변환된 데이터 DW에 적재)
+) 최근에는 ETL 관련 SaaS도 출현하기 시작했고, 흔한 데이터 소스의 경우 FiveTran, Stitch Data와 같은 SaaS를 사용하는 것도 가능하게 되었다.추가적으로, 작년에 인턴을 하면서 채널 별로 대시보드도 종류가 다양했고, 데이터도 인프라가 갖추어있지 않아 상당히 복잡하고 지저분하다는 느낌을 받았는데, 테이블과 대시보드 관련 검색 서비스인 Data Discovery?라는 용어가 존재한다.
즉, 비즈니스 내 존재하는 DB(data catalog : 모든 테이블, 대시보드를 검색 허용하여 모든 데이터 긁어온 DB)를 사람들이 사용하기 쉽게 검색하도록 만들어준 서비스이다.
- 리프트에서 만든 아문센
- 링크드인에서 만든 데이터허브
- 셀렉트스타
✅ Data Lake
RDB 같은 스토리지 처리 시스템이라기 보단, 보존 기한이 없는 Raw data를 저장하는 스토리지에 가깝다.
- 구조화 데이터 + 비구조화 데이터(로그)
- 보통 클라우드 스토리지가 됌. (AWS - S3)
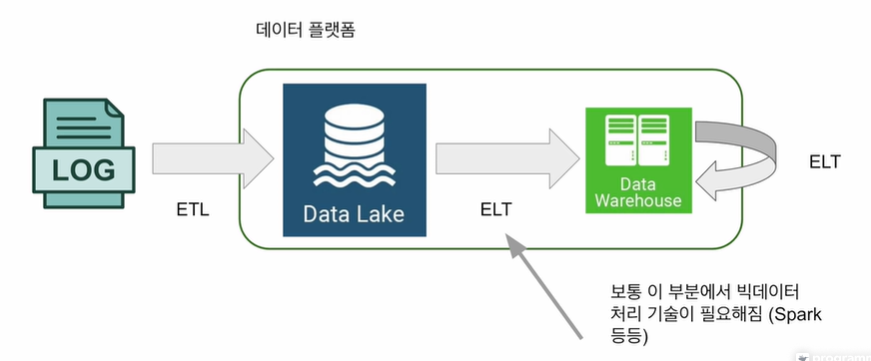
-> Data Lake & DW 바깥에서 안으로 데이터를 가져오는 것 : ETL
-> Data Lake & DW 안에 있는 데이터를 처리하는 것 : ELT
+) 회사 크기가 커짐에 따라 ETL 수도 증가하는데, 데이터 요약을 위한 ETL도 필요하여 이를 ELT라고 부르기도 한다! (ELT 과정에서 빅데이터 처리 기술인 Spark 등이 필요)
✅ Airflow
ETL Schedular로서 다수의 ETL이 존재하는 경우 이를 스케줄링하고 이들 간의 dependency를 정의해주는 기능이 필요해졌고, 특정 ETL이 실패하는 경우 에러메세지를 받아 재실행하는 Backfill 기능도 필요해졌다.
ETL을 위해 가장 많이 사용하는 대표적인 프레임워크가 바로 Airflow로 ETL을 DAG라 부르며 웹 인터페이스를 통한 관리 기능을 제공하며 크게 schedular, webserver, Worker로 구성된다.
+) ELT로는 dbt가 가장 유명하며 주로 데이터 분석가가 이를 수행하기에 Analytics Engineering이라 부른다.
빅데이터 처리 프레임워크는 다음을 따라야 한다.
- 분산 환경 기반 (분산파일시스템, 분산컴퓨팅시스템)
- Fault Tolerance (소수 서버가 고장나도 동작해야 함)
- 확장 용이성 필요 (Scale Out 및 서버 추가)
✅ Data Warehouse Option
DW 종류도 다양하고 프레임워크도 다양한데, 이를 하나씩 살펴보자!
🎈 AWS Redshift
AWS 기반 DW로 PB 스케일 데이터 분산 처리 가능
- PostgreSQL과 호환되는 SQL로 처리 가능
- Python UDF의 작성을 통해 기능 확장 가능
- CSV, JSON, Avro, Parquet 등과 같은 다양한 포맷 지원
- batch 데이터 중심이지만 실시간 데이터 처리 지원
- 웹 콘솔 외에도 API를 통한 관리/제어 가능
🎈 Snowflake
데이터 판매를 통한 매출을 가능케 해주는 Data Sharing/Marketplace 제공
- ETL과 다양한 데이터 통합 기능 제공
- CSV, JSON, Avro, Parquet 등과 같은 다양한 포맷 지원
- batch 데이터 중심이지만 실시간 데이터 처리 지원
- 웹 콘솔 외에도 API를 통한 관리/제어 가능
🎈 Bigquery - Google Cloud
SQL로 데이터 처리 가능(Nested fields - json, repeated fields 지원)
- CSV, JSON, Avro, Parquet 등과 같은 다양한 포맷 지원
- Google Cloud 내 타 서비스와 연동 쉬움 (클라우드 스토리지, 데이터플로우, AutoML 등)
- batch 데이터 중심이지만 실시간 데이터 처리 지원
- 웹 콘솔 외에도 API를 통한 관리/제어 가능
🎈 Apache Hive
Facebook에서 만든 오픈소스 프로젝트로 하둡 기반 동작되는 SQL기반 DW
- HiveQL이라 불리는 SQL 지원
- MapReduce 위에 동작하는 버전, Apache Tez를 실행엔진으로 동작하는 버전 2개로 존재
- CSV, JSON, Avro, Parquet 등과 같은 다양한 포맷 지원
- Batch bigdata processing system (data volume, 데이터 파티셔닝, 버킷팅 등 optimal working 지원)
- 웹 UI, 커맨드라인 UI 2가지 지원
- 점점 Spark에 밀림..
🎈 Apache Presto
Facebook에서 만든 오픈소스 프로젝트로 Hive와 달리 빠른 응답 속도에 좀 더 최적화
AWS Athena가 바로 Presto를 기반으로 만들어졌다.🎈 Apache Iceberg
DW 기술은 아니고 Data File foramt 느낌
- 클라우드 스토리지 위에서 동작, HDFS와 호환
- ACID 트랜잭션과 타임여행
- 스키마 진화 지원을 통해 컬럼 추가 및 제거 기능 제공
- Java, Python API 지원, 타 Apache 시스템과 연동 가능
🎈 Apache Spark
UC Berkeley AMPLab이 시작한 아파치 오픈소스 프로젝트
- 빅데이터 처리 관련 다양한 기능 지원(배치처리 - API/SQL, 실시간처리, 그래프처리, ML)
- 다양한 분산처리 시스템 지원
- 다양한 파일시스템과 연동 가능 (S3, HDFS, Cassandra, HBase 등)
- CSV, JSON, Avro, ORC, Parquet 등과 같은 다양한 포맷 지원
- 다양한 언어 지원 (Java, Python, Scalar, R)
🎇 정리
- 데이터 레이크 (로그 데이터 + 구조화된 데이터로 이루어진 대용량 데이터)를 다루려면 Spark/Hadoop(Hive, Presto)과 같은 빅데이터 분산 처리 기술 필요.
- 이후 회사성장에 따른 데이터양 증가로 인해 ETL 단이 중요해지며 dbt(ELT)등 Analytics Engineering 도입
