
✅ kafka
- 2008년 LinkedIn에서 내부 실시간 데이터 처리를 위해 개발한 SW 플랫폼
- 2011년 오픈소스화 (Apache)
🎈 < 주요 기능 및 특징들은 다음과 같다 >
- 실시간 데이터 처리를 위해 설계된 오픈소스 분산 스트리밍 플랫폼
-> (ksqlDB로 SQL로도 실시간 처리 가능)- Scalability, Fault Tolerance를 제공하는 Publish-Subscription 메세징 시스템
- High Throughput과 Low Latency 실시간 데이터 처리에 맞게 구현
- 분산 아키텍처이기에 Scale-Out 형태 가능
- retention period (대개 일주일) 동안 메세지 저장
- producer, consumer를 분리해서 진행하고 각 파티션 내에 메세지 순서 보장
-> 다수의 파티션에 걸쳐서는 Eventually Consistent (데이터 쓰기 작업 시 복제 대기 없이 리턴되는 것. 반대의 케이스는 Strong Consistency)- 풍부한 생태계 존재해 타 프레임워크와 쉽게 연동 가능 (kafka connect, kafka schema registry)
🎈 kafka architecture
- data event stream : Topic
-> Producer가 Topic을 만들고 Consumer가 Topic에서 데이터를 읽어들이는 구조 (여러 Consumer가 동일한 Topic을 기반으로 읽기도 가능)
- message event 구조 (key, value, timestamp)
-> timestamp는 보통 데이터가 Topic에 추가된 시점을 의미하고 header는 선택적 구성요소
(key 잘못 설정 시 data skew 문제 발생 가능)
- 각 Topic은 확장성을 위해 다수의 파티션으로 나뉘어 저장됌.
(키 유무, 해싱을 기반으로 어느 파티션에 속할 지 결정)
- 각 파티션은 유실 (failover)를 위해 replication 파티션을 가지며 consistency level 설정 가능
(각각 1개의 leader, 여러 개의 follwer로 구성되며 쓰기는 leader, 읽기는 leader, follwer)하나의 파티션은 다수의 segment로 구성되며 각 segment는 디스크 상 존재하는 하나의 파일.
최대 크기가 존재해 이를 넘어가는 경우 새로 segment 파일 생성
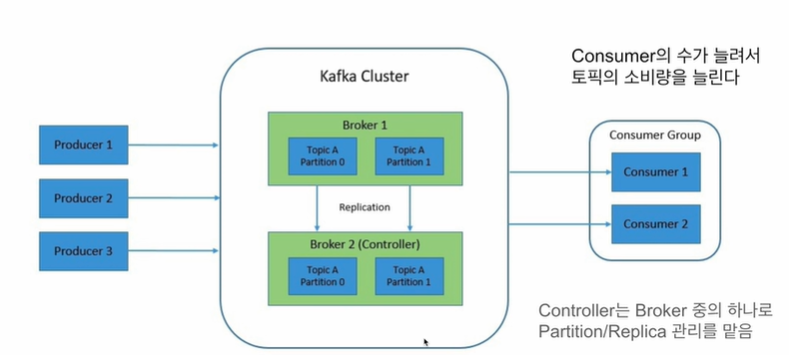
- kafka 클러스터는 기본적으로 다수의 broker(실제 데이터 저장하는 서버)로 구성
-> broker들이 실제로 producer/consumer와 통신 수행하며 kafka node 또는 kafka server라고도 함.
(물리서버 또는 vm, docker container 등으로 동작하며 topic의 파티션 관리)✨ 추가로 다음과 같은 관리가 필요하다.
1. broker 리스트 관리 - controller
2. topic 리스트 관리 (파티션 관리 및 파티션 별 복제본 관리)
3. topic 별 Access Control List 관리
4. Quota 관리🎈 kafka 주요 개념
1. kafka가 중앙에 메시지 큐 형태로 존재.
2. producer가 메시지 큐에다가 데이터 생성해 저장, 각 producer는 하나의 topic(event stream 생성) -> stream 크기가 크므로 각 파티션에 해시 저장
3. 각 파티션은 broker 서버로부터 관리되고 수많은 파티션 관리를 위해 복제본을 관리하는 broker 중 하나인 controller를 zookerper, kRaft로 설정되어 리스트들 관리
4. consumer가 broker를 통해 topic에 속한 메세지를 읽어서 처리
5. 이후 consumer group을 생성해 동시에 topic을 처리하도록 진행해 backpressure 대비✨ kafka schema registry
producer, consumer 등 source task나 sink task 에서 작업을 실행할 때 메시지 데이터에 대한 스키마 관리 및 검증용으로 사용해 kafka cluster에 일정 스키마만 저장되도록 설계 가능
producer, consumer는 schema registry를 사용해 스키마 변경을 처리한다.
- schema ID, 다양한 포맷 변천 지원 (보통 Avro (row-based) 사용)
- 포맷변경 처리 방법 Compatibility (Forward, Backward, Full)
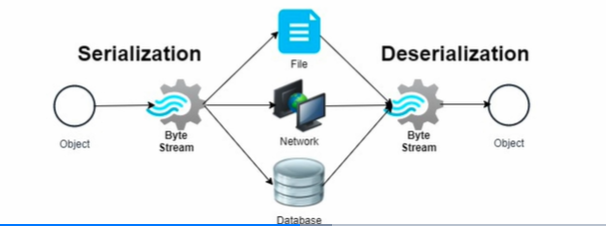
아래 과정을 거쳐 producer는 serialization, consumer는 deserialization 진행
지난번 프로젝트에서 문제가 발생해 Airflow dat 내 task를 작성해 해결했던 문제인데.. kafka로 stream data 처리를 한다면 위와 같은 방법을 활용하면 될 것 같다.
🎈 Architecture - REST Proxy
보통 kafka 사용 시 동일한 네트워크 내 producer, consumer를 사용하여 Avro 기반 활용.
그러나 동일한 네트워크 내 보안 문제로 해당 작업이 불가능할 수 있다.이러한 문제를 해결한 방법이 Topic을 API 형태로 외부에 노출시켜준 것이 REST Proxy.
이를 활용한다면 kafka cluster에 topic 생성 후 메시지 저장은 물론, consumer 생성 역시 가능해진다.
추가로 REST Proxy 역시 Load balancing 이슈로 다수의 서버로 관리하는 것이 기본이다!
✅ kafka install by docker
아래 깃헙 repo 사용해 download
conduktor-kafka
- git clone
git clone https://github.com/conduktor/kafka-stack-docker-compose.git- cd kafka-stack-docker-compose
- docker compose -f full-stack.yml up
- 8080 port로 kafka 웹 콘솔 확인도 가능
-> 웹 콘솔 id: admin@admin.io / pw: admin
바로 연결 성공..!producer, consumer를 파이썬으로 만드는 예제 실행하기
# producer 생성
from time import sleep
from json import dumps
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: dumps(x).encode('utf-8')
)
for j in range(999):
print("Iteration", j)
data = {'counter': j}
producer.send('topic_test', value=data)
sleep(0.5)
# 위 코드 실행 후 웹 콘솔에서 Topic 생성여부 확인
# consumer 생성
from kafka import KafkaConsumer
from json import loads
from time import sleep
consumer = KafkaConsumer(
'topic_test',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='my-group-id',
value_deserializer=lambda x: loads(x.decode('utf-8'))
)
for event in consumer:
event_data = event.value
# Do whatever you want
print(event_data)
sleep(2)
producer에서 메시지 생성 시 key 없이 value만 지정한 모습이기에 라운드-로빈 형태로 메시지가 들어갈 수 밖에 없음.
만일 파티션 수가 여러개라면 키값을 기준으로 해싱처리 가능토록 설계할 필요 있음.
