Cli 툴을 활용하고 Topic의 파라미터가 무엇이 있는지 살펴볼 계획
✅ kafka Cli Tools
- Cli Tool 접근 방법.
-> docker ps로 broker의 container ID 파악 하여 해당 Shell 접속해 kafka 관련 클라이언트 툴 사용
-> kafka-topics / kafka-configs / kafka-consol-consumer, producer ...kafka-topics : kafka 클러스터 내 모든 topic 정보 얻기 가능
: $ kafka-topics --bootstrap-server kafka1:9092 --listkafka-console-producer
: Command line을 통해 토픽 만들고 메시지 생성 가능
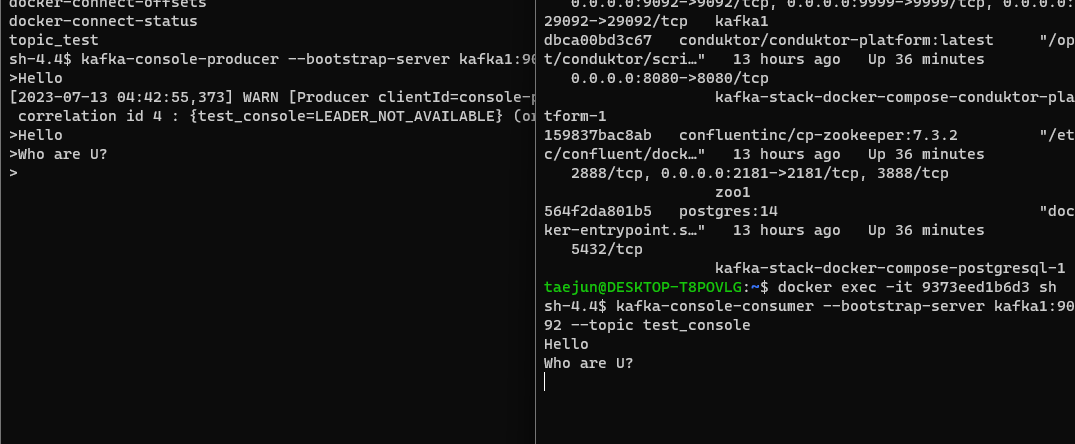
-> $ kafka-console-producer --bootstrap-server kafka1:9092 -topic test_console해당 코드 뒤에 --from-beginning 옵션이 있으면 처음부터 읽게 되며 없다면 latest로 동작한다.
console을 2개 사용하여 한 쪽은 producer, 한 쪽은 consumer로 docker exec 실행해 실시간 데이터 이동 상황을 확인할 수 있다.
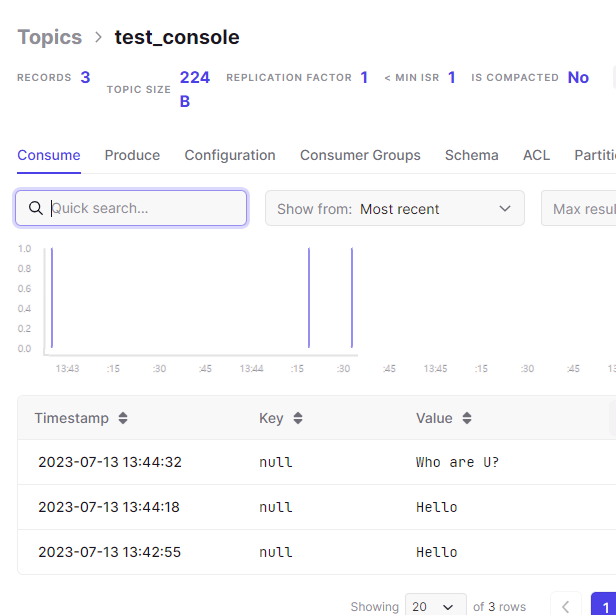
자동으로 consumer를 실행시킨 cmd 창에는 producer에서 생성한 Topic들이 보여지는 모습!웹 콘솔 창에서도 해당 topic과 value가 보이는 모습!
✅ Topic parameter
Topic 생성시에 다수의 파티션, Replica를 주기 위해선 KafkaAdminClient 오브젝터 생성, create_topics 함수로 Topic을 추가.
client = KafkaAdminClient(bootstrap_servers=bootstrap_servers) topic = NewTopic( name = name, num_partitions=partitions, replication_factor=replica) client.create_topics([topic])🎈 kafka producer parameter
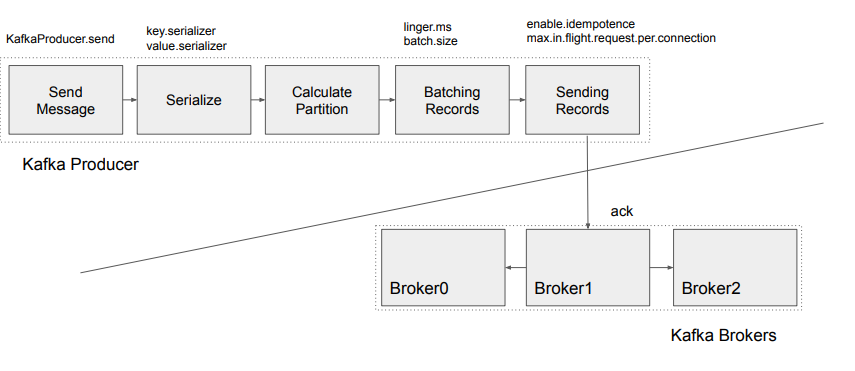
대표적으로 몇개의 파라미터를 살펴보면 다음과 같다.
- bootstrap_servers : 메세지 보낼때 사용할 브로커리스트
- client_id : Kafka Producer 이름
- key(value)_serializer : 메세지의 키, 값 serialize 방법 지정
- enable_idempotence : 중복 메세지 전송 막을 것?
- acks : consistency level (승인 대기 여부)
- retries : 재시도 횟수
- linger_ms : 다수의 메세지 동시에 보내기 위함
이외에도 여러 파라미터가 존재하는데, 아래 링크 참고!
KafkaProducer - Paramter전체적인 producer 동작
practice 1)
Python - pydantic : 파이썬 내 변수의 타입 지정
import uuid
import json
from typing import List
from person import Person
from faker import Faker
from kafka.admin import NewTopic
from kafka.errors import TopicAlreadyExistsError
from kafka import KafkaAdminClient
from kafka.producer import KafkaProducer
# replica 지정 없으면 default는 1
def create_topic(bootstrap_servers, name, partitions, replica=1):
client = KafkaAdminClient(bootstrap_servers=bootstrap_servers)
try:
topic = NewTopic(
name=name,
num_partitions=partitions,
replication_factor=replica)
client.create_topics([topic])
# 토픽 이미 존재하면 에러 raise 발생 후 pass 처리
except TopicAlreadyExistsError as e:
print(e)
pass
finally:
client.close()
def main():
# 토픽이름, 서버 지정
topic_name = "fake_people"
bootstrap_servers = ["localhost:9092"]
# create a topic first
create_topic(bootstrap_servers, topic_name, 4)
# ingest some random people events
people: List[Person] = []
faker = Faker()
producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
client_id="Fake_Person_Producer",
)
for _ in range(100):
# 사람마다 PK 느낌의 ID 부여
person = Person(id=str(uuid.uuid4()), name=faker.name(), title=faker.job().title())
people.append(person)
# 앞서 생성한 토픽으로 key와 value로 전송
producer.send(
topic=topic_name,
key=person.title.lower().replace(r's+', '-').encode('utf-8'),
value=person.json().encode('utf-8'))
producer.flush()
if __name__ == '__main__':
main()🎈 kafka consumer parameter
Q. 하나의 consumer가 다수의 파티션으로 구성된 topic을 읽는다면?
A. Consumer는 각 파티션들로부터 라운드 로빈 형태로 topic들을 하나씩 읽으나, 병렬성이 떨어지고 데이터 생산 속도에 따라 backpressure 심해질 수 있음.
-> 이를 해결하고자 등장한 Consumer Group💡 Consumer Group
- consumer가 topic을 읽기 시작하면 해당 topic내 일부 파티션들이 자동 할당.
- consumer 수가 파티션 수보다 많으면 라운드-로빈 방식으로 consumer에게 파티션이 할당
- consumer group rebalancing (기존 consumer의 에러 사항 발생으로 새로운 consumer가 group에 참여하는 경우 파티션 다시 지정.)
offset_auto_commit이 True인 경우 파티션, 토픽, 오프셋 알아서 처리되지만, False로 지정하는 경우 이를 전부 지정해주어야 하지만, 데이터 정합성이 확보되는 trade-off가 존재한다.
🎈 message processing guarantee
실시간 메시지 처리 및 전송 관점에서 시스템의 보장 방식은 3가지로 존재.
- exactly once : 정확히 한번만 전달. (네트워크 장애, 재시도 등 어려움)
- at least once : 적어도 한번이상 모든메시지가 consumer에게 전달되는 메커니즘, 중복제거 조건 필요.
- at most once : 메시지 손실 가능성에 중점을 두어 메시지 손실은 있을 수 있으나 중복이 없음을 의미
✅ ksqlDB
REST API, ksql 클라이언트 툴을 사용해 topic을 테이블처럼 SQL로 조작.
ksql docker exec로 실행한 후 아래 명령 실행해 조작
-> CREATE STREAM my_stream (id STRING, name STRING, title STRING) WITH (kafka_topic='fake_people', value_format='JSON');
SELECT * FROM my_stream;
✍️ consumer group
앞서 KafkaConsumer를 기반으로 consumer_group_id를 지정한 후 parameter를 조정한다면 위와 같이