
✅ sparkml model Tuning
최적의 hyperparameter 선택
- 최적의 모델 or 모델의 parameter 찾는 것이 아주 중요
- 하나씩 테스트 vs 다수를 동시에 테스트
- cross validation VS hold-out
- 보통 ML Pipeline과 같이 사용
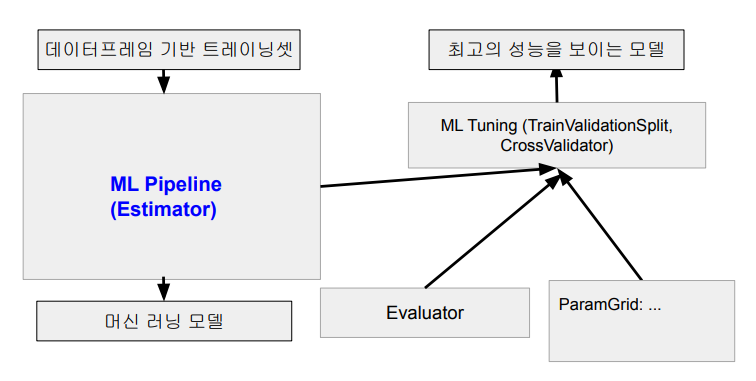
모델 성능 측정은 다음 3가지로 체크
1. Evaluator (회귀, 이진분류 - AUC, 다중분류, Multilabel분류, 랭킹 등)
2. Estimator (모델 fitting, ML Pipeline)
3. ParamGrid : 모델 테스트 관련 가능한 parameter들 (주로 트리 관련 알고리즘에서 중요)
< 모델 빌딩 프로세스 >
✅ PMML
(scikit-learn, pytorch, tensorflow, sparkml)범용 ML 모델 파일포맷.
-> 특히 sparkml을 큰 데이터 (분산 데이터 처리방법)에도 유용
-> 범용 ML 모델 파일포맷이기에 ML모델 서빙환경의 통일도 가능
- Predictive Model Markup Language
- ML 모델을 마크업 언어로 표현해주는 xml 언어
절차는 다음과 같다.- ML Pipeline을 PMML 파일로 저장
- PMML 파일을 기반으로 모델 예측 API로 론치 (오픈소싱 프레임워크, AWS SageMaker, Flask + PyPMML)
- API로 예측결과를 받는 클라이언트 코드 작성
< 예제 코드 ># PMML 파일로 저장 from pyspark2pmml import PMMLBuilder pmmlBuilder = PMMLBuilder(spark.sparkContext, train_fr, cvModel) pmmlBuilder.buildFile("Name.pmml") # 로딩 예제 from pypmml import Model model = Model.load('name.pmml') # 예측 예제 model.predict({'sepal_length':5.1, 'sepal_width':3.5, 'petal_length':1.4, 'petal_width':0.2})

To be a DataScientist