요 근래 SW마에스트로 준비 겸 코테 공부를 다시 진행 중인데 구현 문제들을 여러 개 풀어오면서 논리적인 사고력을 키웠지만, 그래프 쪽에 상당히 취약한 것 같아 탐색 알고리즘에 대한 기본적인 정리를 하고자 한다.
✅ Graph
: node와 edge로 구성되어 2차원 배열로 표현할 수 있다
종류로는 가중(방향) 그래프, 비가중 그래프 형태가 존재하며 구현 방식은 다음과 같다.
- 1. 방향 그래프 : 주어진 그래프에 간선 간 방향이 주어진 상황
class dir_graph: # 생성자 def __init__(self, edges, nodes): # 인접 목록에 대한 메모리 할당 self.adj = [[] for _ in range(nodes)] # 방향 그래프에 간선 추가 for u, v in edges: # 인접 목록의 노드를 u에서 v로 할당 self.adj[u].append(v) # 양방향이라면 아래 코드 추가 self.adj[v].append(u) # 그래프 잘 만들어졌는지 출력 def expression(graph): for u in range(len(graph.adj)): # 현 노드와 인접한 모든 노드 출력 for v in graph.adj[u]: print(f'({u} -> {v})', end = ' ') print() if __name__ == '__main__': # 그래프 간선 edges = [(0, 1), (1, 2), (0, 2), (3, 2), (4, 5), (6, 5)] # 그래프 노드 (0 ~ 7) nodes = 7 # 입력된 nodes, edges로 그래프 구성 graph = dir_graph(edges, nodes) # 그래프 잘 구현되었는지 출력 expression(graph)
- 출력값

- 2. 가중치를 포함한 방향 그래프 : 그래프 방향에 가중치를 둔 그래프
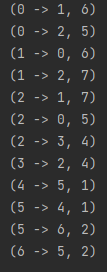
# 그래프 객체 구현 class weight_graph: # 생성자 def __init__(self, edges, nodes): # 인접 리스트를 나타냄 self.adj = [None] * nodes # 인접 리스트에 대해 메모리 할당 for i in range(nodes): self.adj[i] = [] # 간선 추가 for u, v, w in edges: self.adj[u].append((v, w)) # 양방향일 경우 아래 코드 추가 self.adj[v].append((u, w)) # 생성한 그래프 잘 구현되었는지 확인 def expression(graph): for u in range(len(graph.adj)): # 현 노드와 인접한 모든 노드 인쇄 for v, w in graph.adj[u]: print(f'({u} -> {v}, {w})', end = ' ') print() if __name__ == '__main__': # 가중 방향 그래프의 간선 입력(현 노드, 다음 노드, 가중 ex 비용) edges = [(0, 1, 6), (1, 2, 7), (0, 2, 5), (3, 2, 4), (4, 5, 1), (6, 5, 2)] # 노드 수 nodes = 7 graph = weight_graph(edges, nodes) expression(graph)
- 출력값
지금까지 기본적인 그래프 구현에 대해 알아보았고, 그래프를 활용한 탐색 알고리즘에 대해 이해해보고자 한다 😊✍️
탐색알고리즘의 전체적인 구성은 아래와 같다.
✍️ DFS(Depth First Search)
- 깊이 우선탐색으로 느낌 상 "한 놈만 팬다"는 식으로 탐색을 진행한다. (완전탐색)
- 탐색 진행시 리프까지 도달하고 이후 이전 갈림길로 돌아가 방문안한 리프노드 탐색 (재귀)
- stack 자료구조를 사용 (LIFO으로 마지막 리프노드 꺼내서 그 지점의 인접노드를 탐색)
- O(n)의 시간복잡도를 갖는다.
DFS 동작과정은 다음과 같다.
1. 시작노드를 스택에 넣고 방문 처리
2. 인접노드 중 방문하지 않은 곳 골라서 탐색 진행
3. 리프노드 도달 이후 인접 노드가 없다면 이전으로 돌아가 스택에서 꺼냄
4. 2~3 과정 수행할 수 없을 때까지 반복.
코드로 기초적인 DFS 구현방식을 알아보면 다음과 같다.
# 그래프 생성 (빈 노드 + 노드 수만큼 노드 생성)
graph = [[] for _ in range(nodes + 1)
# 방문 여부를 따지기 위해 생성
visited = [0] * (nodes+1)
# 깊이 우선탐색 진행 (그래프, 시작 노드, 방문여부)
def dfs(graph, start_node):
(시작 노드 1로 방문처리)
visited[start_node] = 1
(현 노드와 연결된 다음 노드 들 중)
for next_node in graph[start_node]:
# 다음노드가 방문 처리 안되어있으면
if not visited[next_node]:
# dfs 재귀함수로 탐색
dfs(graph, next_node, visited)🎈 Backtracking (불필요 탐색 진행 X)
- 해결책에 대한 후보를 구축해 나아가다 가능성 없다고 판단되면 즉시 후보를 포기하고 다른 경로를 찾아가는 범용적인 알고리즘으로 제약 충족 문제를 풀 때 주로 사용
- Pruning : 해당 트리에서 조건에 맞지 않는 노드는 DFS로 탐색 X, 가지치기 진행
- Promising : 트리 구조 기반 DFS로 깊이 탐색 진행, 각 루트에 조건 부합 여부 체크
- 백트래킹의 정의 느낌과 유사한 재귀로 보통 구현
- 안되는 조건은 제거해가면서 탐색하기에 시간복잡도를 줄일 수 있다.
정리하자면, 모든 경우의 수 중 특정 조건을 만족하는 경우만을 살펴보는 것으로 답이 되지 않는다고 생각하면 탐색 중단하고 가지치기를 진행하고 이전노드(Backtracking)로 돌아가 다음 자식 노드를 탐색한다. 주로 코딩테스트에서 DFS 등 경우의 수를 탐색하는 과정에서 조건문을 활용해 답이 될 수 없는 상황에 가지치기를 진행할 수 있을 때 구현한다.
✍️ BFS(Breadth First Search)
- 너비우선탐색으로 그래프 내 가까운 인접 노드부터 우선탐색하는 알고리즘 (완전탐색)
- queue 자료구조를 사용(FIFO으로 먼저 들어온 루트노드의 인접노드부터 순서대로 탐색)
- O(n)의 시간복잡도를 갖지만, 실제 수행시간은 DFS보다 좋은 편
BFS 동작과정은 다음과 같다
1. 큐에 시작 노드를 삽입하고 방문처리
2. 큐에서 해당 노드를 꺼내 인접 노드 중 방문하지 않은 곳 큐에 삽입하고 방문처리
3. 2과정 수행할 수 없을 때까지 반복
코드로 기초적인 BFS 구현방식을 알아보면 다음과 같다.
# 큐 구현 위해 deque 라이브러리 사용
from collections import deque
# 그래프 생성
graph = [[] for _ in range(nodes+1)]
# 방문 여부
visited = [0] * (nodes+1)
# 너비우선탐색 진행 (그래프, 시작 노드)
def bfs(graph, start_node)
# 탐색하려는 노드 큐에 삽입
queue = deque([start_node])
# 시작노드 방문처리
visited[start_node] = 1
# 큐에 노드가 없을 때까지 반복
while queue:
# 큐에서 인접노드꺼내기
next_node = queue.popleft()
for i in graph[next_node]:
if not visited[i]:
queue.append(i)
visited[i] = 1