종강하고 독감으로 며칠 개고생하다가 엄청난 양의 precourse 강의 수를 보고 놀랄 수 밖에 없었다..
들어야되는게 왜캐 많은지,, 코테도 해야하는디
4기를 했던 형님 말로는 precourse 강의 퀄리티가 좋다고 하더라
몇개를 들어보니 나름 배워가는 부분도 많고 해서 정리를 하면서 강의들을 보려 한다!
Python data structure
기초 자료구조 정리
문자열
시퀀스자료형으로 문자형 data를 메모리에 저장, 영문자 1글자는 1 byte에 해당
그리고 1byte는 8bit(256) 까지 저장이 가능하다.
각 타입별로 메모리 공간 할당받는 크기가 다르다
int - 4byte
long - 무제한
float - 8byte알아두면 편한 문자열 함수
string.upper() : 대문자로 변환
string.lower() : 소문자로 변환
string.capitalize() : 첫 문자를 대문자로 변환
string.count('a') : string에서 a의 개수 반환
string.find('a') : string에서 a가 들어가 있는 위치 반환
string.startswith('a') : string의 시작이 a인지 True or False로 반환
string.endswith('a') : string의 끝이 a인지 True of False로 반환
string.strip() : 좌우 공백을 없앰
string.split() : 띄어쓰기를 기준으로 나눠서 list 형태로 반환
string.isdigit() : string이 숫자로 이뤄져있는지 여부 반환
string.isalpha() : string이 알파벳으로 이뤄져있는지 여부 반환
string.islower() : string이 소문자로 이뤄져있는지 여부 반환
string.isupper() : string이 대문자로 이뤄져있는지 여부 반환List 자료구조 정리
- 인덱싱
- 슬라이싱
- 리스트 연산
- 추가 삭제
- 메모리 저장 방식
- 패킹과 언패킹
- 이차원 리스트
stack
나중에 넣은 데이터를 먼저 반환하도록 설계한 LIFO 메모리 구조
입력 push, 출력 pop
ex ) 택배 상하차queue
먼저 넣은 데이터를 먼저 반환하도록 하는 FIFO 메모리 구조
입력 push, 출력 pop
ex ) 선입선출
참고사항
pop : 리턴값이 존재하면서 기존 리스트는 변화함
sorted : 리턴값 존재, 리스트 변화 X
sort : 리턴값 존재하지 않고, 리스트 변화 Otuple
()로 생성
데이터 변경이 불가능함
t = (1, )로 한 개의 데이터도 튜플로 생성 가능
사용하는 이유? : 변경되지 않는 고유한 데이터 저장에 사용 ex) 우편번호, 학번 등 사람의 error를 방지하기 위함set
값 순서없이 저장, 중복 불허
add() : 한 원소만 추가
remove() : 값 제거
update() : 한 번에 여러 개의 값 추가 및 제거
discard() : 해당 1개 값 삭제
clear() : 모든 원소 삭제
이외에도 수학에서 활용하는 다양한 집합연산 가능
union, intersection, difference 등등dictionary
데이터 저장할 때 구분 지을 수 있는 값 함께 저장
구분을 위한 데이터 고유 값을 identifier 또는 key라고 함
key를 활용하여 key:value 구조로 존재
다른 언어에서는 hash table이라는 용어 사용
ex ) for key, value in dic.items():collection 모듈
리스트, 튜플, 딕셔너리에 대한 파이썬 built-in 확장 자료 구조(모듈)
편의성 실행 효율 등 사용자에게 제공deque
스택과 큐 지원하는 모듈, 리스트에 비해 빠른 저장 방식 지원
rotate, reverse 등 linkedlist 특성 지원
효율적 메모리 구조로 처리 속도 향상
참고사항 : 시간측정 jupyter : %timeit 함수명()defaultdict
딕셔너리 type의 value에 기본 값 지정, 신규 값 생성 시 사용하는 방법
ex ) dic = defaultdict(lambda : 0) or ()안에 함수명 지정하여 default 값 선언 가능Counter
시퀀스 타입의 데이터 요소들의 개수를 딕셔너리 형태로 반환
set의 연산들을 지원
namedtuple
튜플 형태로 데이터 구조체를 저장하는 방법
저장되는 data의 variable을 사전에 지정해서 저장함

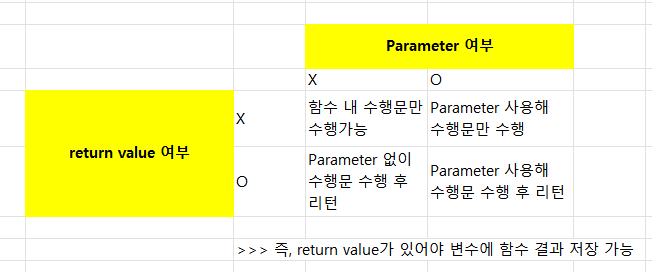
함수 정리
parameter, indentation, return value 등으로 구성된다. parameter는 함수의 입력값 인터페이스를 나타내고 argument는 실제 parameter에 대입된 값을 의미한다. 공통적으로 사용되는 부분을 함수로 코드화하여 변환한다.
함수의 호출 방식
값에 의한(call by value) : 함수에 인자를 넘길 때 값만 넘김
참조에 의한(call by reference) : 함수에 인자를 넘길 때 메모리 주소를 넘김
객체 참조에 의한(call by object reference) : 객체의 주소가 함수로 전달되는 방식가변인자
개수가 정해지지 않은 변수를 함수의 parameter로 사용하고 Asterisk(*) 기호를 사용하여 표시한다. 가변인자는 오직 한 개만 마지막 parameter 위치에 사용이 가능하다.
def function (*args): a,b,c = args키워드 가변인자는 parameter의 이름을 따로 지정하지 않고 입력하는 방법으로 **parameter 의 형식으로 표시한다.
가변인자는 오직 한 개만 기존 가변인자 다음에 사용할 수 있다.
python object oriented programming
OOP 즉 파이썬 객체 프로그래밍을 의미
객체 : 속성과 행동을 가짐.
OOP는 이러한 객체 개념을 프로그램으로 표현 / 속성은 변수, 행동은 메소드로 표현OOP는 설계도에 해당하는 class와 실제 구현체인 instance로 나눔
- class 선언 방식
class Class_Name(상속받는 객체명):
attribute 추가는 init, self, 이때 init은 객체 초기화 함수
반복문 정리
코딩테스트 준비 혹은 전처리용 코드로 알아두면 좋은 부분
for i in range(10): > 0 ~ 9 출력 for i, v in enumerate([a,b,c]): > 인덱스 0,1,2와 이에 대응되는 값 a,b,c 출력 for i, j in zip(a, b): > a, b 각 리스트의 순서대로 출력
lambda
: def 함수 대신 이름 없이 함수처럼 사용 가능함. 단 1개의 argument만 가능.
주로 sort 용으로 사용 많이 함.
ex) 2중 리스트 li가 존재하는 상황에서 li 내 리스트 별 길이를 오름차순으로 정렬할 경우
li.sort(lambda x : len(x)) 와 같이 정렬 가능
Generator
yield를 사용해 한번에 하나의 element만 반환한다. element가 사용되는 시점에 값을 메모리에 반환한다. generator는 일반적인 iterator에 반해 훨씬 작은 메모리 용량을 사용하기 때문에 메모리면에서 효율적이다.
