지난 포스트에서는 회원가입 및 로그인 부분을 진행했다.
이번에는 사투리를 번역하는 엔드포인트를 작성해보자.
기능 개발에 앞서 -
몇 가지 변경점이 있다.
1. user/utils.py 에 함수 추가
async def verify_user(cred):
token = cred.credentials
try:
jwt_dict = jwt.decode(token, settings.SECRET_KEY, settings.ALGORITHM)
if jwt_dict:
return jwt_dict
except ExpiredSignatureError:
raise HTTPException(401, "Expired")- 토큰 정보를 추출한다.
- JWT 토큰을 서버의 SECRET_KEY와 ALGORITHM으로 해독한다.
- 제대로 해독되었다면 해독한 딕셔너리 결과값을 반환한다.
- 만료된 토큰이라면 401 상태코드를 즉시 반환한다.
2. AI/test.py 변경
from transformers import pipeline
import requests
from app.AI import config
from app.config import settings
nlg_pipeline = pipeline(
"text2text-generation", model=config.model_path, tokenizer=config.model_name
)
def generate_text(text, num_return_sequences=1, max_length=60):
target_style_name = "표준어"
text = f"{target_style_name} 말투로 변환:{text}"
out = nlg_pipeline(text, num_return_sequences=num_return_sequences, max_length=max_length)
return [x["generated_text"] for x in out]
# Papago API로 번역하는 함수
def translate_with_papago(text, source_lang="ko", target_lang="en"):
url = "https://openapi.naver.com/v1/papago/n2mt"
headers = {
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"X-Naver-Client-Id": settings.CLIENT_ID,
"X-Naver-Client-Secret": settings.CLIENT_SECRET,
}
data = {"source": source_lang, "target": target_lang, "text": text}
response = requests.post(url, headers=headers, data=data)
translation_result = response.json()
translated_text = translation_result["message"]["result"]["translatedText"]
return translated_text
- 변경 전 코드에서는 deep-translator 라이브러리를 사용했었지만, 번역 품질이 매우 좋지 않았다.
따라서 PAPAGO API를 사용해서 표준어로 변환한 문장을 각각 영어,일본어,중국어로 다시 번역하는 방법으로 변경했다.- test.py를 직접 실행했을 때 수행되는 코드 또한 삭제되어있는데, 테스트 코드 작성 후 테스트 해볼 때 포함 안 되는게 거슬려서 삭제했다. 삭제하지 않아도 무방하다.
papago api 사용법은 https://developers.naver.com/docs/papago/README.md 을 참고하자.
또한 .env 파일에 CLIENT_ID와 CLIENT_SECRET도 추가해줘야 한다!
성능 차이
- Papago
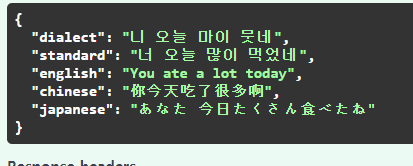

시간을 측정할 때는 영어로 번역하는 부분만 시간을 측정했다.
- deep-translator
같은 문장 (너 오늘 많이 먹었네)를 스크립트로 돌려보겠다.
from deep_translator import GoogleTranslator
from time import time
start = time()
target_text = "너 오늘 많이 먹었네."
print(f"번역 전 : {target_text}")
print(f"번역 후 :{GoogleTranslator(source='ko', traget='en').translate(target_text)}")
print(f"Deep-Translator 경과시간 : {time() - start}")
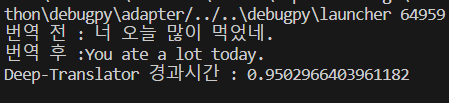
deep-translator를 사용하는 것보다 papago를 사용하는게 시간 측면에서 유리했다. 안 그래도 NLP모델을 CPU 환경에서 사용중인데 최대한 부담을 줄여주는게 좋아보였다.
번역
APP/
ㄴ API/
ㄴ translate/ --> 작업할 공간
ㄴ service.py
ㄴ controller.py
ㄴ schema.pyv1/__init__.py
from fastapi import APIRouter
from .user import controller as user
from .translate import controller as translate
router = APIRouter()
router.include_router(user.router, prefix="/users", tags=["User"])
router.include_router(translate.router, prefix="/AI", tags=["AI"])먼저 __init__.py에 우리가 작성할 router를 포함시켜주자.
controller.py
from fastapi import Depends, APIRouter
from fastapi.security import HTTPAuthorizationCredentials, HTTPBearer
from .schema import Translated, ToTranslate
from .service import itemTranslate
router = APIRouter()
security = HTTPBearer()
# 사투리 -> 표준어 및 다국어로 변환 후 반환
@router.post("", response_model=Translated)
async def translate_item(
data: ToTranslate,
cred: HTTPAuthorizationCredentials = Depends(security),
):
return await itemTranslate(data, cred)- ToTranslate 형태에 맞게 Body를 받는다.
- 로그인 할 때 받았던 토큰을 cred 인자로 받는다.
- itemTranslate에서 반환된 정보를 Translated 형식에 맞게 반환한다.
- 문제없이 작동했다면 반환할 때 200 상태 코드를 반환한다.
service.py
from app.AI import test
from ..user import utils
async def itemTranslate(data, cred):
if await utils.verify_user(cred):
translated_text = test.generate_text(data.dialect)[0] # Translation
english_text = test.translate_with_papago(translated_text)
chinese_text = test.translate_with_papago(translated_text, target_lang="zh-CN")
japanese_text = test.translate_with_papago(translated_text, target_lang="ja")
return {
"dialect": data.dialect,
"standard": translated_text,
"english": english_text,
"chinese": chinese_text,
"japanese": japanese_text,
}- JWT 토큰을 검증한다.
- translate_with_papago 함수로 표준어를 영어, 중국어, 일본어로 번역한다.
- 딕셔너리 형태로 사투리, 표준어, 영어, 중국어, 일본어를 반환한다.
schema.py
from pydantic import BaseModel
class ToTranslate(BaseModel):
dialect: str
class Translated(ToTranslate):
standard: str
english: str
chinese: str
japanese: str

위의 내용들을 잘 따라왔다면 Swagger에서 확인이 될 것이다.
이번에도 필자는 리팩토링 이후 사진이라 V2로 태깅이 되어있다.
유의할 점은 Swagger에서 이 엔드포인트를 사용하려고 할 때 옆의 자물쇠 버튼을 클릭해서 Login하고 헤더에 들어있는 토큰 값을 넣어줘야하니 잘 기억해놓도록 하자.

가치를 창출하는 개발자! 가 목표입니다