- 복습 및 수업 개요
이번 5주차 BDA 빅데이터 분석 학회 수업에서는 효율적인 데이터 전처리를 중심으로 학습했다. 이전 주차에서 다뤘던 자료형과 메모리 관리에 대한 기초를 바탕으로, 이번에는 실무 환경에서 속도와 효율을 모두 확보하는 전처리 전략을 배웠다. 강의 초반에는 메모리 모니터링, 정수형(Integer), 부동소수점 오차, 문자열, Datetime 등 데이터 타입별 메모리 사용 특징을 복습하며 최적화 포인트를 점검했다.
⸻
- 벡터화(Vectorize)의 개념과 중요성
가장 인상 깊었던 내용은 벡터화(Vectorize)였다. 파이썬의 반복문을 사용하는 대신, NumPy나 Pandas의 벡터 연산을 적용하면 속도 차이가 압도적이라는 점을 실습으로 확인했다.
덧셈 연산에서 약 182배, MinMaxScaling에서는 78배, Datetime 처리에서는 무려 2300배의 성능 차이를 보였다. 이처럼 벡터화는 C 기반 저수준 최적화, 연속적 메모리 배치, SIMD 병렬화 덕분에 가능한 기술임을 배웠다.
⸻
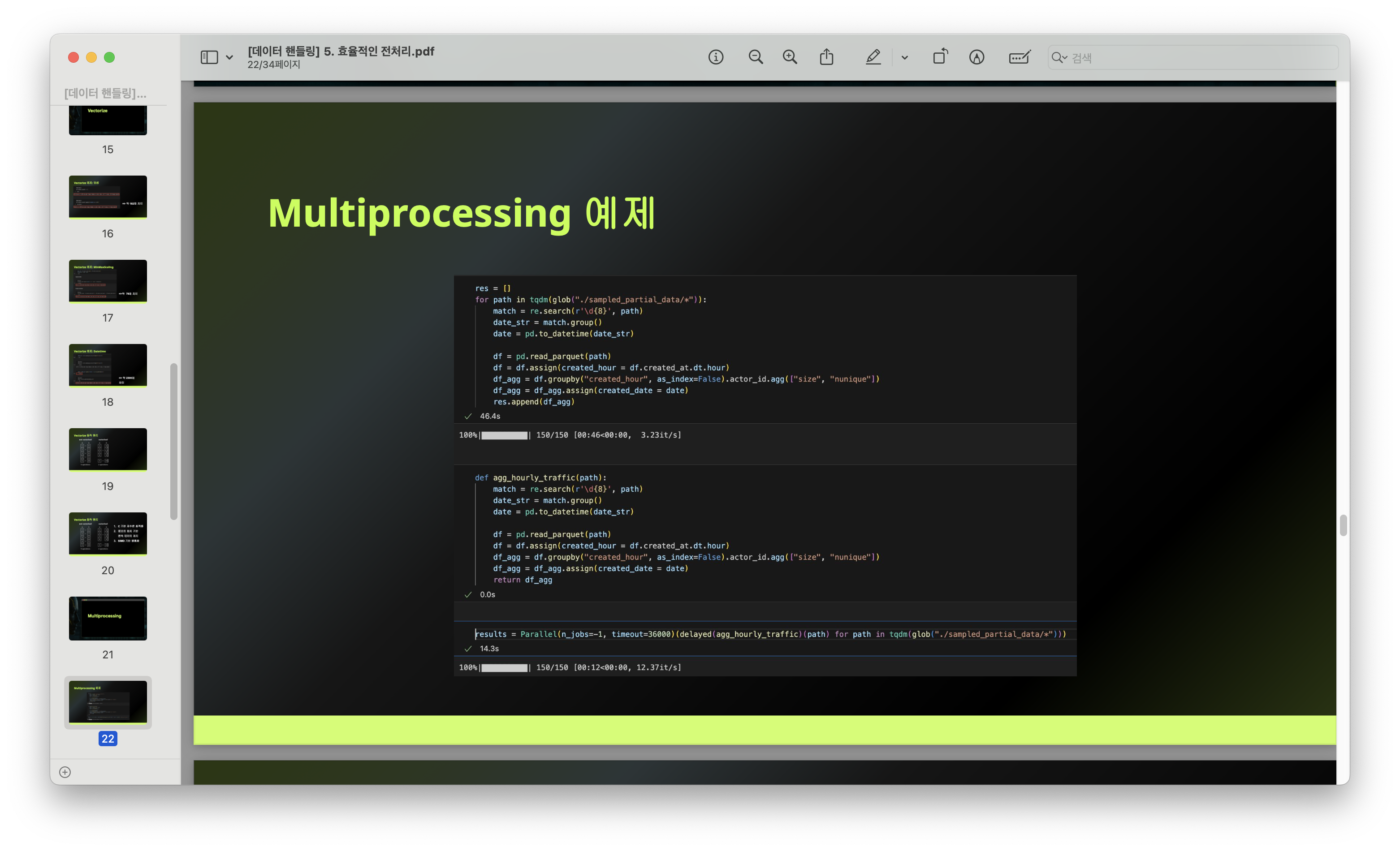
- 멀티프로세싱(Multiprocessing) 실습
다음으로 배운 주제는 멀티프로세싱이었다. 여러 코어를 활용해 동시에 작업을 분배함으로써 대용량 데이터 처리 속도를 높이는 방법이다. Python의 multiprocessing 패키지를 이용해 병렬처리 코드를 직접 작성해보았고, 프로세스별로 작업이 분배되는 원리를 실습을 통해 이해했다.
이 과정에서 단순 병렬화가 항상 빠르지 않다는 점, 튜닝이 까다롭다는 점도 함께 배웠다.
⸻
- Vectorize vs Multiprocessing 비교
벡터화와 멀티프로세싱은 모두 성능 향상을 위한 기법이지만, 적용 상황이 다르다는 점이 흥미로웠다.
Vectorize는 단순한 반복 계산에서 수백~수천 배 빠른 속도를 보여주며, 복잡한 작업에는 부적합하다. 반면 Multiprocessing은 복잡한 대용량 데이터를 병렬 분산 처리할 때 유용하다.
수업에서는 “Vectorize는 빠름, Multiprocessing은 넓음”이라는 문장이 인상 깊게 남았다. 두 방법의 차이를 정확히 구분해 적용하는 것이 앞으로의 데이터 핸들링 실무에서 큰 강점이 될 것 같다.
⸻
- Pandas 인덱스와 전처리 효율화
마지막으로 Pandas의 Index 구조를 활용한 효율적인 전처리 방법을 다뤘다. Pandas는 인덱스를 중심으로 작동하며, loc를 사용하면 O(1) 복잡도로 데이터를 접근할 수 있다. 반면 filter()는 전체 탐색이 필요하기 때문에 비효율적이다. 또한 concat()을 이용하면 인덱스 기반으로 Join 연산을 단순화할 수 있어, 복잡한 병합 작업의 속도를 크게 개선할 수 있었다.
⸻
- 다짐 — 휴회 후 새로운 출발
휴회 기간 동안 잠시 멈춰 있었지만, 이번 5주차 수업을 통해 다시 데이터 분석의 본질을 되새겼다. 단순히 코드를 짜는 것이 아니라, “더 빠르고, 더 효율적으로” 데이터를 다루는 능력이 중요하다는 점을 깊이 느꼈다. 앞으로 남은 학기 동안은 BDA 학회 활동과 함께, 실제 프로젝트 코드에서도 벡터화와 병렬처리를 적극적으로 적용해보고자 한다. 이번 학습을 발판으로 더욱 성장한 데이터 핸들러가 되겠다는 다짐으로 5주차를 시작한다.
#BDA #BDA학회 #데이터분석 #학회 #데이터분석학회 #취업 #취업준비 #대외활동
