[혼공데분] 3주차 활동일지

CHAPTER 03. 데이터 정제하기
01. 불필요한 데이터 삭제하기
데이터 정제
: 데이터가 손상되거나 부정확한 부분을 수정하고, 블필요한 데이터를 삭제하거나 불완전한 값을 교체하는 등의 작업
데이터 분석 목적에 맞게 변환하는 데이터 랭글링, 데이터 먼징의 일부로 수행될 수도 있음
열 삭제하기 1 : 슬라이싱 (loc 메서드 이용)
loc은 슬라이싱에서 맨 마지막을 포함함
s_book = ns_df.loc[:,'번호':'등록일자']
ns_book.head()
번호 도서명 저자 출판사 발행년도 ISBN 세트 ISBN 부가기호 권 주제분류번호 도서권수 대출건수 등록일자
0 1 인공지능과 흙 김동훈 지음 민음사 2021 9788937444319 NaN NaN NaN NaN 1 0 2021-03-19
1 2 가짜 행복 권하는 사회 김태형 지음 갈매나무 2021 9791190123969 NaN NaN NaN NaN 1 0 2021-03-19
2 3 나도 한 문장 잘 쓰면 바랄 게 없겠네 김선영 지음 블랙피쉬 2021 9788968332982 NaN NaN NaN NaN 1 0 2021-03-19
3 4 예루살렘 해변 이도 게펜 지음, 임재희 옮김 문학세계사 2021 9788970759906 NaN NaN NaN NaN 1 0 2021-03-19
4 5 김성곤의 중국한시기행 : 장강·황하 편 김성곤 지음 김영사 2021 9788934990833 NaN NaN NaN NaN 1 0 2021-03-19열 삭제하기 2 : 불리언 배열 (loc 메서드 이용)
판다스 배열 성격의 객체는 자동으로 배열 안 모든 원소와 하나씩 비교하는 '원소별 비교' 성격을 이용해 불리언 배열을 얻음
selected_columns = ns_df.columns != 'Unnamed: 13'
ns_book = ns_df.loc[:, selected_columns] # True인 열의 모든 행 선택
ns_book.head() 번호 도서명 저자 출판사 발행년도 ISBN 세트 ISBN 부가기호 권 주제분류번호 도서권수 대출건수 등록일자
0 1 인공지능과 흙 김동훈 지음 민음사 2021 9788937444319 NaN NaN NaN NaN 1 0 2021-03-19
1 2 가짜 행복 권하는 사회 김태형 지음 갈매나무 2021 9791190123969 NaN NaN NaN NaN 1 0 2021-03-19
2 3 나도 한 문장 잘 쓰면 바랄 게 없겠네 김선영 지음 블랙피쉬 2021 9788968332982 NaN NaN NaN NaN 1 0 2021-03-19
3 4 예루살렘 해변 이도 게펜 지음, 임재희 옮김 문학세계사 2021 9788970759906 NaN NaN NaN NaN 1 0 2021-03-19
4 5 김성곤의 중국한시기행 : 장강·황하 편 김성곤 지음 김영사 2021 9788934990833 NaN NaN NaN NaN 1 0 2021-03-19열 삭제하기 3 : drop 메서드
ns_book = ns_df.drop('Unnamed: 13', axis=1)
# 삭제하려는 열 이름, 매개변수가 1이면 열 삭제 (기본값 0은 행 삭제)
ns_book.head()데이터 프레임 수정 - inplace
객체가 수정되는 건 아니고 새 객체 생성 후 가르키는 거임
ns_book.drop('주제분류번호', axis=1, inplace=True) # inplace=True로 데이터프레임 덮어쓰기
ns_book.head()NaN 행이나 열 삭제 - dropna 메서드
ns_book = ns_df.dropna(axis=1) # 기본적으로 하나 이상 포함된 행이나 열 삭제
ns_book.head()모든 값이 NaN인 열 삭제 - how='all'
ns_book = ns_df.dropna(axis=1, how='all')
ns_book.head()행 삭제하기 2 : drop 메서드__[] 연산자
[] 연산자에 열 이름 또는 열 이름 리스트를 전달하여 데이터프레임의 열을 선택,
[] 연산자에 슬라이싱이나 불리언 배열을 전달하면 행을 선택함
ns_book2 = ns_book[0:2] # 슬라이싱
ns_book2.head()행 삭제하기 3 : loc 이용
ns_book2 = ns_book.loc[selected_rows] # 동일코드, [selected_rows,:]
ns_book2.head()행 삭제할 때 loc 메서드, drop() 메서드, dropna() 메서드를 모두 사용할 수 있지만, 불리언 배열을 [] 연산자에 전달하는 방법을 자주 사용함
중복된 행 찾기 - duplicated() 메서드
sum(ns_book.duplicated(subset=['도서명', '저자', 'ISBN'])) # 기준 행 설정그룹별로 모으기 - groupby() 메서드
중복된 행을 합치지 않고 그냥 삭제 - drop_duplicates() 메서드, subset, keep, inplace 매개변수
loan_count = count_df.groupby(by=['도서명','저자','ISBN','권','대출건수'], dropna=False).sum()
loan_count.head()원본 데이터 업데이트 (불리언 배열 반전 - ~ 연산자_판다스)
dup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN'])
unique_rows = ~dup_rows
ns_book3 = ns_book[unique_rows].copy()copy() 메서드를 사용하는 이유
사용하지 않으면 데이터프레임이 별도의 메모리 공간에 저장되는지 보정하지 않음
판다스에서 일부 행이나 열을 선택하여 데이터를 업데이트할 때는 항상 복사하는 것이 좋음
업데이트 하기 - update()
ns_book3.update(loan_count)
ns_book3.head()데이터프레임 인덱스 재설정 - reset_index() <-> set_index()
ns_book4 = ns_book3.reset_index()
ns_book4.head()열 순서 변경 - [] 연산자
ns_book4 = ns_book4[ns_book.columns]
ns_book4.head()02. 잘못된 데이터 수정하기
info() 메서드 : 데이터프레임의 정보를 요약해서 출력
ns_book4.info(memory_usage='deep') # 정확한 메모리 값 알기isna() 메서드 : 누락된 값 개수 확인하기_불리언 배열 반환 <-> notna()
ns_book4.isna().sum()None과 np.nan : 누락된 값으로 표시하기
ns_book4.loc[0, '도서권수'] = None # 판다스 데이터프레임은 정수 저장 열에 None이 들어오면 누락된 값으로 인식
ns_book4['도서권수'].isna().sum()astype() 메서드 : 데이터 타입 지정
ns_book4.loc[0, '도서권수'] = 1
ns_book4 = ns_book4.astype({'도서권수':'int32', '대출건수': 'int32'}) # 딕셔너리로 전달, 새로운 데이터프레임 반환
ns_book4.head(2)loc, fillna() 메서드 : 누락된 값 바꾸기(1)
ns_book4.fillna('없음').isna().sum()replace() 메서드 : 누락된 값 바꾸기 (2)_새로운 데이터프레임 반환
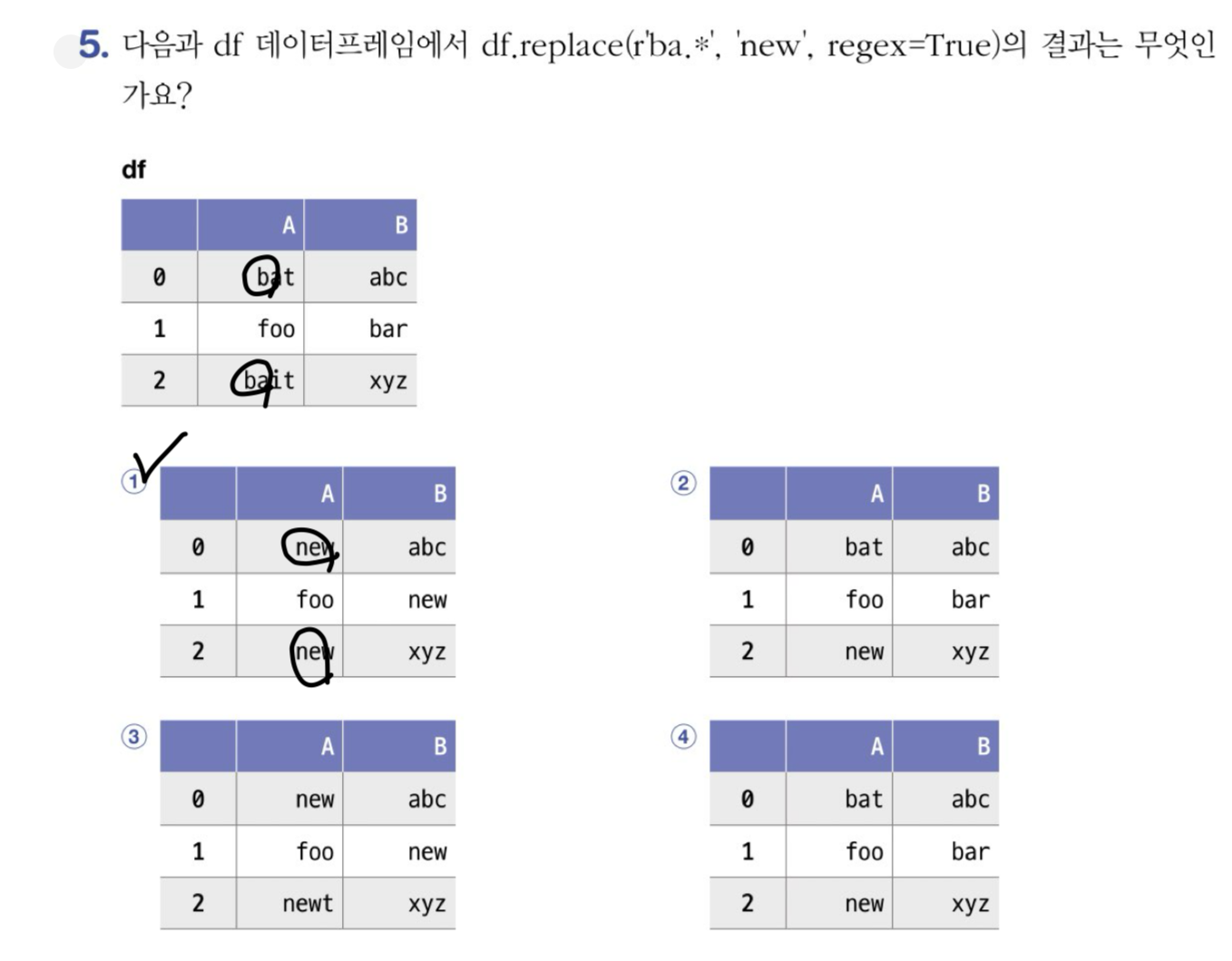
ns_book4.replace({'부가기호': {np.nan: '없음'}, '발행년도': {'2021': '21'}}).head()정규표현식 (정규식)
ns_book4.replace({'발행년도': {r'\d{2}(\d{2})': r'\1'}}, regex=True)[100:102]마침표 : 문자 찾기
ns_book4.replace({'저자': {r'(.*)\s\(지은이\)(.*)\s\(옮긴이\)': r'\1\2'},
'발행년도': {r'\d{2}(\d{2})': r'\1'}}, regex=True)[100:102]잘못된 값 바꾸기
ns_book5 = ns_book4.replace({'발행년도':r'.*(\d{4}).*'}, r'\1', regex=True)
ns_book5[invalid_number].head()gt() 메서드 : 전달된 값보다 큰 값을 찾음
ns_book5['발행년도'].gt(4000).sum()누락된 정보 채우기
na_rows = ns_book5['도서명'].isna() | ns_book5['저자'].isna() \
| ns_book5['출판사'].isna() | ns_book5['발행년도'].eq(-1)
print(na_rows.sum())
ns_book5[na_rows].head(2)기본미션

선택미션

컴퓨터정보과