[혼공머신]1주차 학습내용

1주차
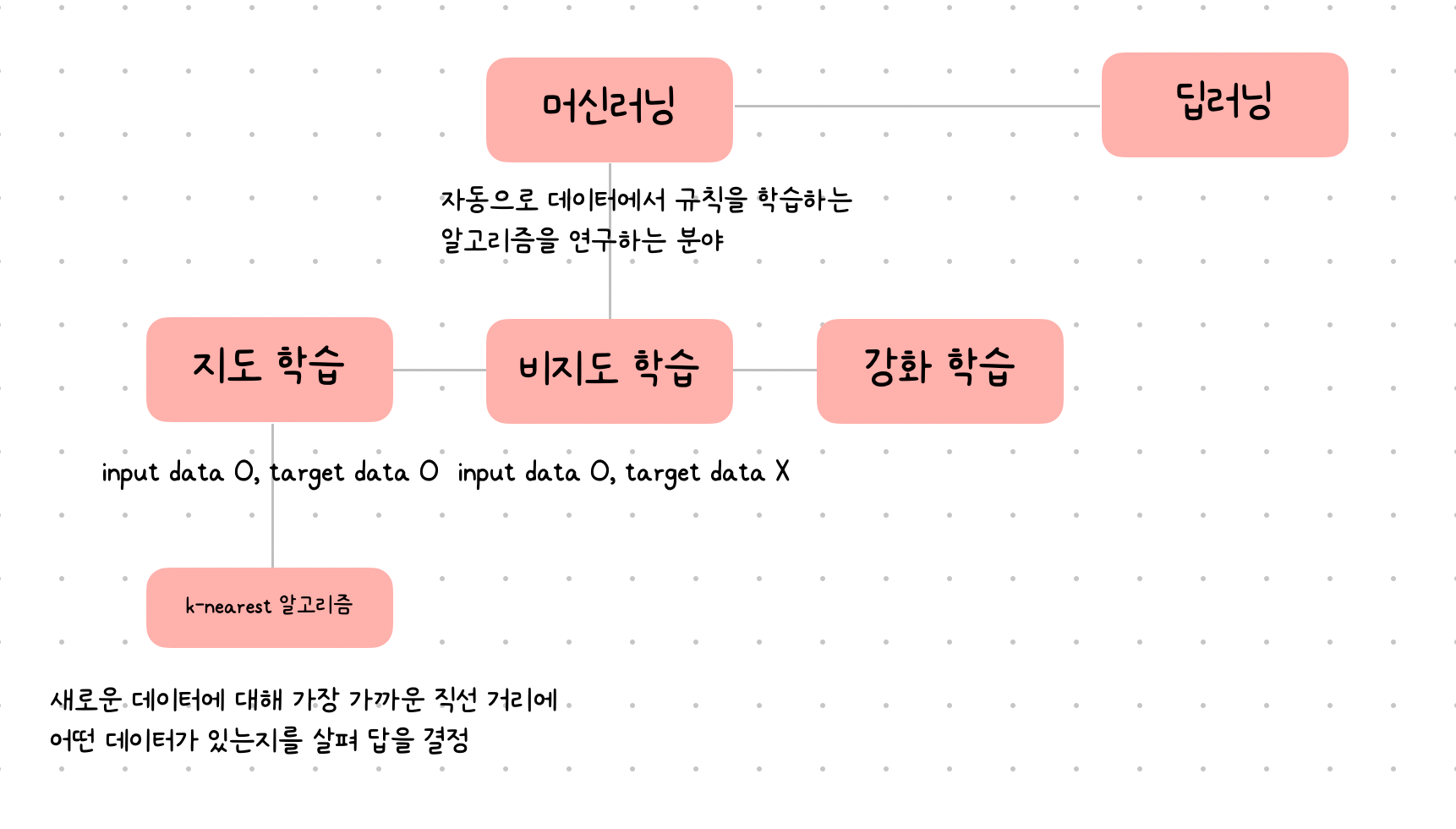
인공지능
사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터
머신러닝
규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
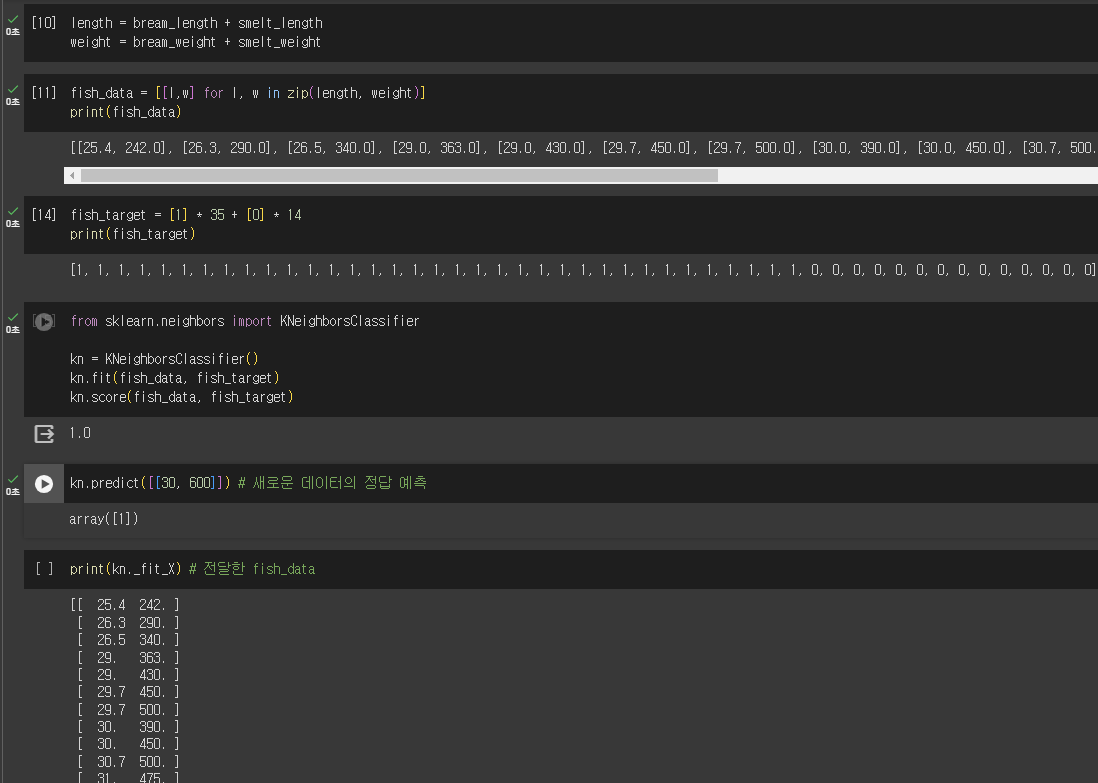
사이킷런: 컴퓨터 과학 분야의 대표적인 머신러닝 라이브러리
fit() : 훈련
predict() 훈련하고 예측
score() 모델의 성능 측정
딥러닝
인공 신경망을 기반으로 한 방법
텐서플로, 파이토치 : 딥러닝 라이브러리
k-nearest neighbors 알고리즘
새로운 데이터에 대해 가장 가까운 직선 거리에 어떤 데이터가 있는지를 살피기만 하면 됨
(기본값 5, 참고 데이터의 수가 5)
데이터가 아주 많으면 사용하기 어려움
데이터가 크면 메모리 많이 필요, 직선거리 계산하는 데도 많은 시간 필요,, 훈련되는 게 없는 셈
KNeighborsClassfier()
n_neighbors 이웃의 개수 (default는 5)
p 거리 재는 방법, 1은 맨해튼 거리, 2는 유클리디안 거리(default는 2)
n_jobs 매개변수로 사용할 CPU 코어, -1은 모두 시용, 이웃 간의 거리 계산 속도를 높임
용어
훈련
모델에 데이터를 전달하여 규칙을 학습하는 과정
정확도
= 맞힌 개수 / 전체 데이터 수
입력 데이터 = input data
정답 데이터 = target data
train set, test set
훈련 데이터와 테스트 데이터
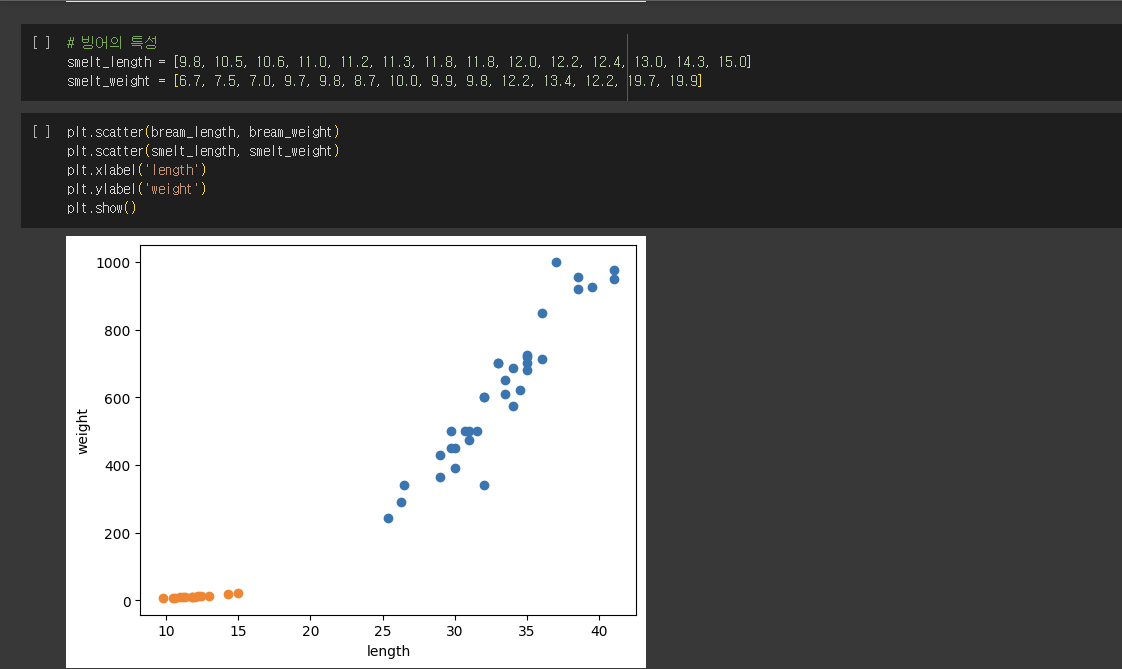
샘플링 편향
특정 종류의 샘플이 과도하게 많은 상태
(샘플이 골고루 섞이지 않은 상태)
특성 feature
데이터의 특징
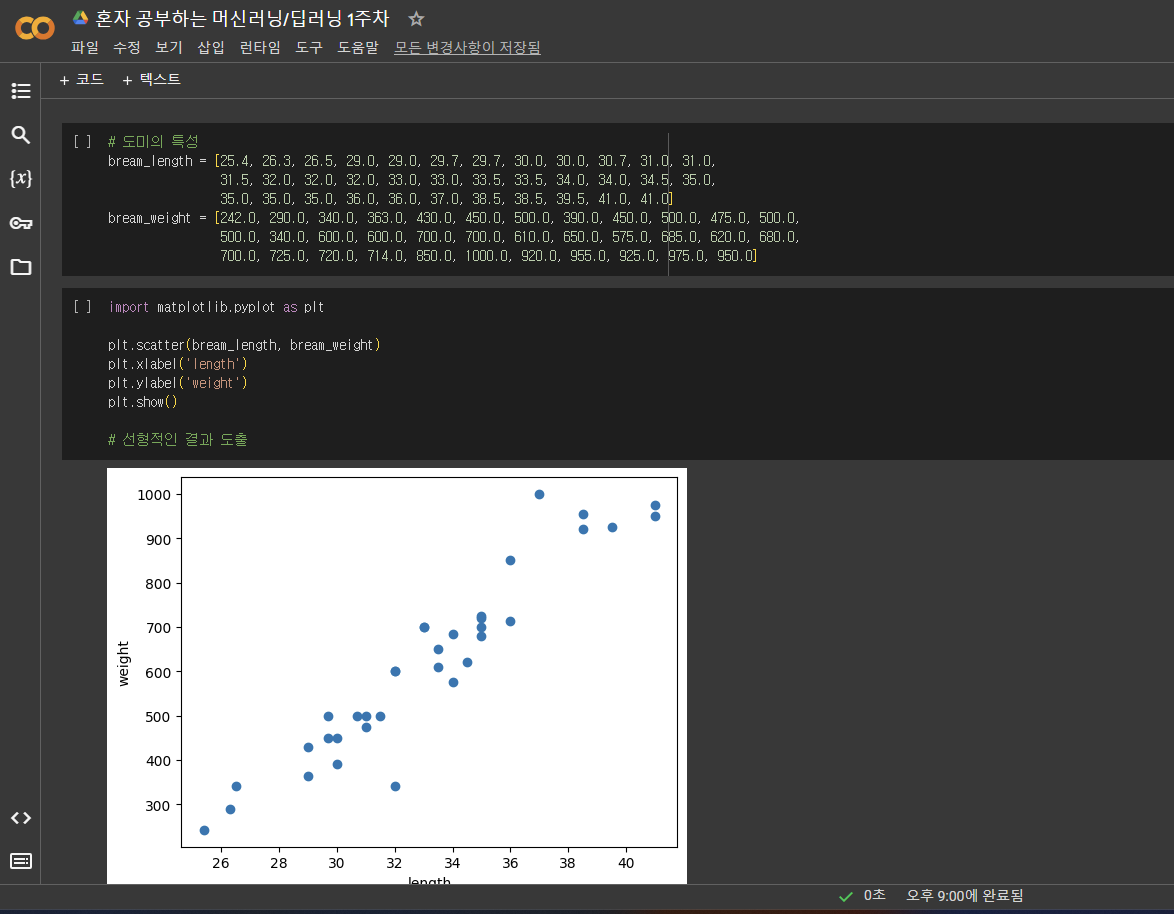
맷플롯립 과학계산용 그래프 패키지
scatter() 산점도 함수
데이터 전처리 data proprecessing
특성들의 범위가 매우 다름 = 두 특성의 scale이 다름
-> 데이터를 표현하는 기준을 맞출 필요가 있음
방법1. 표준점수 (z 점수)
각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지 나타내기
(input-mean) / std -> 넘파이의 브로드캐스팅 기능으로 모든 행에 적용
기본 미션
코랩 실습 화면 캡쳐하기
선택 미션
확인 문제 풀고 풀이과정 적어보기
Q. 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은 무엇인가요?
A. 1번 지도 학습
비지도 학습은 답이 알려지지 않은 학습 방법이고, 차원축소는 다차원 데이터 세트의 차원을 축소하는 것이고, 강화학습은 모델이 직접 학습한다.
