[혼공머신]2주차 학습내용

2주차
머신러닝 모델은 시간과 환경이 변화하면서 데이터도 바뀍 때문에 주기적으로 훈련해야 한다
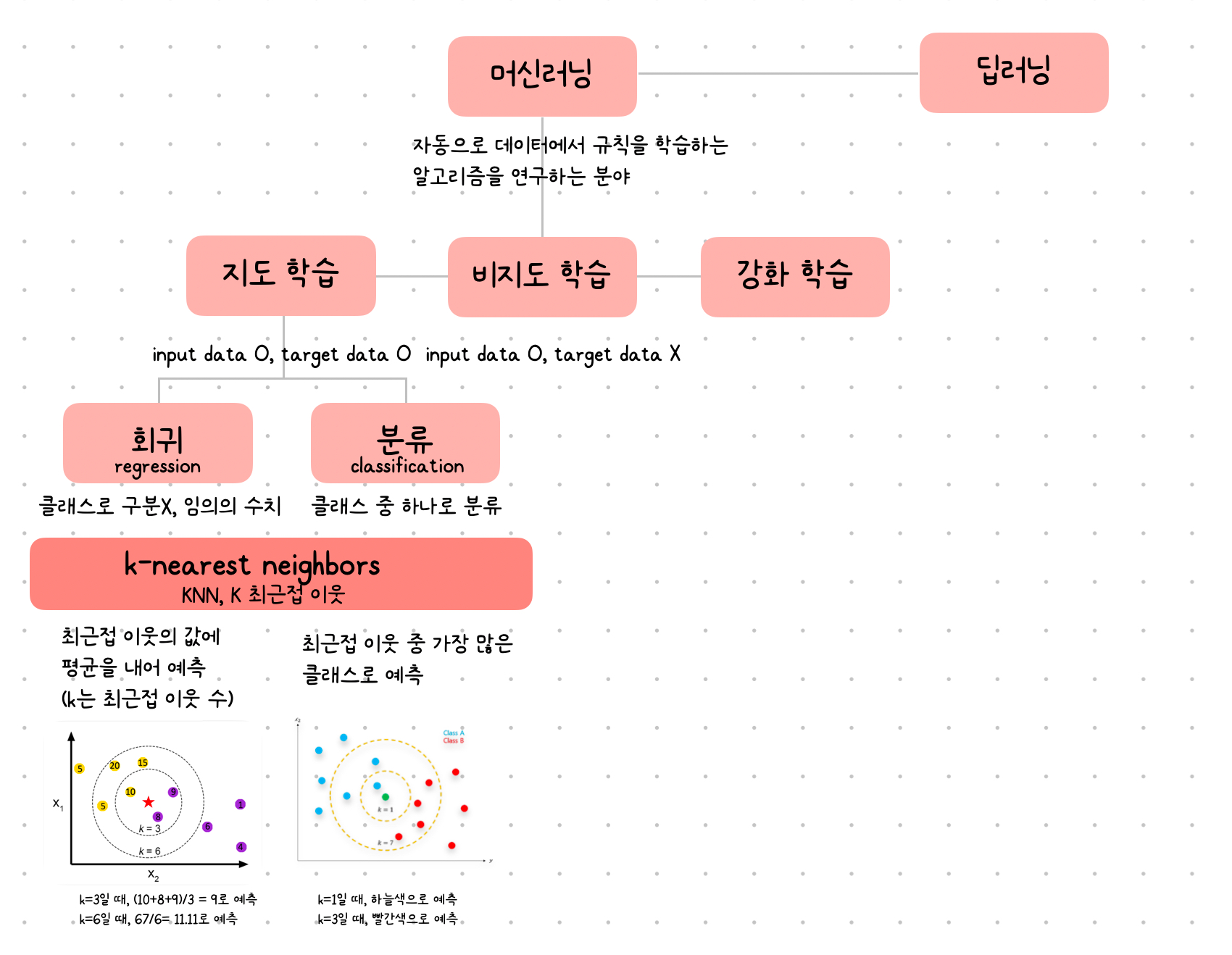
회귀
분류와 다르게 특정 클래스 중 하나로 분류하는 것이 아닌, 임의의 수치를 예측하는 것
k-nn regression (k 최근접 이웃 회귀)
최근접 이웃의 타깃값의 평균으로 예측하는 것
linear regression (선형 회귀)
특성이 하나인 경우 어떤 직선을 학습하는 알고리즘
결정 계수 R²
- 대표적인 회귀 문제의 성능 측정 도구
- 1에 가까울수록 좋고, 0에 가까울 수록 성능이 나쁜 모델
과대적합과 과소적합
과대적합
훈련 세트에서 점수가 굉장히 좋았는데 테스트 세트에서 점수가 굉장히 나빴다면 모델이 훈련 세트에 대해 과대적합
과소적합
훈련 세트보다 테스트 세트 점수가 높거나, 두 점수 모두 낮은 경우 (모델이 단순해서 훈련 세트가 적절히 훈련되지 않은 경우) or 테스트 세트의 크기가 매우 작기 때문
용어
특성 공학
기존의 특성을 사용해 새로운 특성을 뽑아내는 작업
기본 숙제
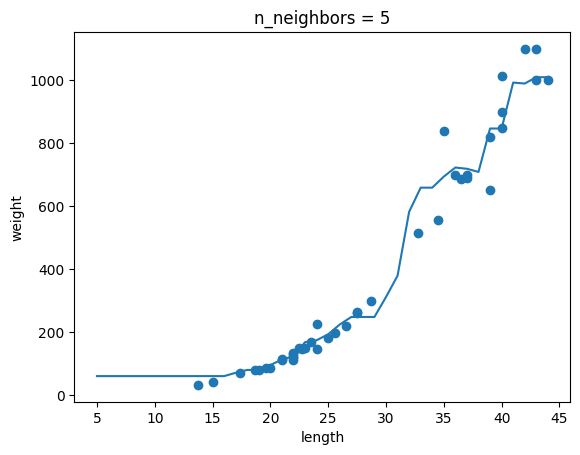
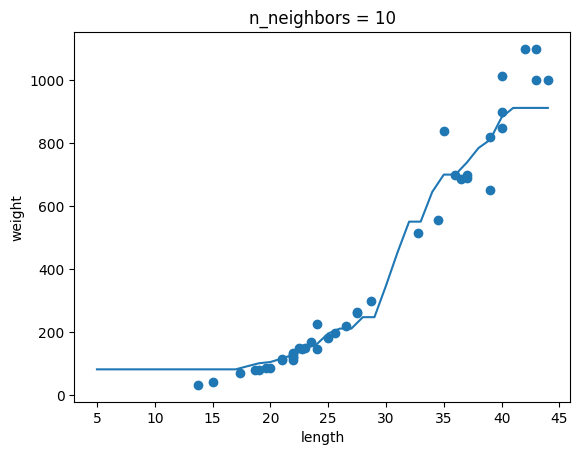
과대적합과 과소적합에 대한 이해를 돕기 위해 복잡한 모델과 단순한 모델을 만들겠습니다. 앞서 만든 k-최근접 이웃 회귀 모델의 k 값을 1, 5, 10으로 바꿔가며 훈련해 보세요. 그다음 농어의 길이를 5에서 45까지 바꿔가며 예측을 만들어 그래프로 나타내 보세요. n이 커짐에 따라 모델이 단순해지는 것을 볼 수 있나요?
# k-최근접 이웃 회귀 객체를 만듭니다
knr = KNeighborsRegressor()
# 5에서 45까지 x 좌표를 만듭니다
x = np.arange(5, 45).reshape(-1, 1)
# n = 1, 5, 10일 때 예측 결과를 그래프로 그립니다.
for n in [1, 5, 10]:
# 모델 훈련
knr.n_neighbors = n
knr.fit(train_input, train_target)
# 지정한 범위 x에 대한 예측 구하기
prediction = knr.predict(x)
# 훈련 세트와 예측 결과 그래프 그리기
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()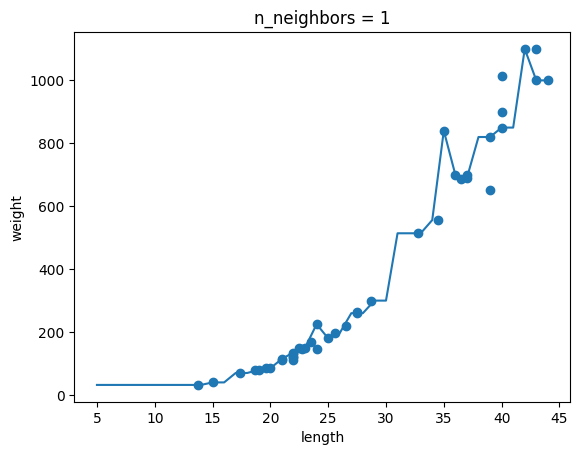

컴퓨터정보과