
Part 1. 전산 기초

1-1. 개발 상식
좋은 코드
-
좋은 코드란 뭐라고 생각? (또는 개발 업무 협업 시 중요한 것)
- 합의된 규칙으로 일관성있게 작성된 코드라고 생각
- 이유 : 팀원들과 합의된 규칙을 기반으로 코드를 일관성있게 작성하면 가독성이 좋아져 다른 사람이 작성한 코드도 비교적 쉽게 이해가 가능하기 때문입니다.
- 또한, 변수/함수의 네이밍 규칙이 있다면, 코드 확장이 편하기 때문입니다.
-
안좋은 코드란 뭐라고 생각?
- 일관성이 없고, 중복된 내용이 많은 코드라고 생각
절차적 프로그래밍과 객체 지향 프로그래밍
-
절차적 프로그래밍이란
- 어떠한 논리 순서대로 명령을 진행하는 것(?)으로, 대표적으로 C가 있습니다.
-
객체 지향 프로그래밍이란 (OOP : Object-Oriented Programming)
- 실세계를 프로그래밍으로 표현하는 것으로, 대표적으로 C++이 있습니다.
- 프로그램을 명령어 목록으로 보지 않고, 필요한 데이터들을 추상화시켜 객체의 모임으로 파악하고자 하는 것입니다.
-
객체지향 프로그래밍의 특징
- 캡슐화 : 클래스가 제공하는 메소드의 기능만을 사용할 뿐, 실제 그 메소드가 어떻게 작동하는지는 보여주지 않고 감추는 것입니다.
- 추상화 : 변수와 함수 등 필요한 데이터들를 하나의 단위로 묶는 것을 의미합니다.
- 상속 : 자식 클래스가 부모 클래스의 특성, 기능을 물려받는 것을 의미합니다. (오버라이딩)
-> 상속은 캡슐화를 유지하면서, 클래스 재사용이 용이하도록 해줍니다. - 다형성 : 같은 함수명이어도, 상황에 따라 다른 의미로 해석될 수 있습니다.(오버로딩)
-
오버로딩과 오버라이딩 차이
TDD
-
TDD란 무엇이고, 어떤 장점이 있는지
- 테스트 주도 개발(Test-Driven Development)는 매우 짧은 개발 사이클에서 주로 사용되는 개발 프로세스입니다.
- TDD는 새로운 요구사항이 주어졌을 때, 먼저 이에 대한 테스트케이스를 만들고, 그 테스트케이스를 통과하기 위한 간단한 코드를 작성합니다.
- 이후, 상황에 맞게 리팩토링하는 방식으로 진행됩니다.
- 리팩토링과 유지보수가 매우 수월해진다는 장점이 있습니다.
- (코테가 일종의 TDD라고 생각하면 쉬울듯 / 아니면 교수님이 우리한테 먼저 작게 코딩해보고 적용하라는거)
-
TDD의 테스트 케이스 만들 때 주의사항
- 개발자는 새로운 기능이 추가되기 전, 해당 기능의 요구사항과 명세를 이해해서 테스트 케이스를 작성해야 올바른 테스트케이스를 만들 수 있습니다.
함수형 프로그래밍
- 함수형 프로그래밍의 특징
- immutable과 mutable이 있습니다.
- immutable 객체 : 해당 객체가 가진 값을 변경할 수 없어야 하며,
-> 만약 값이 변경될 경우, 새로운 객체를 생성해서 변경된 값을 적용하고 반환해야합니다. - mutable 객체 : immutable과 달리, 값을 변경할 수 있어 변경 내용을 적용하고 반환합니다.
MVC
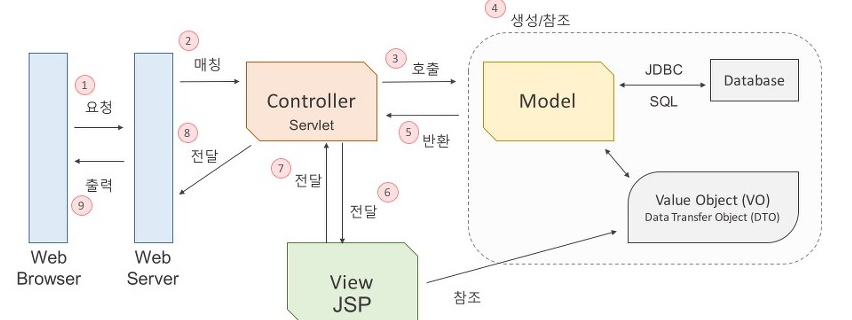
- MVC 패턴이란
- 모델(Model) 뷰(View) 컨트롤러(Controller)가 분리된 구조로, 각각 하나의 역할만 담당합니다.
- Model : 업무에 필요한 데이터를 처리 (DB에 연결하고 데이터 검색,삽입,삭제,업데이트 등)
- View : 사용자 인터페이스 처리 (컨트롤러가 보낸 결과를 사용자에게 출력 ~> 웹으로)
- Controller : 비즈니스 로직을 처리 (클라이언트의 요청을 받아 모델/뷰에게 전달)
- 사용자 요청 -> Controller -> Model(DB 질의) -> Controller -> View(웹 출력)
- Git과 GitHub에 대해
1-2. 자료구조
배열과 Linked list
- 배열과 Linked List 차이 (일전에 정리했던거를 외웠으니 그거로 쓰자)
배열 내용 추가)- index가 있어서, 찾고자 하는 원소의 인덱스값을 알고 있으면 O(1)에 해당 원소로 접근 가능
- 데이터 삽입/삭제 시, 삽입/삭제할 위치를 찾는 비용은 O(1)이지만,
- 그 위치보다 큰 인덱스 데이터들을 shift해줘야하므로, worst case는 O(n)이 된다. (중요)
링크드리스트 내용 추가)
- 한 노드를 삽입/삭제할 때, 다음 노드 주소만 변경하면 되므로, O(1)만에 해결 가능
- 데이터 검색 시 첫 번째 원소부터 다 확인해야되므로, O(n)이 걸린다.
- 이때, 삽입/삭제할 노드를 찾아가는 시간이 필요하니까 삽입/삭제도 결국 O(n)이 된다.(중요)
- 링크드리스트는 Tree구조의 근간이 되는 자료구조다.
- Linked List 파이썬 구현
- 출처 링크 : https://velog.io/@woga1999/파이썬으로-구현하는-링크드-리스트
- 노드 코드
class Node:
def __init__(self, data):
self.data = data # 입력받은 데이터(=val)
self.next = None # 다음 노드 주소 - 링크드리스트 코드
class LinkedList:
def __init__(self, data):
self.head = Node(data) # 맨 처음에 생성 시, 데이터 하나 입력받고, 걔를 head로
# 맨 끝에 노드를 추가하는 함수
def append(self, data):
current = self.head # 현재 링크드 리스트의 head부터 이동 시작
while current.next is not None: # 끝까지 이동
current = current.next
current.next = Node(data) # (중요) 끝까지 갔다면 데이터(노드 객체를!!!) 추가
# 특정 노드의 인덱스 찾는 함수 (삽입/삭제 시 활용)
def get_node(self, index):
cnt = 0 # 이동중인 인덱스 상황
node = self.head # 인덱스가 없으므로, head부터 이동해야함
while cnt < index:
cnt += 1
node = node.next # 한칸씩 이동하는 것!!
return node # 특정 노드를 찾았다면
# 원하는 위치에 노드를 추가하는 함수
def add_node(self, index, data):
new_node = Node(data)
# 만약 맨 앞에 넣고싶다면, head보다 앞에 넣어준다.
if index == 0:
new_node.next = self.head # 1.새 노드의 다음 노드를 head로 지정
self.head = new_node # 2.링크드 리스트의 head를 새 노드로 지정
return
# 특정 인덱스에 넣는다면
node = self.get_node(index - 1) # 삽입할 인덱스까지 찾아간다(index는 0부터)
tmp_node = node.next # tmp <- A
node.next = new_node # A <- B
new_node.next = tmp_node # B <- tmp
# 원하는 위치에 노드를 삭제하는 함수
def delete_node(self, index):
# 만약 맨 앞 노드 삭제하고 싶다면
if index == 0:
self.head = self.head.next # 그 다음 노드꺼로 바로 바꿔주면 됨
return
# 특정 인덱스껄 삭제한다면
node = self.get_node(index - 1) # 삽입할 인덱스까지 찾아간다(index는 0부터)
node.next = node.next.next # (중요) 그 위치에 있던 노드가 가리키는 next 노드의 next노드를 끌어오면 됨
스택과 큐
-
선형 자료구조와 비선형 자료구조
- 선형 자료구조 : 스택/큐 등
- 비선형 자료구조 : 트리
-
스택과 큐 차이 (기존에 정리했던거로 외우자)
- 큐 정리한거에서 "양방향"으로 삽입 아닌데 혹시 잘못 적었으면 수정!!!
-
스택 코드 - 코테본거 넣자
-
큐 코드
-
출처 링크 : https://somjang.tistory.com/entry/파이썬으로-구현하는-자료구조-큐-Queue
-
dequeue 내용 중요!!
-
class Queue():
def __init__(self):
self.queue = []
def enqueue(self, data):
self.queue.append(data)
def dequeue(self):
dequeue_object = None
if self.isEmpty():
print("Queue is Empty")
else:
dequeue_object = self.queue[0] # deque할 맨앞 데이터 저장해두고
self.queue = self.queue[1:] # 앞에서 두 번째부터 슬라이싱으로 옮겨줌
return dequeue_object
# dequeue랑 달리, 맨 앞 데이터만 확인
def peek(self):
peek_object = None
if self.isEmpty():
print("Queue is Empty")
else:
peek_object = self.queue[0]
return peek_object
def isEmpty(self):
is_empty = False
if len(self.queue) == 0:
is_empty = True
return is_empty
Tree
-
Tree 설명
- 트리는 계층 구조로 구성된 자료구조로,
- 스택/큐랑 다르게 비선형 자료구조입니다.
- 크게 루트노드, 인터널노드, 리프노드로 구성되는데,
- 루트 노드 : 가장 최상위 노드
- 리프 노드 : 가장 최하위 노드
- 인터널 노드 : 나머지 노드들을 의미합니다.
- 루트 노드를 제외한 모든 노드는 최대 하나의 부모 노드를 가집니다.
-
Binary Tree 설명 (이진트리 설명)
- 리프노드를 제외한 모든 노드의 자식 노드가 최대 2개로 구성된 트리입니다.
- full binary tree, complete binary tree 등이 있습니다.
- 참고 링크
-
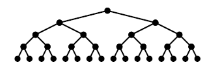
Full binary tree 설명 (정 이진 트리 설명)
- 모든 레벨에서 리프노드를 제외한 모든 노드가 자식 노드를 2개씩 꽉 채워서 갖고있는 이진트리입니다.
- 노드 수가 n개라면, 리프노드 수는 "n/2를 올림"한 수만큼 있습니다.
-
Complete binary tree 설명 (완전 이진 트리 설명)
- 마지막 레벨을 제외한 모든 레벨에서 자식 노드가 2개씩 꽉 채워진 이진트리입니다.
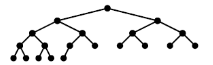
-
BST 설명 (Binary Search Tree 설명)
- 정렬된 이진트리로, 어떠한 노드 A가 있을 때,
- 왼쪽 하위 서브트리는 A의 키보다 작은 노드만, 오른쪽 하위 서브트리는 A의 키보다 큰 노드만 존재하는 트리입니다.
- 하위 서브트리들도 마찬가지로 똑같은 조건이 적용되는 구조입니다.
- 마지막으로, 중복된 키를 허용하지 않습니다.
- 참고 링크 : https://yoongrammer.tistory.com/71
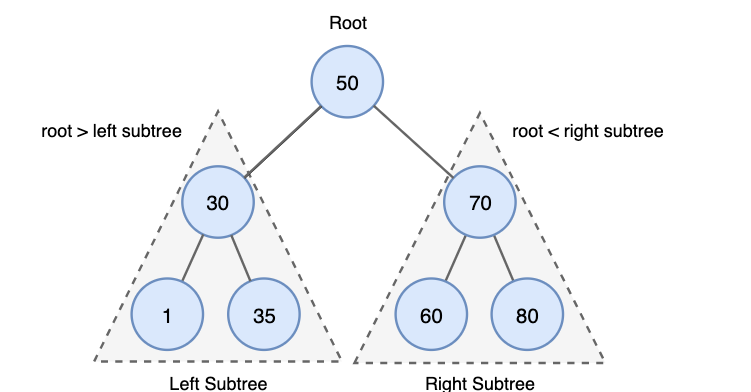
-
BST의 검색 시간복잡도
- 검색 시 시간복잡도는 균형을 이룬 상태면 O(log n)이지만
- 한 쪽으로 편향된 불균형 상태(편향트리)면 최대 O(n) 시간이 걸립니다.
힙 Heap
- 힙 설명 (Heap 설명, 이진 힙 설명)
- 최댓값, 최솟값을 빠르게 찾기 위해 고안된 완전 이진 트리(complete binary tree) 기반의 자료구조입니다.
- 부모 노드의 키값과 자식 노드의 키값 사이에는 대소관계가 성립합니다. (형제사이는 X)
- Max Heap과 Min Heap이 있습니다.
- 참고 링크 : https://yoongrammer.tistory.com/80
- 구현 코드는 나중에!
- 힙을 배열로 표현한다면 ... 루트 노드의 인덱스 i = 1인 경우
- 노드 i의 부모 노드 인덱스 : floor(i/2)
- 노드 i의 왼쪽 자식 인덱스 : 2 * i
- 노드 i의 오른족 자식 인덱스 : 2 * (i + 1)
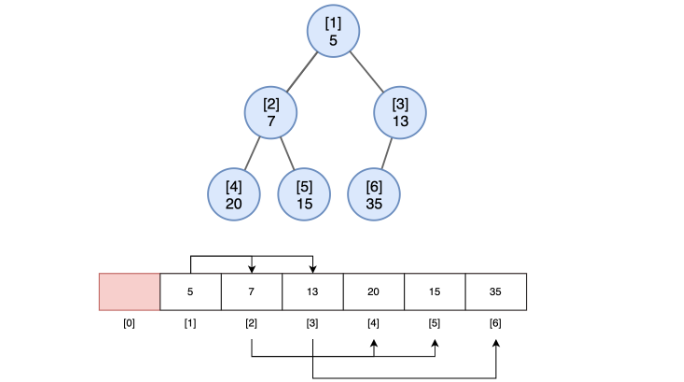
-
Max Heap 설명 (최대 힙 설명)
- 부모 노드의 키값이 자식 노드의 키 값보다 항상 큰 완전 이진트리입니다.
- 즉 가장 큰 값이 루트노드에 있습니다.
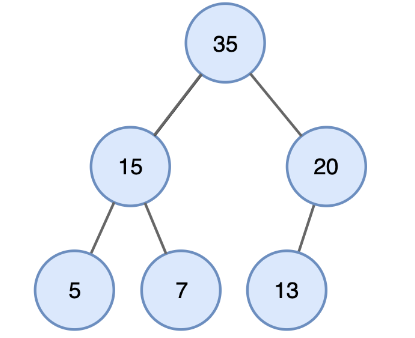
-
Min Heap 설명 (최소 힙 설명)
- 부모 노드의 키값이 자식 노드의 키 값보다 항상 작은 완전 이진트리입니다.
- 즉 가장 작은 값이 루트노드에 있습니다.
Graph
-
그래프란
- node와 edge로 구성된 자료구조입니다.
- edge에 방향성이 있냐 없냐에 따라 무방향 그래프와 방향 그래프로 구분됩니다.
- 또한, edge에 가중치가 있다면, 가중치 그래프(Weight Graph)라고 합니다.
- 인접 행렬과 인접 리스트로 구현할 수 있습니다.
-
그래프에서 degree란
- 어떤 노드에 연결된 edge의 개수
- 만약 방향 그래프라면, 나가는 edge수인 Outdegree와 들어오는 edge수인 Indegree가 있습니다.
-
인접행렬이란 (adjacent matrix란)
- 행렬을 사용해 그래프의 연결 관계를 표현한 것입니다.
- 행렬의 index로 접근하여, value값을 통해 노드간 연결관계를 O(1)로 파악할 수 있습니다.
- Space Complexity는 edge의 개수와 무관하게 V^2입니다.
- Dense graph를 표현할 때 적절한 방법입니다.
-
인접 리스트란 (adjacent list란)
- 연결 리스트를 사용해 그래프의 연결 관계를 표현한 것입니다.
- 인접행렬보다 노드간 연결관계를 확인하는데 오래걸리지만,
- Sparse graph를 표현할 때 적절한 방법입니다.
- Space Complexity는 O(E+V)입니다.
-
그래프 탐색방법에 대해 설명
- DFS와 BFS가 있습니다.
DFS BFS
-
DFS 설명 (깊이 우선 탐색 설명)
- 주어진 그래프에서 어떤 노드를 시작으로 탐색을 진행하는데,
- 각 노드에 연결된 노드 중 "한 노드로만" 나아가며 탐색합니다.
- 이때, 연결된 노드 중 방문하지 않은 노드만 탐색하고
- 모든 노드를 방문했을 때, 탐색이 종료됩니다.
- 주로 stack을 사용해 구현합니다.
-
BFS 설명 (너비 우선 탐색 설명)
- 주어진 그래프에서 어떤 노드를 시작으로 탐색을 진행하는데,
- 각 노드에 연결된 "모든 노드"로 나아가며 탐색합니다.
- 이때, 연결된 노드 중 방문하지 않은 노드만 탐색하고
- 모든 노드를 방문했을 때, 탐색이 종료됩니다.
- 주로 Queue를 사용해 구현합니다.
- 최단경로를 구할 때 BFS를 주로 사용합니다.
-
DFS 장단점
- 장 : 찾으려는 노드가 깊은 단계에 있을 경우, BFS보다 빠르게 찾을 수 있습니다.
- 단 : 해가 없는 경로를 탐색할 경우, 무한정 깊게 탐색할 수 있습니다.
- 단 : DFS를 통해 얻은 해가 최단경로라는 보장이 없습니다. (이해 ㄴ으로 가면 되는데 ㄹ로 가면 최단경로X)
-
BFS 장단점
- 장 : 답이 되는 경로가 여러 개인 경우도 최단경로임을 보장합니다.
- 단 : 경로가 매우 긴 경우, 탐색할 가지수가 증가해 많은 기억공간을 필요로 할 수 있습니다.
추가적인 자료구조들
-
Minimum Spanning Tree 설명 (MST 설명)
-
Kruskal Algorithm 설명 (크루스칼 알고리즘 설명)
-
Prim Algorithm 설명 (프림 알고리즘 설명)
