
Part 1. 전산 기초
1-3. 데이터베이스
데이터베이스
-
데이터베이스란
- 조직의 여러 사용자가 공유하면서 사용할 수 있도록, 통합하여 저장되는 데이터들의 집합
-
DB를 쓰는 이유
- 데이터의 종속성, 중복성, 무결성 등의 문제를 해결하면서 데이터를 효율적으로 관리하기 위해 사용합니다.
- 제가 알기로, DB가 존재하기 이전엔 "파일 시스템"을 이용해 데이터를 관리했습니다.
- 파일시스템은 데이터를 각각의 파일 단위로 저장하고 관리하는데,
- 이때 데이터의 종속성, 중복성, 무결성 등의 문제가 있어 이를 해결하고자 DB가 등장한 것으로 알고 있습니다.
-
데이터의 종속성이란 (=파일시스템 문제점)
- 응용 프로그램이 데이터파일에 종속적이었다는 뜻
- 예를들어 고객 관리 시스템에서 고객 파일의 인덱스가 바뀌면 모든 응용 프로그램에서 파일에 대한 접근 방법을 변경해야 한다.
-
데이터의 중복성이란 (=파일시스템 문제점)
- 여러 곳에 같은 데이터가 중복으로 저장되었다는 뜻
- 예를들어 고객 관리 시스템에 저장된 고객id, name이 주문 관리 시스템에서도 저장된 경우.
- 저장공간이 낭비되며, 데이터의 일관성과 무결성을 유지하기 어려워진다.
-
DB 특징을 설명
- 나중에 찾아보고 추가해보자
-
DB의 성능은 어떻게 측정하는지? DB 성능지표가 무엇인지?
- DB의 성능은 주로 디스크 I/O를 어떻게 줄일지에서 시작됩니다.
- Disk I/O란 디스크 드라이브의 원판을 돌려서, 읽고자 하는 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미합니다.
- 이때 데이터를 읽는데 걸리는 시간은 디스크 헤더를 움직여서 읽고 쓰는 위치로 옮기는 과정에서 결정됩니다.
- 즉, 디스크 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한번에 읽고 쓰느냐에 따라 결정된다고 볼 수 있습니다.
-
I/O란?
- i/o란 입출력(input & output)의 준말로,
- 디스크 드라이브의 원판을 돌려서, 읽고자 하는 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미합니다.
-
랜덤 I/O와 순차 I/O
- 두 방식 다 디스크 헤드를 움직이는건 똑같으나,
- 순차 IO : 시작위치에 간 뒤, 연속된 페이지를 쭉 접근해서 데이터를 찾는 방식으로, 디스크에 기록하기 위해 1번 시스템 콜을 요청하는 방식(=디스크 헤드 1번 움직임)
- 랜덤 IO : 여러 개의 페이지를 디스크에 기록하기 위해 n번의 시스템 콜을 요청하는 방식(=디스크 헤드 n번 움직임)
-
IO관련 알아둘것
- 당연 랜덤 IO가 순차 IO보다 성능이 떨어진다.
(참고로 SSD를 사용하면 플래시 메모리에 데이터를 저장해 원판을 회전시킬 필요가 없으므로 데이터를 빠르게 찾을 수 있음) - 이해 그림 링크 : https://devlog-wjdrbs96.tistory.com/341
- 이해 설명 링크(중간에) : https://velog.io/@keywookim/MySQL-Index-쿼리튜닝의-기본-1
- 당연 랜덤 IO가 순차 IO보다 성능이 떨어진다.
-
랜덤 I/O를 해결하는 방법
- 보통 쿼리를 튜닝해서 랜덤 IO를 순차 IO로 바꿔서 실행
- 이때 랜덤 IO를 줄인다는 것은 쿼리를 처리하는데 꼭 필요한 데이터만 읽도록 쿼리를 개선한다는 것을 의미합니다.
인덱스
-
인덱스란? (기존에 썼던거 이거로 바꾸기)
- DB의 인덱스는 책의 색인과 같이,
- 추가적인 "쓰기 작업"과 "저장 공간"을 활용해 DB의 "검색 속도를 향상"시키기 위한 자료구조입니다.
- 데이터를 검색할 때, 테이블을 순차적으로 접근하면 시간이 오래 걸리기 때문에,
데이터와 데이터의 위치를 포함한 자료구조를 추가로 생성해 빠르게 조회할 수 있도록 돕는 기능을 합니다. 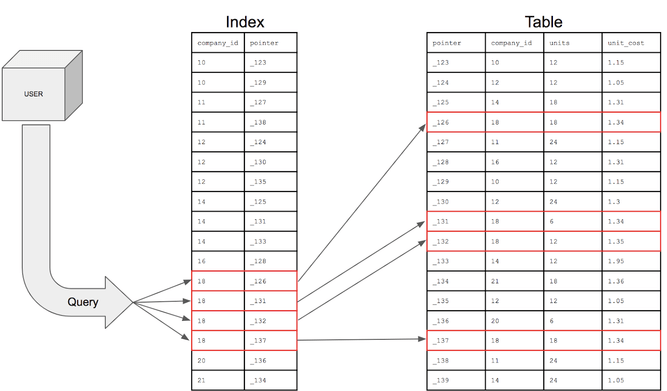
-
인덱스 생성 쿼리 (참고)
- 생성 : CREATE INDEX 인덱스명 ON 테이블명 (컬럼명);
- 사용 : from 테이블명 use index (인덱스명)
-
인덱스 작동 과정 설명
- 일단, 인덱스가 생성되어, 검색할 때 Where조건에서 인덱스 컬럼으로 접근하면
- 옵티마이저가 판단해서 생성된 인덱스를 탑니다.
- 이후 인덱스에 저장된 데이터의 물리적 주소로 가서 데이터를 가져옵니다.
-
인덱스의 장단점
- 인덱스를 사용하면 흔히 검색 속도가 향상된다고 알고있지만,
- "인덱스의 손익분기점"이라고 해서, 전체 데이터의 10~15% 이하의 데이터를 처리하는 경우에만 효율적이고,
- 그 이상의 데이터를 처리할 땐 Full scan이 더 효율적입니다.
- 또한, 삽입, 삭제, 업데이트 시 인덱스 테이블도 업데이트 해야하므로 성능 저하
- DB의 약 10%의 저장공간을 필요로 합니다.
-
인덱스를 사용하면 좋은 경우는 무엇이 있는지
- Where, Order by에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
- Insert, Update, Delete가 자주 발생하지 "않는" 컬럼
-
인덱스 자료구조 종류
- B+tree, Hash 인덱스
-
B+tree 인덱스 설명 (기존에 썼던걸 이거로 바꾸자-이게 더 깔끔)
- B+tree는 자식 노드가 2개 이상인 B-tree를 개선시킨 자료구조입니다.
- B+tree는 모든 노드에 Value값이 저장된 B-tree와 다른 특성을 가집니다.
- B+tree는 리프노드에만 인덱스(key)와 함께 Value값을 가지며, 나머지 노드는 데이터를 위한 인덱스(key)값만을 갖습니다.
- 그리고 B+tree는 리프노드가 LinkedList로 연결되어있습니다.
-
Hash 인덱스 설명 (기존에 썼던거에 추가)
- 데이터를 해싱해 <key, value>로 저장하는 자료구조로,
equal 비교를 통해 매우 빠른 검색을 지원합니다. (시간복잡도는 O(1)) - 하지만, "값을 변형"해서 인덱싱하기 때문에, 어떤 데이터의 "일부"가 포함된 데이터를 찾고자 할 때 해시인덱스를 사용할 수 없습니다.
-> ex) 'database'가 인덱싱 테이블에 해싱된 값으로 저장되었는데, 인덱스 테이블에서 'base'가 들어간 데이터 찾는다 할 때 불가능!
- 데이터를 해싱해 <key, value>로 저장하는 자료구조로,
-
DB에서 왜 index를 생성하는데 B+tree를 사용하는지? (중요)
- DB에선 "부등호를 이용한 순차 검색"이 자주 발생될 수 있습니다.
- 이런 이유로 B-tree 구조를 확장해, 리프노드들을 LinkedList로 연결해서 순차검색이 용이하도록 만들어 사용하는 것입니다.
-
Hash 인덱스보다 B+tree를 사용하는 이유
- SELECT와 같은 검색질의의 조건에는 부등호(><)도 자주 사용됩니다.
- Hash인덱스는 이퀄("=")연산에 특화되어있기 때문에 부등호연산이 자주 사용되는 DB의 인덱스로 사용하기에 적합하지 않습니다.
-
B+tree가 B-tree보다 항상 좋다고 할 수 있는가?
- No, B-Tree는 데이터가 각 노드에 존재하기 때문에, 리프노드까지 가지 않아도 원하는 결과를 찾을 수 있다.
- 이러한 경우엔 무조건 리프노드까지 가야하는 B+tree보다 B-tree가 더 좋을 수도 있습니다.
-
Where절에서 인덱스 적용하면 효율적인 이유
- 인덱스 테이블은 정렬된 상태로 저장되기 때문에, Where절 조건에 맞는 데이터를 빠르게 검색할 수 있습니다.
- 구체적으로, 테이블의 데이터는 삽입된 순서대로 저장되어 있습니다.
- Where절을 통해 데이터를 검색할 때, 처음부터 끝까지 다 풀스캔하여 검색 조건과 맞는지 비교하는 과정이 필요합니다.
- 인덱스 테이블은 정렬되어있기 때문에 이러한 불필요한 과정을 제거합니다.
-
Order By절에서 인덱스를 적용하면 효율적인 이유
- Order By절은 굉장히 부하가 많이 걸리는 작업으로 알고 있습니다.
- 1차적으로 메모리에서 정렬이 이루어지고, 메모리보다 큰 작업이 필요하다면 Disk I/O도 추가적으로 발생하기 때문입니다.
- 하지만 인덱스를 사용하면 Order By에 의한 정렬과정을 피할 수 있습니다.
옵티마이저와 실행계획 그리고 쿼리 작동과정
-
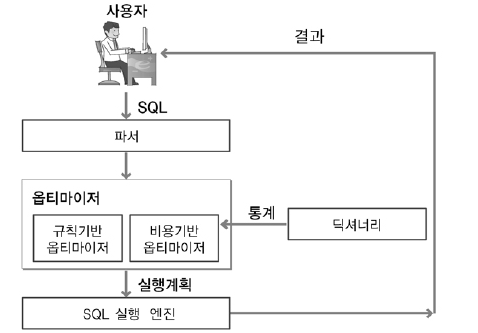
옵티마이저란
- 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성하는 DBMS의 핵심 엔진입니다.
- 규칙 기반 옵티마이저와 비용 기반 옵티마이저가 있습니다.
- 추가 설명 : https://coding-factory.tistory.com/743
-
쿼리 작동 과정 설명 (매우중요)
- DBA가 SQL을 실행하면 옵티마이저에서 해당 쿼리에 대한 "여러가지 실행계획"을 세웁니다.
- 여러 실행계획에 대해 예상 비용을 산정한 수, 각 실행계획을 비교해서 최고 효율을 갖는 실행계획을 판별하고, 그 실행계획에 따라 쿼리를 수행합니다.
-
규칙 기반 옵티마이저 설명 (RBO 설명 - Ranking)
- 실행 속도가 빠른 순으로 규칙을 세우고, 우선순위가 높은 실행 계획을 수행합니다.
- 규칙이 정해져있기 때문에 실행계획을 미리 예측하고, DBA가 원하는 대로 실행계획이 세워지도록 유도할 수 있지만,
- 데이터가 몇 개 없을 경우, Full Scan이 빠를 수 있는데, Index를 타버린다는 등의 비효율적인 실행 계획이 도출될 수 있습니다.
-
비용 기반 옵티마이저 설명 (CBO 설명 - Cost)
- 옵티마이저에서 실행계획을 세운 뒤, 비용이 가장 적게 나온 실행계획을 수행합니다.
- CBO는 비용을 예측하고자 인덱스, 컬럼 등 다양한 통계정보를 활용합니다.
- 통계정보가 없는 경우, 비효율적인 실행계획을 생성할 수도 있습니다.
-
통계정보란
- 테이블 전체 행의 개수, 컬럼 내부 Null값의 분포도 등
- 링크 : https://coding-factory.tistory.com/743
정규화
-
정규화가 뭔가요? <중요중요>
- 잘못 설계된 관계형 스키마를 분해하면서 올바른 스키마로 만드는 과정으로
- RDB에선 중복을 최소화히기 위해 데이터를 구조화하는 작업입니다.
- 링크 : https://youtu.be/pMcv0Zhh3J0
-
정규화의 장단점
- 데이터 중복을 제거해서 Anomaly 발생을 방지하지만,
- 스키마를 분해하기 때문에, 많은 JOIN이 필요해서 검색 성능을 저하시킬 수 있습니다.
-
단점에서 미루어보았을 때, 어떤 상황에서 정규화를 해야되나? 단점에 대한 대응책은?
- 데이터의 중복이 많이 발생하는 상황에서 정규화를 사용해야합니다.
- 하지만, select같은 쿼리에서 join이 많이 발생해 성능저하가 나타날 경우 "반정규화"를 수행해야합니다.
-
Anomaly가 뭔가요? (이상이란?)
- 정규화를 하지 않아서, 데이터가 불필요하게 중복되어 발생하는 현상입니다.
- 삽입이상, 삭제이상, 갱신이상이 있습니다.
-
Anomaly 종류 각각 설명 (삽삭갱)
- 삽입이상 : 데이터 삽입할 때, 원하지 않는 데이터도 같이 삽입되는 등의 문제
- 삭제이상 : 한 데이터만 삭제할 때, 그 데이터가 포함된 튜플 전체가 삭제되어 원하지 않는 정보 손실히 발생하는 문제
- 갱신이상 : 튜플의 값을 갱신할 때, 일부 튜플의 정보만 갱신되어 일관성이 없어지는 등의 모순이 생기는 문제
-
함수적 종속성이란
- 함수적 종속성이란, X와 Y를 임의의 컬럼집합이라 할 때,
- X값이 Y값을 유일하게 결정한다면 "X는 Y를 함수적으로 결정한다(X->Y)"고 합니다.
-
1NF
- 릴레이션의 모든 "도메인이 원자값"으로만 되어있는 정규형입니다.
- 즉, 복합 애트리뷰트, 다중값 애트리뷰트 등 비원자적인 애트리뷰트는 허용하지 않는 릴레이션 형태를 말합니다.
-
2NF
- 1NF를 만족하면서, 기본키가 아닌 모든 속성이 기본키에 완전함수종속을 만족하는
- 완전 함수종속이란, X->Y라고 가정했을 때, X의 어떠한 애트리뷰트라도 제거하면 더이상 함수적 종속성이 성립하지 않는 것을 의미합니다.
-
3NF
- 2NF를 만족하면서, 기본키가 아닌 모든 속성이 기본키에 이행종속되지 않는 것을 만족하는
- 즉, X->Y, Y->Z일 때, X->Z를 만족하지 않아야
-
그 이후 정규화들
- BCNF : 결정자이면서 후보키가 아닌 것을 제거
- 4NF : 다치종속 A->>B가 성립하는 경우, 모든 속성이 A에 함수적 종속관계를 만족하는
- 5NF : 릴레이션 R의 모든 조인종속이 R의 후보키를 통해서만 성립되는
- 관계 데이터베이스 설계의 목표는 각 릴레이션이 3NF(or BCNF)를 갖게 하는 것이다.
-
반정규화란 (De-normalization)
- 정규화된 엔터티,속성,관계에 대해 성능향상, 단순화를 수행하기 위해 중복, 통합, 분해 등을 수행
- 중복으로 인해 무결성이 깨질 수도 있지만
-> Disk I/O를 감소시키고, 긴 조인 쿼리문으로 인한 성능 저하를 해결함 - 링크 : 링크 : https://youtu.be/SS6H2whbfwc
-
테이블 반정규화 ~> sqld내용들로 추가
- 테이블 병합
- 테이블 분할
- 테이블 추가 (중복 테이블 추가, 통계 테이블 추가, 이력 테이블 추가, 부분 테이블 추가)
-
컬럼 반정규화
- 중복컬럼 추가
- 파생컬럼 추가
- 이력 테이블 추가
-
관계 반정규화
- 중복관계를 추가
트랜잭션
-
DB의 트랜잭션의 의미가 뭔지 아는지, 그리고 언제 주로 사용하는지 아시나요? p371<중요>
- 트랜잭션이란 논리적인 기능을 수행하여, DB의 “상태”를 바꾸는 작업단위입니다.
- 트랜잭션이 시작되면, DB의 데이터를 메모리에 올려서 처리하다가
Commit이 완료되면 처리한 내용을 디스크에 저장합니다. - 그래서 Commit하지 않고 DBMS를 종료하면 작업한 내용이 디스크의 DB에 반영X 종료
-
트랜잭션의 특성을 설명해주세요. p371
- Atomicity(원자성)
-> 트랜잭션 내 모든 명령은 완벽히 수행되거나 전혀 수행되지 않아야 합니다.
=> 즉, 완벽히 끝나지 않고, 하나라도 오류가 있으면 전부 취소되어야 합니다. - Consistency(일관성)
-> 트랜잭션이 완료되면, 트랜잭션 수행 전과 수행 후 상태가 같아야 합니다.(도메인 등) - Isolation(독립성) ★
-> 둘 이상의 트랜잭션이 동시에 병행 실행될 경우, A트랜잭션이 B트랜잭션에 영향X
=> 즉 A가 완전히 완료될 때까지 B에서 A의 수행결과를 참조할 수 없습니다. - Durability(지속성)
-> 성공적으로 끝난 트랜잭션 결과는 시스템이 고장나도 영구적으로 반영되어야 합니다.
- Atomicity(원자성)
-
COMMIT과 ROLLBACK을 설명해보세요. p436 예제 이해
- Commit : 트랜잭션이 성공적으로 끝나면, DB가 일관성을 갖기 위해
변경된 모든 내용을 DB에 반영하는 명령어입니다. - Rollback : Commit되지 않은 모든 변경된 내용을 취소해 DB를 이전상태로 돌리는 명령어
- SavePoint : Rollback할 위치를 지정하는 명령어입니다.
- Commit : 트랜잭션이 성공적으로 끝나면, DB가 일관성을 갖기 위해
-
Auto Commit 기능이 뭔지 아나요?
- Commit을 쓰지 않아도, DML문(update, insert 등)이 완료되면 자동으로 Commit해주는
-> 그래서 코테 5번에 2번에서 x=1 그대로 출력된 것(오토커밋이면 10이된다.)
- Commit을 쓰지 않아도, DML문(update, insert 등)이 완료되면 자동으로 Commit해주는
-
repeatable read isolation이 뭔가
- 근데 트랜잭션의 독립성에 의하면 ᄄᆞ로따로 아닌가??? 이거 찾아봐야할 듯?
-
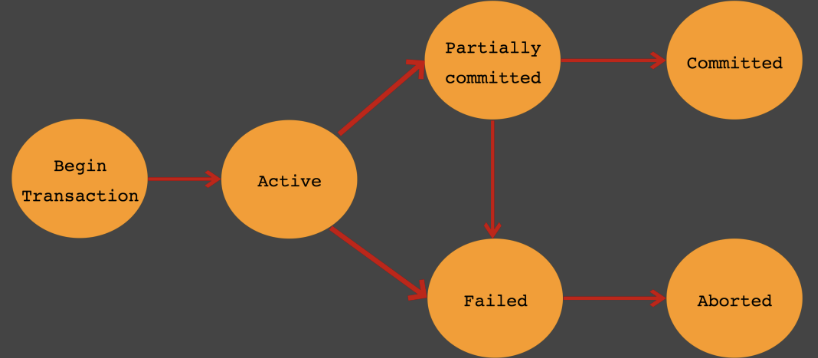
트랜잭션의 상태 설명
- Active : 트랜잭션이 실행중인 상태
- Partially Committed : 트랜잭션의 Commit명령이 도착한 상태로, Commit이전 sql문이 수행되고, commit만 남은 상태
- Committed : 트랜잭션이 정상적으로 완료된 상태
- Failed : 트랜잭션이 실패한 상태로, 더이상 정상적으로 진행할 수 없는 상태
- Aborted : 트랜잭션치 취소되고, 트랜잭션 실행 이전 데이터로 돌아간 상태
-
Partially Committed와 Committed 상태의 차이점
- Commit요청이 들어오면, 트랜잭션은 Partial Commited 상태가 됩니다.
- 이후, Commit을 문제없이 수행할 수 있으면 Committed 상태로 바뀌고
- 오류가 발생하면 Failed 상태로 바뀝니다.
lock과 교착상태
- 교착상태 설명 (Dead lock 설명)
- “Dead Lock”이라고도 하며, 프로세스가 자원(테이블 또는 행)을 얻지 못해 다음 처리로 못넘어가는
- 어떤 A라는 트랜잭션이 특정 자원의 Lock을 획득했는데,
다른 B 트랜잭션이 A가 소유한 Lock에 대한 요청을 할 경우, 아무리 기다려도 상황이 바뀌지 않는 상태 - 복수의 트랜잭션을 사용하다보면 교착상태가 발생할 수 있다 => 카카오 코테 문제에서 이걸 놓친듯
-
교착상태 예 (이해용)
- 트랜잭션에서 갱신연산(Insert, Update, Delete)를 실행하면 Exclusive Lock을 획득한다.
- A트랜잭션이 테이블1의 첫 번째 행의 Lock을 얻고,
B트랜잭션이 테이블2의 첫번째 행의 Lock을 얻었다고 했을 때, - 두 트랜잭션이 commit되지 않고 서로의 첫 번째 행에 대한 Lock을 요청하면 Deadlock이 발생한다
-
교착상태 발생 조건 (Dead lock 발생조건) <상,점,비,순 으로>
- 교착상태는 한 시스템 내에서 “상호배제, 점유대기, 비선점, 순환대기” 네 조건이 동시에 성립할 때 발생합니다.
- 참고 링크 : https://chanhuiseok.github.io/posts/cs-2/ https://ardor-dev.tistory.com/44
- 교착상태 해결법은, 대표적으로 예방기법, 회피기법, 검출 및 회복 기법이 있음
-
상호 배제 (Mutual exclusion) - 예방
- 한번에 한 프로세스만 자원을 사용할 수 있어야 한다는 조건입니다. (상호 배제하여)
-> 해결방법 : 한번에 여러 프로세스가 공유자원을 사용할 수 있게 처리하면 됩니다. (좋은건 나눠)
- 한번에 한 프로세스만 자원을 사용할 수 있어야 한다는 조건입니다. (상호 배제하여)
-
점유 대기 (Hold and wait) - 예방
- 최소한 하나의 자원을 점유하고 있다면,
다른 프로세스에 할당된 자원을 추가로 점유하기 위해선 대기해야 한다는 조건입니다.
-> 해결방법 : 프로세스가 실행되기 전에 필요한 모든 자원을 할당해 처리하면 됩니다.
- 최소한 하나의 자원을 점유하고 있다면,
-
비선점 (No preempthon) - 예방
- 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없어야 한다는 조건입니다.
-> 해결 방법 : 프로세스가 자원을 점유한 상태에서 다른 자원을 기다리지 못하게 처리
- 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없어야 한다는 조건입니다.
-
순환 대기 (Circular wait) - 예방
- 대기 프로세스의 집합이 순환 형태로 자원을 대기하고 있어야 한다는 조건입니다.
-> 해결방법 : 대기하는 프로세스들이 순환 형태를 이루지 못하도록 처리
- 대기 프로세스의 집합이 순환 형태로 자원을 대기하고 있어야 한다는 조건입니다.
-
교착상태 회피
- 자원을 할당할 때, 미리 할당될 자원의 수를 조절하여 분배해 교착상태를 피하는 방법
-
교착상태 검출과 회복
- 운영체제가 프로세스의 작업을 관찰하면서 교착상태 발생 여부를 계속 주시하고,
교착상태를 유발한 프로세스는 강제종료시키는 방법 - 예방은 어렵고, 회피는 구현할 수 있으나 자원을 낭비
- 따라서 가장 현실적인 방법이 교착상태를 검출하고 회복하는 방법입니다.
- 운영체제가 프로세스의 작업을 관찰하면서 교착상태 발생 여부를 계속 주시하고,
-
Lock 이란
- 잠금은 여러 커넥션에서 동시에 동일한 자원을 요청할 경우 순서대로 한 시점에는 하나의 커넥션만 변경할 수 있게 해주는 역할을 한다.
- 여기서 자원은 레코드나 테이블을 말한다.
- Shared lock과 Exclusive lock이 있습니다.
-
Shared lock (s)과 Exclusive lock (x) 설명
- Shared lock : read에 대한 lock으로, 일부 select에서 read작업을 할 때 lock을 건다.
- Exclusive lock : write에 대한 lock으로, update, delete 등 쿼리를 수행할 때 lock을 건다.
-
lock을 거는 규칙 (참고 이해용)
1) 여러 transaction이 동시에 한 row에 S lock을 걸 수 있다. 즉 여러 transaction이 동시에 한 row를 읽을 수 있다.2) 문제는 s lock 상태에서 다른 transaction이 x lock을 시도할 수 없다는 것이다. 즉 update, delete 등을 할 수 없다.
3) 또한 x lock이 걸려있는 row에는 다른 transaction이 s lock, x lock 을 걸 수 없다. 다른 transaction이 수정하거나 삭제하고 있는 row는 읽기, 수정, 삭제가 모두 불가능하다.
정리하자면 S lock의 경우 같은 row에 접근이 가능하지만 X lock이 걸린 row는 접근 불가능하며, S lock이 걸린 row에 X lock을 수행할 수 없다.
트랜잭션 격리수준(isolation)
-
참고링크 1 : https://nesoy.github.io/articles/2019-05/Database-Transaction-isolation
-
트랜잭션의 격리수준(isolation)이란 <중요>
- 동시에 여러 트랜잭션이 처리될 때,
- A 트랜잭션에서 변경하거나 조회하는 데이터를 B 트랜잭션이 접근할 수 있는지 없는지를 결정하는 것
- Read UnCommitted, Read Committed, Repeatable Read, Serializable이 있다
- 동시에 여러 트랜잭션이 처리될 때,
-
부정합 문제란
- 더티 리드, Non-Reapeatable Read, Phantom Read 총 3가지가 있습니다.
-
Read UnCommitted 설명
- 한 트랜잭션의 변경된 내용을 커밋이나 롤백과 상관 없이 다른 트랜잭션에서 읽을 수 있는 격리 수준
- Dirty Read 같은 문제가 발생하므로, 권장하지 않는 방식
-
Dirty Read 문제란
- 트랜잭션이 완료되지 않았는데 다른 트랜잭션에서 접근할 수 있게되는 현상
- 해결 방법 : 언두 영역을 사용하여 커밋되기 이전 데이터만을 다른 트랜잭션에게 보여준다.
-
Read Committed 설명 (그림으로 이해하면 쉬움)
- Oracle DBMS에서 기본적으로 사용되는 격리수준
- 다른 트랜잭션을 통해 데이터가 변경되었어도, Commit이 완료된 데이터만 다른 트랜잭션에서 조회 가능한 격리수준
- Commit되지 않은 값을 가져올 수 있는 이유는, 실제 테이블 값을 가져오지 않고, Undo 영역에 백업된 레코드에서 값을 가져온다.
- 구체적으로, A트랜잭션과 B트랜잭션이 있을 때, A가 update문(= x lock)을 수행해서 한 행을 변경했음. 이때 commit은 하지 않았음. B는 A가 업데이트했던 행을 읽고자 할 때, commit되기 전(=Undo), 즉 변경되기 전의 데이터를 읽어오게 됨
- A가 Commit한 이후에, B가 똑같은 행을 읽는다면, Commit된 데이터를 읽어오게 됨
- Dirty Read 같은 문제가 발생하지 않음!!
- Non-Reapeatable Read 문제 발생
-
Non-Reapeatable Read 문제란
- 한 트랜잭션에서 동일한 select문을 실행하면, 항상 같은 결과를 보장해야하는 Reapeatable Read 정합성에 어긋나는 문제
- B트랜잭션이 어떤 행을 select한 결과가 "A가 커밋하기 전과 후"에 달라짐
- 해결 방법 : Reapeatable Read 격리보다 높은 격리 수준을 사용한다.
-
Reapeatable Read 설명
- MySQL에서 기본적으로 사용되는 격리수준이다.
- 언두(Undo) 영역에 백업된 이전 데이터를 통해 트랜잭션 내에서는 동일한 결과를 보여 주도록 보장하여 Non-Reapeatable Read 문제를 해결
- Phantom Read 문제 발생
-
Phantom Read 문제란
- select ... for update 같은 Exclusive lock을 걸 때, 다른 트랜잭션에서 수행한 변경 작업으로 인해 레코드가 보였다가 안보였다가 하는 현상
- 해결 방법 : SERIALIZABLE 격리 수준을 사용하거나, 레코드 락과 갭 락을 합친 넥스트 키 락을 사용
-
Serializable 설명
- 한 트랜잭션을 다른 트랜잭션으로부터 완전히 분리하는 격리 수준
- 모든 부정합 문제 해결
-
Undo 로그 설명 (언두 로그)
- 데이터를 변경했을 때, 변경되기 전 데이터를 보관하는 곳
NoSQL
-
NoSQL에 대해 설명해보세요 ( https://youtu.be/xkCeakMCKHc )
- Not Only SQL의 약자로, SQL을 보완한다는 의미를 가지고 있습니다.
- NoSQL은 스키마가 없어서 데이터를 조회하고 삽입하는 속도가 빠릅니다.
- 또한 대량의 분산 데이터를 저장하는데 특화되어있습니다.
-
SQL과 NoSQL의 차이에 대해 설명해보세요
-
스키마가 있냐 없냐 (스키마란 데이터를 저장하는 규칙)
-> RDB는 정해진 스키마에 따라 테이블에 저장됩니다.
-> NoSQL은 정해진 스키마가 없습니다. -
관계가 있냐 없냐
-> RDB는 A스키마에서 B스키마를 참조할 수 있는 관계가 있음
-> NoSQL은 관계가 없이, 모두 저장함 (참조관계 상관없이) -
그래서!! <핵심 여기만 발표>
-> RDB는 스키마가 명확하게 정의되어 데이터 무결성을 보장하지만 덜 유연
복잡한 관계 때문에 join을 많이 사용하고, 검색 속도 느려짐
-> No는 스키마가 없어서 유연하고, 관계가 없어 검색 속도가 빠름
데이터가 여러 컬렉션에 중복될 수 있어, 삽/삭/갱 시 모든 컬렉션 수정
-
.
