시작하며
오늘은 새로운 맥북으로 처음 듣는 수업이었다. 그동안 커널이 터져버리던 무거운 작업들이 바로 돌아가는 것도 좋았지만 다른 사람들은 10분 걸리던 작업이 1분도 안 돼서 완료되는 성능이 당황스러울 정도로 좋았다.
합성곱 신경망
MLP 이미지 학습의 한계
- 행렬을 벡터로 평탄화하는 과정에서 이미지의 공간적 구조가 완전히 사라짐
- 서로 이웃한 픽셀과 멀리 떨어진 픽셀이 같은 차원의 입력값으로 취급
- 픽셀 간 구조적 위치 관계를 학습할 수 없음
- 이미지의 크기가 커질수록 가중치의 개수가 급격히 증가
- 위치 정보가 중요한 이미지 인식 문제에서는 구조적인 한계
합성곱 신경망의 입력 데이터 형태
- 합성곱 신경망에서는 입력 이미지를 평탄화하지 않음
- 입력 이미지의 공간 구조를 보전하기 위해 4차원 텐서(배치, 채널, 높이, 너비)로 모델에 전달
- 합성곱 층과 맥스 풀링 층을 모두 통과한 뒤 완전연결층에 입력 → 1차원 벡터로 변환
합성곱 신경망 대표 모델
| 모델명 | 제안 주체 | 발표연도 | 핵심 아이디어 | 주요 특징 |
|---|---|---|---|---|
| AlexNet | 토론토 대학 연구진 | 2012 | GPU 기반 CNN, ReLU | 이미지 인식 문제에서 CNN 성능을 입증한 최초 모델 |
| VGGNet | Visual Geometry Group | 2014 | 합성곱을 깊게 반복 | 구조가 단순하여 CNN 기본 구조 설명에 최적화된 모델 |
| Inception(GoogLeNet) | 2014 | 다중 스케일 합성곱 병렬 처리 | 다양한 크기의 여러 특징을 동시에 추출 가능한 모델 | |
| ResNet | Microsoft Research | 2015 | 잔차 연결(skip connection) | 아주 깊은 CNN 학습을 가능하게 한 모델 |
| EfficientNet | 2019 | 깊이, 너비, 해상도 균형 확장 | 성능과 효율을 함께 고려한 최신 모델 |
VGGNet의 Conv - Conv - Pool 구조
- 입력(1 x 28 x 28)
- 첫 번째 특성맵(32 x 28 x 28) : Conv + ReLU
- 32 : 필터 수
- 원본 크기와 동일한 특성맵 생성
- 두 번째 특성맵(32 x 28 x 28) : Conv + ReLU
- 첫 번째 특성맵을 바탕으로 특성 추출
- 맥스 풀링(32 x 14 x 14)
- 1/4로 압축
합성곱 신경망의 핵심 개념 : 지역 연결
- 이미지에서 가까운 픽셀끼리는 강하게 연관되고, 멀리 떨어진 픽셀은 약한 연관을 가지는 성질을 활용
- 작은 필터로 가까운 주변만 보고, 해당 영역의 특징을 추출
- 작은 영역만 관찰하므로 지역적인 패턴 학습 가능
- 경계, 모서리, 질감 등을 자동으로 학습
합성곱 신경망의 핵심 개념 : 가중치 공유
- 전체 이미지에 동일한 가중치를 반복적으로 적용 → 가중치 공유
- 필터는 이미지 안 어느 위치에 있든 동일한 패턴을 탐지
- 다층 퍼셉트론에 비해 파라미터 수가 급격히 감소
- 이미지의 공간 구조를 유지하므로 위치 변화에 강한 모델 구조를 형성
합성곱 연산의 개념
- 합성곱 연산은 입력 이미지의 일정 영역과 작은 필터를 겹쳐가며 계산을 수행하는 방식
- 특성맵에서 큰 값을 갖는 위치는 필터와 잘 맞는 패턴이 존재한다는 것
- 하나의 필터는 하나의 특정 패턴을 감지
- 학습 과정에서 데이터에 맞게 자동으로 결정
흑백 이미지로 합성곱 연산
- 합성곱 연산에서 사용되는 커널은 입력 채널 수와 동일한 깊이를 가져야 함
- 흑백 이미지에 사용되는 커널의 형태는 (1, k, k)
- 일반적으로 k는 3으로 설정
- 커널은 이미지의 국소적인 영역을 순차적으로 이동
- 각 위치에서 픽셀값과 커널의 곱을 계산하여 하나의 특성 값을 생성
- 이러한 결과를 모아 하나의 새로운 특성맵을 형성
- 여러개의 커널을 사용하면 다양한 국소 패턴을 동시에 학습
- 공간 구조를 유지한 상태에서 특징을 추출
패딩
- 패딩 : 이미지 테두리에 0을 채워 넣어 입력 공간 크기를 확장하는 방법
- 합성곱 연산을 할 때마다 출력 크기가 계속 줄어드는 문제 방지
스트라이드
- 스트라이드 : 필터가 이미지를 훑을 때 얼만큼 건너뛸 것인지를 나타내는 값
합성곱 신경망 핵심 용어 정리
| 구분 | 의미 | 형태 | 예시 (MNIST) |
|---|---|---|---|
| 채널 | 이미지 또는 특성맵의 깊이 차원 | 1채널 | |
| 커널 | 합성곱 연산에 사용되는 작은 가중치 행렬 | ||
| 필터 | 입력 채널 전체를 동시에 참조하는 커널 집합 | ||
| 필터 수 | 합성곱 층에서 사용하는 필터의 개수 | 32개 | |
| 특성맵 | 필터 적용 결과로 생성되는 출력 채널 |
합성곱 신경망 연산 과정
- 첫 번째 합성곱 연산은 원본 이미지로부터 단순한 국소 패턴을 학습해 특징의 기본 요소를 추출
- 두 번째 합성곱 연산은 더 복잡하고 추상적인 특징을 형성
- MNIST 이미지(1 x 28 x 28)에 첫 번째 합성곱 연산을 적용
- 특성맵의 형태(32 x 28 x 28) → 두 번째 합성곱 층의 입력으로 사용
- 특성맵의 형태(32 x 28 x 28) → 두 번째 합성곱 층의 입력으로 사용
- 두 번째 합성곱에서 사용되는 각 필터는 32 x 3 x 3 구조를 가짐
- 모든 채널을 동시에 참조하여 합성곱 연산을 수행
- 계산된 결과는 채널 방향으로 합산되어 하나의 특성맵을 형성
맥스 풀링
- 맥스 폴링 : 특성맵의 공간 크기를 줄이는 연산
- 폴링 커널의 각 영역에서 가장 큰 값만 선택하여 다음 층으로 전달
- 이 과정에서 학습되는 가중치는 없으며, 단순한 규칙 연산만을 수행
- 일반적으로 2x2 행렬 사용, 스트라이드 2로 설정 → 가로 1/2, 세로 1/2씩 감소
합성곱 신경망의 수용 영역
- 특정 뉴련이 입력 이미지에서 영향을 받는 영역의 크기를 의미
- 층이 깊어질수록 이전 층에서의 출력이 다시 입력으로 사용 → 간접적으로 영향을 받는 입력 영역은 점점 넓어짐
- 이러한 이유로 깊은 층의 뉴런일수록 더 넓은 수용 영역을 가짐
- 이미지의 더 큰 구조적 패턴을 인식
- 합성곱 신경망은 깊어질수록 전체 구조를 이해하는 방향으로 확장
합성곱 신경망 모델 생성
import torch.nn as nn- 첫 번째 합성곱 층의 필터는 (1, 3, 3)이고, 두 번째 합성곱 층의 필터는 (32, 3, 3)
- 각 합성곱 층의 필터는 각 32개씩 모인 집합
model = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(in_features=6272, out_features=256),
nn.ReLU(),
nn.Linear(in_features=256, out_features=10)
).to(device)- 손실 함수 및 최적화 알고리즘 생성
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)- 모델 학습
trainer = Trainer(
model=model,
criterion=criterion,
optimizer=optimizer,
train_loader=train_loader,
test_loader=test_loader,
flatten=False # 합성곱 신경망의 입력은 평탄화 하지 않음
)
history = trainer.fit(n_epochs=10)오분류된 표본의 인덱스 생성
- 시험셋의 예측 확률, 예측값 및 실제값 생성
y_prob, y_pred, y_true = trainer.predict_loader(data_loader=test_loader)- 오분류된 표본의 인덱스 생성
mis_index = torch.where(y_true.ne(y_pred))[0]Grad-CAM
합성곱 신경망 XAI의 필요성
- 딥러닝 모델은 높은 예측 정확도를 보이지만 왜 그런 예측을 했는지는 설명하기 어려움
- 어느 부분을 보고 판단했는지
- 객체 자체를 보고 판단했는지 아니면 배경이나 잡음을 사용했는지
- Grad-CAM(Gradient-weighted Class Activation Map)
- 모델이 특정 클래스를 예측할 때 어떤 이미지 영역에서 중요한 역할을 했는지 히트맵으로 시각화
Grad-CAM의 핵심 아이디어
- 클래스 점수의 영향도를 사용
- 클래스 c의 점수 를 k번째 특성맵 의 각 위치 에 대해 미분한 영향도
- 이 값은 특성맵의 위치 에 존재하는 특징이 클래스 c의 예측 점수에 얼마나 영향을 주는지 나타냄
Grad-CAM 계산
- 특성맵 채널의 중요도를 계산하기 위해 각 위치의 기울기를 공간 방향에 대해 평균
- 채널 k가 클래스 c를 예측하는데 얼마나 중요한지를 의미
- 채널 중요도와 특성맵의 가중합으로 계산
- ReLU를 사용하는 이유는 예측할 때 긍정적으로 기여한 영역만 강조하기 위함
Grad-CAM 히트맵 생성 과정
- 마지막 합성곱 층의 특성맵 추출
- 예측 클래스 점수에 대한 기울기 계산
- 각 채널의 기울기를 전체 위치에서 평균하여 채널별 중요도 계산
- 채널 중요도로 특성맵의 가중합 계산
- ReLU 적용하여 예측 클래스 점수를 증가시킨 방향의 기여만 남김
- 히트맵을 원본 이미지 위에 겹쳐서 시각화
Grad-CAM 객체 생성
- GradCAM 객체를 생성한 이후에는 모델 예측을 할 수 없으니 이전에 완료해야 함
from torchcam.methods import GradCAM- 모델 평가 모드로 전환
model.eval()- 마지막 합성곱 층을 타겟 레이어로 설정
target_layer = model[2]- Grad-CAM 객체 생성
gradcam = GradCAM(model=model, target_layer=target_layer)Grad-CAM 히트맵 시각화
- 밝은 영역은 로짓을 높이는 데 크게 기여한 위치
- 어두운 영역은 점수에 거의 기여하지 않는 위치
- 모델이 클래스를 예측할 때 어떤 위치를 중요하게 사용했는지 직관적으로 확인 가능
- 예측 클래스 기준으로 계산 → 정답 특징을 강조하는 것으로 오해 X
예측 클래스 기준 히트맵 시각화
- 시험셋에서 오분류된 첫 번쩨 인덱스 생성
index = mis_index[0]- 표본의 이미지 텐서와 라벨 생성
image, label = test_mnist[index]- 이미지 텐서로 로짓 생성
- 모델 입력 형태에 맞추기 위해 배치 차원 추가
logits = model(image.unsqueeze(dim=0).to(device))- 로짓으로 예측값 생성
pred = logits.argmax(dim=1).item()- 예측 클래스 기준 Grad-CAM 계산
cam_pred = gradcam(class_idx=pred, scores=logits)- 히트맵 제목에 추가할 실제값과 예측값의 타겟 범주 생성
true_label = test_mnist.classes[label]
pred_label = test_mnist.classes[pred]- 원본 이미지 텐서 시각화
plt.imshow(X=image.squeeze(), cmap='gray')
plt.title(label=f'index : {index}, true : {true_label}', fontsize=8)
plt.axis('off')
plt.show()
- 예측 클래스 기준 히트맵 시각화
plt.imshow(X=image.squeeze(), cmap='gray')
plt.imshow(X=cam_pred[0].squeeze().cpu().numpy(), cmap='jet', interpolation='bilinear', alpha=0.5)
plt.title(label=f'index : {index}, pred : {pred_label}', fontsize=8)
plt.axis('off')
plt.show()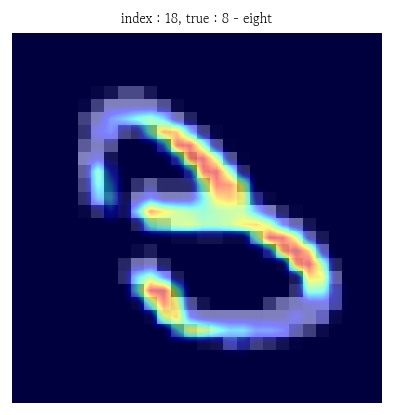
실제 클래스 기준 히트맵 시각화
- 이미지 텐서로 로짓 생성
logits = model(image.unsqueeze(dim=0).to(device))- 실제 클래스 기준 계산
cam_true = gradcam(class_idx=label, scores=logits)- 실제 클래스 기준 히트맵 시각화
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
axes[0].imshow(X=image.squeeze(), cmap='gray')
axes[0].imshow(X=cam_pred[0].squeeze().cpu().numpy(), cmap='jet', interpolation='bilinear', alpha=0.5)
axes[0].set_title(label=f'index : {index}, pred : {pred_label}', fontsize=8)
axes[0].axis('off')
axes[1].imshow(X=image.squeeze(), cmap='gray')
axes[1].imshow(X=cam_true[0].squeeze().cpu().numpy(), cmap='jet', interpolation='bilinear', alpha=0.5)
axes[1].set_title(label=f'index : {index}, true : {true_label}', fontsize=8)
axes[1].axis('off')
plt.show()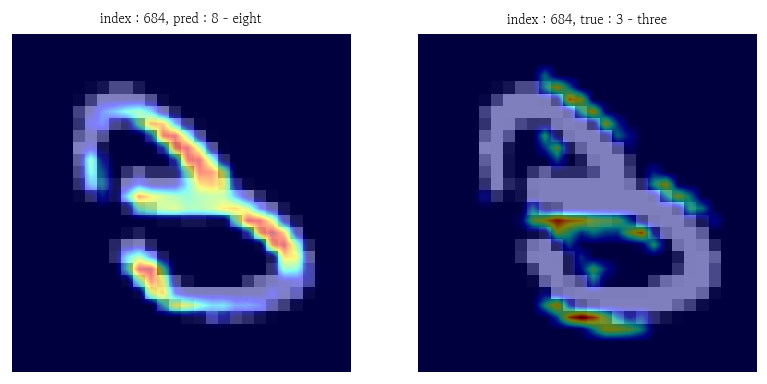
Grad-CAM 히트맵 해석 방법
- 밝은 영역 → 로짓을 높이는 데 크게 기여한 위치
- 모델이 어디를 보았는지 보여주지만 그것이 올바른 근거였음을 보장하지는 못함
- 객체의 핵심 부분이 강조되면 비교적 타당한 근거로 판단했을 가능성 있음
- 배경, 경계, 잡음, 일부 획이 강조되면 부적절한 단서에 의존했을 가능성 있음
Grad-CAM 시각화 함수 생성
def plot_gradcam_sample(dataset, index, model, gradcam, ax=None, cmap='jet', interpolation='bilinear'):
image, label = dataset[index]
image = image.to(device)
logits = model(image.unsqueeze(dim=0))
pred = logits.argmax(dim=1).item()
cam_pred = gradcam(class_idx=pred, scores=logits)
true_label = dataset.classes[label]
pred_label = dataset.classes[pred]
if ax is None:
ax = plt.gca()
ax.imshow(X=image.squeeze().detach().cpu(), cmap='gray')
ax.imshow(X=cam_pred[0].squeeze().detach().cpu(), cmap=cmap, alpha=0.5, interpolation=interpolation)
ax.set_title(f'index : {index}\ntrue : {true_label} | pred : {pred_label}')
ax.axis('off')여러 표본에 대한 히트맵 시각화
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(12, 6))
for ax, index in zip(axes.flatten(), mis_index[:10]): # axes 2차원 배열이기 때문에 flatten 필요
plot_gradcam_sample(dataset=test_mnist, index=index.item(), model=model, gradcam=gradcam, ax=ax)
plt.tight_layout()
plt.show()
타겟 레이어에 등록된 hook 제거
- hook : forward, backward 실행 시 자동 호출되는 함수
target_layer._forward_hooks
# OrderedDict([(0,
# functools.partial(<bound method _CAM._hook_a of GradCAM(target_layer=['2'])>, idx=0)),
# (1,
# functools.partial(<bound method _GradCAM._hook_g of GradCAM(target_layer=['2'])>, idx=0))])- Grad-CAM 객체의 사용이 끝난 후에는 hook을 제거
- 타겟 레이어의 forward hook과 backward hook을 제거하면 모델 예측이 가능해짐
gradcam.remove_hooks()target_layer._forward_hooks
# OrderedDict()Grad-CAM 계산 값이 모두 0인 경우
- 영향도가 매우 약하거나 음수 위주인 경우
- 그 클래스를 양의 방향으로 설명할 특징을 거의 사용하지 않았다는 의미
Grad-CAM을 통해 확인할 수 있는 것
- 모델이 이미지의 어느 위치를 근거로 예측했는지
- 객체의 핵심 구조를 사용했는지 확인
- 배경, 잡음, 일부 경계 등 부적절한 단서에 의존했는지 확인
컬러 이미지 전처리 : CIFAR-10
컬러 이미지 데이터의 특징
- 컬러 이미지는 RGB 세 개의 채널로 구성
- 하나의 이미지가 3차원 텐서 형태로 표현
- 일반적으로 텐서의 형태는 (C, H, W)
- 컬러 이미지는 픽셀 하나당 3개의 값을 가지므로 입력 데이터의 차원이 크게 증가
- 딥러닝 모델에 입력하기 전 0~1 범위 실수로 정규화하는 것이 일반적
CIFAR-10 훈련셋 준비
train_cifar10 = CIFAR10(root='../../data', train=True, transform=None, download=True)- 데이터 클래스 확인
type(train_cifar10.data)
# numpy.ndarray- 데이터 형태 확인
train_cifar10.data.shape
# (50000, 32, 32, 3)- 첫 번째 원소 할당
image = train_cifar10.data[0]- 형태 확인
image.shape
# (32, 32, 3)훈련셋 타겟 확인
- 타겟의 첫 번째 원소 확인
train_cifar10.targets[0]
# 6- 타겟 범주 확인
train_cifar10.classes
# ['airplane',
# 'automobile',
# 'bird',
# 'cat',
# 'deer',
# 'dog',
# 'frog',
# 'horse',
# 'ship',
# 'truck']- 타겟 범주별 정수 인덱스 확인
train_cifar10.class_to_idx
# {'airplane': 0,
# 'automobile': 1,
# 'bird': 2,
# 'cat': 3,
# 'deer': 4,
# 'dog': 5,
# 'frog': 6,
# 'horse': 7,
# 'ship': 8,
# 'truck': 9}훈련셋 이미지 렌더링
- 처음 9개 이미지 렌더링
for i in range(9):
plt.subplot(3, 3, i+1)
image = train_cifar10.data[i]
plt.imshow(X=image)
target = train_cifar10.targets[i]
plt.title(label=f'{train_cifar10.classes[target]}')
plt.axis('off')
plt.tight_layout()
plt.show()
채널별 평균과 표준편차 계산
- 훈련셋을 실수형 텐서로 변환 후 0~1 범위로 스케일링
pixels = torch.from_numpy(train_cifar10.data).float() / 255- 형태 확인
pixels.shape
# torch.Size([50000, 32, 32, 3])- 채널별 평균 확인
pixels.mean(dim=(0, 1, 2))
# tensor([0.4914, 0.4822, 0.4465])- 채널별 표준편차 확인
pixels.std(dim=(0, 1, 2))
# tensor([0.2470, 0.2435, 0.2616])이미지 정규화의 역할
- 정규화는 입력값의 분포를 일정한 범위로 맞추어 손실 함수의 기울기 계산과 빠른 학습 수렴을 도움
- 이미지 데이터를 텐서로 변환 → 픽셀 값 0~255 정수 0~1 범위의 실수로 스케일링
이미지 변환 객체 생성
- 채널별 평균과 표준편차 리스트 생성
cifar10_avg = [round(v.item(), 4) for v in pixels.mean(dim=(0, 1, 2))]
cifar10_std = [round(v.item(), 4) for v in pixels.std(dim=(0, 1, 2))]- 정규화를 포함한 이미지 변환 객체 생성
transform = transforms.Compose(
transforms=[
transforms.ToTensor(),
transforms.Normalize(mean=cifar10_avg, std=cifar10_std)
]
)- 정규화 포함한 훈련셋 생성
train_cifar10 = CIFAR10(root='../../data', train=True, transform=transform)훈련셋 이미지 확인
image, label = train_cifar10[0]- 클래스 확인
type(image)
# torch.Tensor- 형태 확인
image.shape
# torch.Size([3, 32, 32])역정규화 함수 생성
image = image * std + avg: 이미지 역정규화image = image.clamp(min=0, max=1): 범위를 0~1 실수로 제한image = (image * 255).round().to(torch.uint8): 255를 곱하고 정수 변환하면 원본에 가까워짐
def denormalize_tensor(image, avg, std):
avg = torch.tensor(data=avg, device=image.device).reshape(3, 1, 1)
std = torch.tensor(data=std, device=image.device).reshape(3, 1, 1)
image = image * std + avg
image = image.clamp(min=0, max=1)
image = (image * 255).round().to(torch.uint8)
return image- 이미지 역정규화 후 형태 변환
image = denormalize_tensor(image=image, avg=cifar10_avg, std=cifar10_std)
image = image.permute(1, 2, 0)
image.shape
# torch.Size([32, 32, 3])- 역정규화 이미지 렌더링
plt.imshow(X=image)
plt.axis('off');
시험셋 준비
test_cifar10 = CIFAR10(root='../../data', train=False, transform=transform)마치며
코드를 실행하면서 수업을 들으니 확실히 더 재밌게 배우는 것 같다. 어려운 내용도 많지만 이미지 모델들을 다루는게 꽤나 재밌어서 괜찮은 것 같다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis