TIL
1.250707 [ Day 1 ] - Git (1)

오늘부터 코딩온 재생에너지 IoT 개발자 과정 3기 교육이 시작되었다. 앞으로 교육 때 배웠던 내용들을 정리하거나, 책이나 영상 등을 통해 얻은 개발과 재생에너지 관련 지식들을 간단하게 블로깅할 생각이다.교육을 받으며 아이패드로 필기 하고, 집에 와서 필기 내용을 보면
2.250708 [ Day 2 ] - Git (2)
어제에 이어 Git에 대해 공부를 했다.먼저 GitHub에 원격 저장소를 만든 뒤 로컬 저장소와 연결하는 연습을 했다. 파일을 생성해 push하고, clone과 pull을 사용해 백업하는 과정을 반복해서 연습했다.자주 사용하는 Git 명령어git init : 현재 디렉
3.250709 [ Day 3 ] - Git (3)
오늘은 Git에 대한 마지막 시간이었다. 아직 많은 기능을 다루지는 못했지만, 가장 많이 사용하고 당장 필요한 기능을 숙달하기 위해 오늘도 여러 번 반복해서 연습했다.저장소의 기존 코드에서 갈라져 나온 하나의 독립적인 작업 공간으로, 여러 브랜치에서 작업 후 다시 합치
4.250710 [ Day 4 ] - Python (1)
오늘부터 드디어 파이썬 수업을 시작했다. 파이썬을 다뤄보기 전 파이썬이라는 프로그램에 대한 이해를 키우기 위해 '프로그래밍 언어란 무엇인가' 에 대해 먼저 공부했다.컴퓨터에게 작업을 지시하기 위해 사람이 사용하는 형식화된 언어프로그램 : 컴퓨터에서 실행될 때 특정 작업
5.250711 [ Day 5 ] - Python (2)
파이썬 수업 2일차이자 첫 주의 마지막 수업날이다. 오늘도 크게 어려운 내용은 없었지만, 양이 많아서 정리하고 복습할 내용이 꽤 많았다.먼저 파이썬의 가상환경에 대해 간단히 설명을 들었다. 가상환경이란 독립된 작업 환경으로, 프로젝트마다 사용하는 도구나 버전이 다를 수
6.250714 [ Day 6 ] - Python (3)
교육 2주차의 첫날이다. 이번 주부터는 새로 옮긴 교육장에서 수업이 진행되었고, 지난 시간에 배웠던 input과 split에 대한 복습과 실습으로 수업을 시작했다. 리스트를 배우기 전에 먼저 이터러블 (iterable), 컬렉션 (collection), 시퀀스 (seq
7.250715 [ Day 7 ] - Python (4)
오늘은 지금까지 배운 내용을 바탕으로 미니 프로젝트를 진행했다. 프로젝트 주제는 텍스트 기반 미니 게임 만들기였다. 일주일 동안 던전에서 생존하는 게임으로, 각종 이벤트를 통해 아이템을 얻고 (예/아니오) 선택에 따라 진행 루트가 달라지는 방식의 게임을 만들어 보았다.
8.250716 [ Day 8 ] - Python (5)
오늘은 지난 시간에 배운 리스트에 대해 이어서 공부했다. 인덱스와 슬라이싱을 사용한 실습 문제를 풀어봤는데, 그 과정을 통해 배운 내용이 인상 깊었다.특히, 슬라이싱을 이용해 원하는 구간만 역순으로 출력하는 방법이 흥미로웠다.또한, 슬라이싱을 사용할 때 주의사항도 배웠
9.250717 [ Day 9 ] - Python (6)
오늘은 range를 제외한 다양한 이터러블 자료형과 반복문의 기초에 대해 배웠다. 이전에는 프로그래머스 같은 코딩 테스트 문제를 풀 때마다 반복문이 자주 등장했지만, 아직 배우지 않은 부분이라 항상 넘어갈 수밖에 없었다. 이제 조금만 더 배우면 드디어 반복문 문제들을
10.250718 [ Day 10 ] - Python (7)
오늘은 어제 배운 for문에 이어 range 자료형까지 배웠다. range를 활용한 복잡한 for문 알고리즘 문제를 풀다 보니 약간의 뇌정지가 왔지만, 원리를 이해하고 나니까 조금씩 풀이법이 보여 재미있었다.먼저 for문에서 딕셔너리를 활용하는 방법부터 시작하였다.딕셔
11.250721 [ Day 11 ] - Python (8)
오늘은 또 다른 반복문인 while 반복문에 대해 공부했다. for문과 거의 유사하지만 반복 횟수의 차이가 있었다.조건이 True 인 동안 코드를 반복하는 반복문조건이 False 면 반복을 멈춤반복 횟수가 정해지지 않았을 때 사용조건 : 참/거짓을 구분할 수 있는 문장
12.250722 [ Day 12 ] - Python (9)
어제에 이어 오늘도 함수에 대해 공부했다. 내용이 많아서 완벽하게 이해하려면 복습을 철저히 하고, 매개변수와 인자를 활용하는 방법도 다양해서 연습을 많이 해봐야 익숙해질 것 같다.위치 인자 (Positional Arguments)인자의 순서대로 매개변수에 대응되는 방식
13.250723 [ Day 13 ] - Python (10)
어제 여러 가변 인자 관련 문제를 풀어보면서 사용법에 어느 정도 감이 잡힌 것 같다.오늘은 재귀 함수와 람다 함수에 대해 배웠는데, 역시 개념적으로 복잡한 느낌이 들어 충분한 복습이 필요할 것 같다.자기 자신을 호출하는 함수반드시 기본 조건 (종료 조건) 이 있어야 함
14.250724 [ Day 14 ] - Python (11)
오늘은 클래스에 대해 자세히 배웠다.처음 설명을 들었을 때는 모든 내용이 새롭고 개념도 복잡하게 느껴져 잘 따라갈 수 있을지 걱정됐지만, 막상 실습을 통해 직접 사용해보니 정리했던 개념과 코드가 잘 맞아떨어져 의외로 쉽게 적응했다.OOP : 객체를 기반으로 프로그램을
15.250725 [ Day 15 ] - Python (12)
이번 주는 정말 빠르게 지나간 것 같다. 저번 주 회고 글을 작성한 지 얼마 되지 않은 것 같은데, 벌써 또 일주일이 흘러버렸다. 시간을 더 잘 관리하고 아껴 써야겠다는 생각이 든다.오늘은 클래스의 상속에 대해 배웠다. 상속은 지금까지 클래스를 공부해온 이유라고 해도
16.250728 [ Day 16 ] - Python (13)
새로운 한 주가 시작됐다. 이번주에는 드디어 파이썬의 기본기 파트가 끝나고 데이터 분석 파트에 진입한다고 한다. 파이썬도 어려운 내용은 거의 끝났고 여러 기능들에 대한 사용법 정도만 남아 저번주 보다는 한결 수월했던 하루였다.여러 기능들이 뭉쳐진 하나의 .py 파일모듈
17.250729 [ Day 17 ] - Python (14)
어제에 이어 남은 모듈에 대해 마저 배웠다.시간의 측정, 지연, 변환과 같은 시간 관련 기능 제공시간 측정파이썬 인터프리터와 관련된 다양한 기능 제공sys.argv 활용운영체제와 상호작용 할 수 있도록 도와주는 기능 제공여러 모듈에 어떤 기능들이 있는지 한번씩 사용해보
18.250730 [ Day 18 ] - Python (15)
어제부로 파이썬 파트가 모두 끝나 오늘은 지금까지 배운 내용을 모두 사용하여 지난번과 비슷한 게임 만들기 프로젝트를 했다. 여러 모듈과 패키지로 기능을 분리하여 불러오고, 반복문과 조건문 등 지금 머릿속에 있는 모든 기능을 사용하여 만들어 보았다. 교육 시간 동안은 대
19.250731 [ Day 19 ] - NumPy (1)
오늘부터 데이터 분석을 위한 파트가 시작됐다. 그 첫 번째로 다양한 데이터 분석과 AI 생태계의 기반인 NumPy와, 앞으로 배울 많은 패키지를 관리하고 가상 환경 구축을 도와주는 Anaconda에 대해 간단히 배웠다.데이터 분석, 머신 러닝 등에 사용하는 여러가지 패
20.250801 [ Day 20 ] - NumPy (2)
어제에 이어 NumPy의 기본 사용법과 인덱싱, 슬라이싱에 대해 배웠다. 인덱싱과 슬라이싱은 기본적으로 리스트의 인덱싱, 슬라이싱과 비슷했지만 다차원 배열에 유용한 추가 기능이 많이 있었다.파이썬 시퀀스와 동일하게 0부터 시작하는 인덱스 사용기본적인 문법은 동일다차원
21.250804 [ Day 21 ] - NumPy (3)
새로운 한 주가 시작되었다. 주말 동안 NumPy-100이라는 레퍼지토리에 있는 문제를 풀어보았는데, 아직 수업에서 배우지 않은 내용이 더 많아서 풀 수 있는 문제는 많지 않았다. 수업 시간에는 NumPy의 기본기 정도만 다루기 때문에 다른 기능들이나 심화 과정은 따로
22.250805 [ Day 22 ] - NumPy (4)
오늘은 NumPy의 마지막 수업이었다. 처음에는 행렬이라는 낯선 개념에 다양한 기능들까지 배우느라 따라가는 것만으로도 버거웠는데, 이제는 행렬과 NumPy에 꽤 익숙해진 것 같다. 특히 어려웠던 axis 개념도 이제는 충분히 이해하고 활용할 수 있을 것 같다.물론 Nu
23.250806 [ Day 23 ] - Pandas (1)
오늘부터 Pandas 파트가 시작되었다. 이번 주 안에 Pandas를 모두 끝내야 해서 오늘 수업은 정말 역대급으로 빨랐다. 필기하는 것만으로도 벅차서 순식간에 하루가 지나갔다.내용도 많은데다 중간중간 복잡한 개념들도 나와서, 다음 수업 전에 꼭 한 번 더 보면서 정리
24.250807 [ Day 24 ] - Pandas (2)
오늘은 Pandas 2일차다. 오늘도 상당히 많은 내용을 다뤘지만, 어제 복습을 충분히 해서 그런지 아니면 오늘 내용이 상대적으로 쉬워서 그런지, 어제보다는 훨씬 수월하게 느껴졌다. 오늘 수업이 끝나고 Pandas를 공부할 수 있는 사이트를 추천해주셔서, 빨리 블로깅을
25.250808 [ Day 25 ] - Pandas (3), Matplotlib
시작하며 오늘은 Pandas를 사용해서 CSV 파일과 Excel 파일을 불러오거나 저장하는 기능과 데이터를 시각화할 수 있는 Matplotlib에 대해 배웠다. 매일 배열값들만 보다가 그래프와 차트로 구현된 데이터를 보니 꽤 흥미로웠다. csv 파일 불러오기 데이
26.250811 [ Day 26 ] - Seaborn, BeautifulSoup (1)
오늘도 Seaborn으로 만든 많은 그래프 이미지를 정리하면서 블로그를 쓰는 순간이 걱정됐다. 일단 이미지 세팅을 따로 저장해 두고 계속 복사하면서 작성해봐야겠다.Matplotlib 기반의 시각화 라이브러리복잡한 그래프를 간단한 코드로 작통계적 데이터 시각화에 특화(P
27.250812 [ Day 27 ] - BeautifulSoup (2), Selenium, Folium
오늘로 데이터 분석 파트도 모두 끝났다. 데이터 크롤링 부분은 HTML 지식이 어느 정도 있어야 하는 영역이라 지금까지 배운 내용 중에 가장 어렵게 느껴졌다.그래도 실습을 여러 번 반복하면서 어느 부분을 가져와야 크롤링이 가능할지 어느 정도 감을 잡을 수 있었다. 하지
28.250813 [ Day 28 ] - Project (1)
오늘부터 그동안 배운 내용들을 활용한 팀 프로젝트가 시작되었다. 첫날인 오늘은 팀원들과 함께 주제를 선정하고, 전체적인 일정과 가이드라인 및 규칙을 정했다.노션을 꾸준히 사용해온 덕분에 이제는 필요한 기능들의 템플릿을 손쉽게 만들 수 있게 되었다. 칸반보드, 각종 데이
29.250814 [ Day 29 ] - Project (2)
오늘은 프로젝트 2일차로, 어제 구상하고 작성했던 프로젝트 계획서를 발표하고 피드백을 받는 시간을 먼저 가졌다. 계획서 작성과 일정 및 마일스톤 설계, 팀 룰 설정 등 전체적인 계획서 작성은 잘했지만, 주제가 너무 광범위해서 조금 더 세부적인 주제 설계가 필요하다는 피
30.250815 - Project (3)
오늘은 광복절로 수업이 없어서 집에서 개별 작업을 진행했다. 월요일부터 본격적인 데이터 분석을 시작할 예정이라, 오늘은 필요한 데이터를 수집하고 분석하기 편하도록 정리하는 사전 준비 작업을 진행했다.다행히 이번 프로젝트의 핵심 데이터를 쉽게 확보할 수 있었다. 해당 데
31.250818 [ Day 30 ] - Project (4)
오늘부터 본격적인 데이터 분석을 시작했다. 지난번 데이터 정리에 이어 연도별 / 지역별 발전량 데이터 정리를 주로 진행했다.지난번 설비용량 데이터를 받았던 사이트에서 함께 받은 발전량 데이터라 설비용량을 정리했던 코드들을 복사해서 조금만 수정하면 될 줄 알았는데, 확인
32.250819 [ Day 31 ] - Project (5)
오늘은 주로 정리해둔 데이터들을 필요에 따라 재구성하고, 재구성한 데이터들을 그래프나 지도로 시각화하는 작업을 메인으로 했다.이전에 미리 데이터 전처리와 데이터 형식을 모두 통일해두었기 때문에 재구성 자체는 매우 쉬운 작업이었다. 원하는 데이터를 컬럼, 인덱스를 사용해
33.250820 [ Day 32 ] - Project (6)
오늘은 기존 데이터 처리 및 시각화가 생각보다 빨리 끝나서 더 추가할 내용이 무엇이 있을지 생각해보다가, 설비이용률과 전국 일사량 데이터를 비교해보면 좋을 것 같다는 생각이 들어서 데이터 수집부터 시작해보았다.일사량 데이터는 주로 기상청의 기상자료개방포털에서 찾아서 사
34.250821 [ Day 33 ] - Project (7)
오늘은 기존 데이터를 바탕으로 나타낸 결과를 시각화하는 데 집중해서 이제 점점 끝이 보이기 시작했다.이번 프로젝트의 최종 결과는 태양광 설비이용률과 일사량 데이터를 바탕으로 효율이 좋고 앞으로 유망해 보이는 지역을 찾아내고, 추가적으로 설치하면 좋을 것 같은 지역을 선
35.250822 [ Day 34 ] - Project (8)
오늘은 기존 데이터들을 정리하고 주로 PPT 제작을 하였다. 지금까지 수집하고 분석한 데이터들을 발표 자료에 적합한 형태로 통일성 있게 꾸몄다. 어제 만들어두었던 PPT 틀에 맞춰 하나씩 내용을 추가해갔다.테스트 코드 등 불필요한 데이터들이 있는지 다시 한번 정리한 뒤
36.250823 - Project (9)
오늘은 데이터 정리를 거의 마무리했고, 내일 PPT와 발표 자료를 정리하면 드디어 첫 프로젝트가 끝난다.어제 말했듯이 각자 작업하고 정리했던 데이터와 코드를 합쳐서 데이터 관련 파일, 시각화 관련 파일 등으로 구분해서 정리를 진행했다.작은 데이터 파일을 가지고 각자 파
37.250825 [ Day 35 ] - Project (10)
오늘은 무사히 프로젝트 발표를 마치고 GitHub README를 작성한 것에 대해 블로그를 써보려고 한다.프로젝트 발표가 모두 끝나고 3시간 정도 시간이 남았는데, 오늘은 따로 수업이 없다고 해서 그동안 시간이 없어 작성하지 못했던 README를 작성해보았다.GitHu
38.250826 [ Day 36 ] - HTML (1)
오늘부터 웹 개발의 기본적인 내용들을 배우기 시작했다. HTML, CSS, JavaScript와 함께 React도 기본적인 내용 정도만 다뤄본다고 한다.화면 (클라이언트) : 프론트 앤드서버 : 백 앤드데이터베이스 : 백 앤드HTML : 기본 구조 생성을 위한 언어CS
39.250827 [ Day 37 ] - HTML (2), CSS (1)
오늘은 예비군 훈련으로 인해 수업을 듣지 못해서 수업 PPT만 가지고 AI의 도움을 받아 혼자 공부해보았다. 다행히 그렇게 어려운 내용은 없었던 것 같아서 NotebookLM과 AI 학습 모드를 사용하니 금방 이해할 수 있었다.표를 만들 때 사용하는 태그<tabl
40.250828 [ Day 38 ] - CSS (2)
어제 혼자서 공부했던 내용 중 놓친 내용은 딱히 없었다. 그래서 무사히 오늘 진도를 따라갈 수 있었다.오늘은 주로 CSS의 선택자에 대해 공부했는데, 선택자의 종류도 너무 많고 다 비슷하면서 디테일하게 다른 부분이 있어서 너무 복잡해서 어떻게 쓰나 싶었다. 하지만 막상
41.250829 [ Day 39 ] - CSS (3)
어제가 CSS 마지막 내용인 줄 알았는데 오늘도 CSS만 배웠다. 아직 CSS에 대한 내용이 한참 더 남은 것 같다.역시 디자인 관련 언어다 보니 상당히 내용이 많은 것 같다. JavaScript와 React도 많이 궁금한데 비중이 많이 줄어들 것 같아서 조금 걱정이다
42.250901 [ Day 40 ] - CSS (4), JavaScript (1)
드디어 CSS가 끝나고 오늘부터 JavaScript를 배우기 시작했다. JavaScript의 첫인상은 기대와는 상당히 많이 달랐다. CSS처럼 웹 개발에서 기능적인 부분만 담당하는 언어인 줄 알았는데 Python처럼 범용 프로그래밍 언어였다. 하지만 급하게 만들어진 언
43.250902 [ Day 41 ] - JavaScript (2)
JavaScript의 둘째 날이다. 조금씩 적응해지니까 Python과 큰 틀 자체는 다른 게 많지는 않아서 쉽게 배우고 있다. 가끔 처음 보는 기능이 있긴 하지만 '이렇게도 사용하는구나' 하고 이해하면서 넘어가니까 금방 습득하는 것 같다.JavaScript는 C를 기반
44.250903 [ Day 42 ] - JavaScript (3)
오늘도 JavaScript의 상당히 많은 내용을 배웠다. 자주 사용되는 메서드를 빠르게 살펴보고 DOM에 대해 조금 살펴보고 수업이 끝났다. DOM에 대한 기본 개념이 약간 헷갈리는 부분이 있지만 몇 번 사용해보고 복습해보면 금방 익숙해질 것 같다. 드디어 JavaSc
45.250904 [ Day 43 ] - JavaScript (4)
오늘은 JavaScript를 배우면서 가장 어려운 개념들을 배운 것 같다. 정규 과정이 아니라 짧은 시간 안에 HTML, CSS, JavaScript, React를 간단하게나마 배우고 있다 보니 수업 진도가 매우 빠른 템포로 진행된다. 그런데 내용 자체도 복잡한 내용이
46.250905 [ Day 44 ] - JavaScript (5), React
오늘부로 꽤 길었던 웹 파트가 모두 끝났다. 처음 웹에 대해 배운다고 했을 때는 길어도 4일 정도 간단한 구현을 배우지 않을까 싶었는데, 생각보다 많은 내용을 다뤄 꽤 길어졌던 것 같다.오늘은 React에 대해 조금 배우고 React를 사용해서 간단한 웹을 만들어 배포
47.250908 [ Day 45 ] - AI, OpenCV (1)
오늘부터 AI와 OpenCV 파트가 시작됐다. AI에 대한 기초적인 지식부터 OpenCV에 대한 기본적인 기능 등을 다뤄보았다. OpenCV가 macOS에서 최적화가 안 되어 있는지 초반 설치 및 설정 부분에서 에러가 많아서 시간을 많이 잡아먹었다. 수업을 진행하면서도
48.250909 [ Day 46 ] - OpenCV (2)
어제에 이어서 OpenCV의 기본적인 사용 방법들에 대해서 공부했다. 이미지의 색을 변경하고 여러 도형을 그리는 등 NumPy를 사용해서 이미지의 데이터를 변경하는 과정을 계속 배우는 중이다.OpenCV = B G R 순서이미지에 색칠하기이미지 자르기얕은 복사 : 메모
49.250910 [ Day 47 ] - OpenCV (3)
오늘은 어제에 이어서 Pillow라는 라이브러리를 이용해서 OpenCV에 한글을 그리는 방법부터 블러, 이진화 등 약간 이론적으로 이해가 필요한 내용이 있었지만 크게 어려운 내용은 없었다. 오늘부터 어려운 내용들이 시작된다고 했는데 아직까지는 할 만한 것 같다.pip
50.250911 [ Day 48 ] - OpenCV (4)
오늘은 그동안 배웠던 OpenCV의 기능을 최대한으로 활용한 실습 문제를 하나 풀었는데 생각보다 많이 어려웠다. 크게 3가지의 기능을 구현해보는 내용이었는데, 2단계까지는 어떻게 하다 보니 구현했는데 마지막 3단계 구현을 끝내 못했다. 최종적으로 구현된 코드를 계속 보
51.250912 [ Day 49 ] - OpenCV (5)
오늘은 실습 문제를 푸는 과정과 최종 작성된 코드가 리더님께서 풀이해주신 과정과 결과에 근접했던 문제들이 많아서 어제 코드를 열심히 뜯어본 보람이 느껴졌다. 또 리스트 컴프리헨션 등의 파이썬스러운 코드를 자연스럽게 사용하고 있는 스스로를 보니까 꾸준하게 프로그래머스 문
52.250915 [ Day 50 ] - OpenCV (6)
오늘은 리더님께서 몸이 안 좋으셔서 수업 대신 OpenCV의 얼굴 인식을 이용한 여러 실습 문제를 풀어보는 시간을 가졌다.웹캠이나 CCTV영상처럼 움직이는 물건(전경)과 고정된 배경을 자동으로 구분할때 사용history=500 : 배경 학습에 사용할 프레임 수 / 값이
53.250916 [ Day 51 ] - OpenCV (7), PyTorch (1)
시작하며 오늘로 OpenCV를 마무리하고 본격적인 AI Machine Learning 파트에 들어갔다. 첫 내용으로는 PyTorch부터 시작하였다. YOLO YOLO (You Only Look Once) : 딥러닝을 활용한 객체 탐지 알고리즘 중 하나 YOLO는 매우 빠르며, GPU를 활용할 경우 초당 수십 프레임을 처리할 수 있어 실시간 객체 탐지에 ...
54.250917 [ Day 52 ] - PyTorch (2)
오늘은 오랜만에 NumPy를 배웠을 때 많이 헷갈려했던 Axis의 기억이 다시 떠오른 하루였다. PyTorch에도 dim이라는 텐서의 행과 열을 지정하는 속성이 있어서 조금 어지러웠지만 몇 번 다시 보니 금방 감을 잡았다.스칼라 연산연산의 결과가 원본을 변경하지는 않음
55.250918 [ Day 53 ] - Machine Learning (1)
오늘부터 Machine Learning 파트에 들어가서 AI부터 Machine Learning, 인공신경망 등 관련 이론 학습을 진행하였다. 수학적 이론이 많이 나와서 다소 어려웠지만 미리 공부를 어느 정도 해둔 덕분에 잘 이해할 수 있었던 것 같다.입 / 출력 정의모
56.250919 [ Day 54 ] - Machine Learning (2)
Machine Learning 파트의 2일차이다. 이제 Machine Learning의 기본적인 개념, 손실 함수의 최솟값을 구하기 위해 가중치 Weight와 편향 Bias를 기계가 스스로 업데이트해나가는 것이 확실히 어떤 느낌인지 알게 되었고, 그 과정에서 사용되는
57.250922 [ Day 55 ] - Machine Learning (3), PyTorch (3)
오늘로 Machine Learning에 대한 이론 수업은 모두 끝났고, PyTorch를 사용해서 직접 모델을 만들어보는 시간을 가졌다. 이론으로만 들었던 내용을 코드로 구현해가니까 상당히 재미있었고, 이론을 알고 있으니 코드를 작성하면서 어떤 기능인지 바로바로 알 수
58.250923 [ Day 56 ] - PyTorch (4)
오늘부로 AI 파트가 모두 끝났다. 어제에 이어서 여러 모델들을 구현해보았다. 단일 선형 회귀처럼 간단한 모델은 상대적으로 쉬워서 이해하면서 코드 구현을 했었는데, 복잡한 모델을 구현하니까 이해는 둘째 치고 코드를 따라 치는 것도 벅찼던 것 같다. 코드를 계속 보면서
59.250924 [ Day 57 ] - Project (1)
오늘부터 새로운 팀 프로젝트가 시작되었다. 그동안 배웠던 OpenCV와 PyTorch를 사용해서 AI 모델을 학습시키고, 그 모델을 사용해서 어떠한 결과를 도출하는 것이 이번 프로젝트의 핵심이다.이번 프로젝트의 우리팀 주제는 재활용 쓰레기의 사진 또는 영상을 인식하고
60.250925 [ Day 58 ] - Project (2)
오늘은 필요한 데이터를 수집하고 정리하는 데 주로 시간을 보냈다. 이후에 머신러닝을 해야 하다 보니 재활용 쓰레기를 학습시키기 위한 이미지 데이터가 상당히 많이 필요했다. 일단 간단하게 종이, 비닐, 캔, 플라스틱, 유리, 스티로폼 이렇게 6종으로만 분류해봤는데도 데이
61.250926 [ Day 59 ] - Project (3)
모델을 학습시키기 위해서는 데이터 폴더 구조가 깔끔하게 정리되어 있어야 하는데, 구한 데이터들은 쓸데없는 폴더들이 너무 많아서 폴더 구조 정리가 시급했다. 하지만 수작업을 하기에는 폴더가 적어도 몇천 개는 넘었기에 폴더 구조를 통일할 수 있는 코드를 구상하면서 시작했다
62.250927 - Project (4)
어제에 이어서 학습시켜둔 테스트 모델을 API로 웹과 연동시켜보려고 한다.미리 만들어둔 웹 사이트에 result 값 전달 uvicorn main:app --reload API 실행 후 웹 사이트에서 이미지 입력AI 모델과 웹 연결 테스트 완료테스트로는 이진 분류만 진행
63.250929 [ Day 60 ] - Project (5)
오늘부터 본격적인 기능 구현 단계에 들어갔다. 크게 API와 DB 구현이 필요한 백엔드 파트, 웹 디자인 및 구현이 필요한 프론트엔드 파트, 그리고 AI 모델의 파이프라인을 구축하고 학습을 진행하는 머신러닝 파트 이렇게 3가지로 역할을 분담하여 작업을 시작했다. 그중에
64.250930 [ Day 61 ] - Project (6)
오늘은 기존에 테스트로 만들어둔 이항 분류 모델을 6개의 클래스를 가진 다항 분류 모델로 수정한 뒤, 그에 맞춰 파이프라인도 약간 수정해서 클래스당 약 1000개 정도의 데이터를 학습시킨 프로토타입 모델을 만들었다. 일단은 새로운 API와 웹과의 연동을 확인해보기 위한
65.251001 [ Day 62 ] - Project (7)
오늘은 새롭게 작업한 API와 AI 모델 파이프라인을 연동시켜서 파이프라인의 response 값을 API로 받아 웹에 출력시키는 것까지 테스트하였다.이후 모든 데이터를 사용한 본격적인 모델 학습을 시작하였다. Data모든 클래스 합쳐서 약 7만장의 이미지 데이터Mode
66.251002 [ Day 63 ] - Project (8)
오늘은 어제 오랜 시간 학습시킨 모델이 과적합 의심이 들어서 과적합과 오분류 분포를 확인하기 위한 코드를 작성해보았다.결과는 역시나 문제가 있어 보였다. 가장 큰 원인은 클래스별 데이터 차이 때문인 것 같다. 그래서 연휴 동안 데이터를 변형하거나 새로운 데이터를 추가해
67.251003 - Project (9)
오늘부터 연휴가 시작됐지만, 연휴 동안 계속 프로젝트 작업을 할 예정이다. 오늘은 YOLO를 학습시키기 위한 폴더 구조 변환을 하였고, yaml 파일을 만들어서 기본적인 정보들을 저장시키는 작업을 하였다.내일은 부족한 데이터를 추가적으로 수집하고 YOLO 학습까지 진행
68.251004 - Project (10)
오늘 YOLO 학습까지 진행하는 것이 목표였는데 시간이 별로 없어서 내일로 미루게 되었다.지금 가지고 있는 데이터 중에서 2개의 클래스는 데이터 수가 매우 많고, 2개는 보통, 남은 2개의 클래스는 데이터 수가 상당히 적어서 부족한 데이터를 보충하는 작업을 하였다. 이
69.251006 - Project (11)
오늘은 YOLO 모델을 학습시키고 새로운 ResNet 모델 v2 학습을 시켰다. 그런데 12시간에 걸쳐 YOLO 학습을 시킨 뒤 테스트해봤는데, 다중 객체를 인식하지 못해서 결국 원래 사용하던 YOLO 모델을 사용하면서 재활용품에 관련된 클래스만 인식하도록 설정했다.데
70.251007 - Project (12)
어제 학습시켜둔 모델이 오늘 아침에 끝나서 일어나서 바로 테스트해봤는데 아직 성능이 조금 아쉬웠다.플라스틱이 이상하게 계속 성능이 안 나와서 학습용 데이터에서 노이즈가 많이 들어간 데이터를 직접 추린 뒤 종이와 플라스틱에는 가중치를 조금씩 더 부여하였다. 그리고 데이터
71.251008 - Project (13)
Model v3도 실패했다. 원인으로는 과도한 변형값들과 플라스틱 데이터의 근본적인 문제점으로 추측했다. 그 문제점은 플라스틱에도 종류가 매우 다양한데 세부적인 클래스들을 하나의 플라스틱이라는 클래스로 학습시키다 보니 학습이 만족스럽게 안 됐던 것 같다. 그래서 플라스
72.251009 - Project (14)
Model v4의 학습이 30시간 정도 진행 중이다. 20 Epoch 진행 중인데 아직 테스트는 안 해봤지만 v5 준비를 해둬야 할 것 같은 느낌이다. 중후반까지는 꽤 괜찮은 결과가 나오는 것 같아 보였는데 19 Epoch에서 과적합이 생겼는지 정확도가 갑자기 3%가
73.251010 - Project (15)
Model v4의 학습이 모두 끝나서 테스트해보았다. 아쉬운 부분도 있긴 했지만 플라스틱을 세부 클래스로 나눈 효과는 확실히 있던 것 같다.내일은 develop 브랜치에 모두 합친 뒤 실시간 분석 테스트를 해본 뒤, 지금까지의 기능들을 다듬는 과정을 가질 것 같다.
74.251011 - Project (16)
오늘은 모든 브랜치를 합친 뒤 기존 학습해둔 Model v4를 사용해서 테스트해보았다. 추가적으로 웹 디자인을 새롭게 꾸몄다.웹 디자인을 깔끔한 디자인으로 수정한 다음 실시간 인식 버튼과 분석 버튼을 만들고 내일 추가할 통계 탭을 추가했다. 그리고 CSS에서 hover
75.251012 - Project (17)
오늘은 실시간 인식 기능 테스트를 완료하고 통게를 위한 DB구현을 해보았다.연휴 중에 어느 정도 마무리하고 싶었지만 모델 학습이 너무 오래 걸려서 아쉬웠다. 이제 통계를 위한 웹 구현과 시각화 그래프를 만들면 끝날 것 같다. 이후에는 Oracle Cloud 서버를 사용
76.251013 [ Day 64 ] - Project (18)
오늘은 어제에 이어 Oracle Cloud를 이용해 DB를 저장해보려 했는데, Oracle Cloud 회원가입 이슈로 인해 Turso라는 데이터베이스 서버를 사용하기로 했다. 최대 8GB의 저장 용량을 Free Tier로 사용할 수 있고, SQLite의 클라우드 버전이
77.251014 [ Day 65 ] - Project (19)
오늘은 테스트 배포를 하기 위해 Railway와 Vercel을 사용해서 각각 Backend, Frontend를 배포하여 테스트를 해 보았다.처음에는 그냥 GitHub만 연동시키면 배포는 바로 되는 거 아닌가 생각했는데, Backend를 배포시키려고 알아보는 순간 보통
78.251015 [ Day 66 ] - Project (20)
오늘은 프로젝트 중간 점검을 받고, 기간이 아직 남았으니 기능 하나 정도만 더 추가해 보라는 피드백을 받았다. 그래서 팀원들과 어떤 기능이 추가되면 좋을지 회의를 하다가, 재활용품과 재생에너지의 연관성을 설명하기 위해 사용자가 이미지를 추가해 분류하면 해당 클래스의 재
79.251016 [ Day 67 ] - Project (21)
어제 임시로 표시해 둔 지점들을 실제 지점들로 바꾸기 위해 서울의 25개 각 구별로 재활용품이 어떻게 처리되는지 조사한 뒤 해당 시설들의 위도와 경도를 찾아서 매핑해 주었다. 이후에는 각 클래스별로 배출 방법을 더 디테일하게 작성하였다.오늘 작업한 내용들을 내일 조금씩
80.251017 [ Day 68 ] - Project (22)
오늘은 추가적으로 웹에서 자동 스크롤 기능과 여러 hover 기능 및 지도 상에서의 팝업 기능을 추가한 뒤 테스트해보고 배포를 진행했었는데, 배포하니까 서버 간의 레이턴시 차이 때문인지 테스트 때는 괜찮았는데 무한 루프가 일어나는 오류가 계속 생겼다.여러 기능을 하나씩
81.251018 - Project (23)
오늘은 미리캔버스를 사용해서 팀원들과 함께 PPT를 제작하였다.기능 부분에 대한 PPT를 주로 작성하고 있는데, 먼저 프로젝트에 사용했던 언어 및 프레임워크, 라이브러리를 정리하고 머신러닝에 대한 코드와 하이퍼파라미터 수정과 학습 과정 등을 정리해서 작성하였다. 이후로
82.251019 - Project (24)
오늘은 어제에 이어서 PPT를 작성했다.백엔드 API의 전체적인 흐름 정리와 중요한 코드들을 설명하고, 프론트엔드에서는 WebRTC API를 사용한 실시간 인식 기능과 Leaflet.js를 사용한 지도 표시 기능에 대한 설명과 코드를 추가했다. 이후로는 시연 영상을 녹
83.251020 [ Day 69 ] - Project (25)
오늘은 PPT에 맞춰 대본을 작성하였다. 대본을 작성하면서 사용했던 기능들에 대한 복습과 용어들을 다시 한번 정리하였고, 세부적인 내용들도 조금 더 공부해보았다.torchvision의 이미지 분류 특화 모델잔차 학습입력과 출력 간의 차이를 학습하는 방법으로, 각 신경망
84.251022 [ Day 71 ] - SQL (1)
오늘부터 새로운 파트인 MySQL에 대해서 수업을 시작했다. 저번 프로젝트를 통해 SQLite는 어느 정도 다뤄봤지만, 조금 더 본격적으로 SQL에 대해서 공부해보고 싶었는데 마침 좋은 타이밍에 수업을 시작했다.데이터가 모이면 정보가 되고, 정보가 모이면 지식이 됨여러
85.251023 [ Day 72 ] - SQL (2)
어제 기본적인 SQL 언어와 흐름을 배우고 복습하며 조금씩 익숙해지니까 오늘은 확실히 할 만했던 것 같다.생성된 테이블의 속성과 속성에 대한 제약및 기본키 , 외래키를 변경CREATE TABLE 시 외래 키 설정ALTER TABLE 시 외래 키 추가이미 만들어진 테이블
86.251024 [ Day 73 ] - SQL (3)
오늘부터 조금씩 복잡한 내용을 배우기 시작했다. 오늘은 JOIN에 대해서 배웠는데, 처음에는 잘 이해가 안 갔지만 직접 코드를 작성하면서 사용해보니까 어느 상황에 어떻게 사용하는지 감을 잡을 수 있었다.테이블에 이미 존재하는 데이터를 수정할 때 사용WHERE절 없이 실
87.251027 [ Day 74 ] - SQL (4)
오늘은 여러 함수들을 활용해서 데이터를 간단하게 조회하고 수정해봤는데 별거는 아니지만 데이터를 다루는 게 상당히 재미있는 것 같다. 그리고 내일 Python과 MySQL을 연동하는 것을 해보면 이제 MySQL 파트도 거의 끝난 것 같다.MySQL에서 기본적으로 제공하는
88.251028 [ Day 75 ] - 신재생에너지
오늘은 신재생에너지의 기본 이론을 배우고, 약 2주 후에 시작할 다음 프로젝트 주제를 찾아보는 시간을 가졌다.신재생에너지는 신에너지와 재생에너지를 합쳐 부르는 우리나라의 용어이다.신에너지는 수소에너지, 연료전지, 석탄액화가스화처럼 기존 에너지에 새로운 기술을 더해 얻는
89.251029 [ Day 76 ] - SQL (5)
오늘은 다시 MySQL에 대해 배웠다. Python에서 MySQL을 사용하는 것부터 FastAPI를 활용해 MySQL과 FastAPI를 기본적으로 연동하는 것까지 배워보았다.PIPpip install mysql-connector-pythonCondaconda insta
90.251030 [ Day 77 ] - SQL (6)
오늘도 어제에 이어 FastAPI를 사용해서 MySQL과 연동하는 법을 공부했다.요청 데이터의 구저를 정의하고, 자동으로 유효성 검사를 해주는 도구데이터 구조를 정의하는 클래스로, 주로 요청 데이터의 구조와 타입을 명확히 지정할 때 사용튜플의 리스트 → 딕셔너리의 리스
91.251031 [ Day 78 ] - SQL (7)
오늘부로 MySQL과 FastAPI에 대한 파트가 모두 끝이났다. Integer + primary_key = AUTO_INCREMENT 자동 적용비활성화 필요 시 autoincrement=False 속성 추가main.py 또는 따로 관리 파일에 Base.metadata
92.251103 [ Day 79 ] - Arduino (1)
오늘부터 아두이노 파트가 시작되었다. 오늘은 아두이노에 대해 간단히 배우고 아두이노 키트를 사용해서 간단하게 연결 정도만 해보는 시간을 가졌다.사물 인터넷일상적인 물건이나 기기에 인터넷을 연결하여 데이터를 주고받고, 서로 통신할 수 있도록 만드는 기술AIoT : IoT
93.251104 [ Day 80 ] - Arduino (2)
오늘도 아두이노에 대해 공부했다. 아직 회로 구성이 익숙하지 않아서 많이 어렵지만, 실물로 보이는 것이 있기 때문에 재미가 있는 것 같다.PWM에서 For문 활용버튼을 누르면 전기 회로가 통하게 되는 소자플로팅 현상전기가 흐를 때, 주변의 자기장과 같은 전기 에너지 때
94.251105 [ Day 81 ] - Arduino (3)
오늘은 아두이노에서 활용할 수 있는 여러 모듈과 센서에 대해서 공부했다.디지털 핀의 전압을 매우 짧은 시간 안에 바꾸어가며 주파수에 맞는 소리를 낼 수 있도록 해줌능동 부저음이 하나밖에 없음 (On / Off)다리가 긴쪽이 + 짧은쪽이 -전원만 공급하면 바로 소리 출력
95.251106 [ Day 82 ] - Arduino (4)
오늘도 아두이노에 대해 이어서 공부했다.디지털 신호20KHz 이상의 주파수를 가진 소리인 초음파을 이용해서 앞쪽에 위치한 물체아의 거리를 인식하는 센서아날로그 신호화재 경보 장치, 가스 누설 경보기 등자이로 센서와 가속도 센서가 합쳐진 센서자이로 센서x, y, z축을
96.251107 [ Day 83 ] - Arduino (5)
이제 아두이노의 마지막 파트인 통신 파트가 시작되었다. 역시 마지막 파트다 보니 상당히 복잡한 내용이 많았다.라이브러리 설치 필요https://github.com/miguelbalboa/rfid무선 주파수 식별사물 또는 동물에 고유한 식별코드를 부여하고 이를
97.251108 - Project (1)
오늘은 프로젝트에서 사용될 두 가지의 로직 중 하나를 임시로 만들어 보았다. 아직 return 값을 리스트로 할지 딕셔너리로 할지 등 정해진 내용이 없다 보니 추후에 바뀔 수 있는 부분은 이전 프로젝트들을 거쳐오면서 배운 점과 부족하다 느꼈던 점들을 자연스럽게 많이 사
98.251110 [ Day 84 ] - Project (2)
오늘부터 본격적으로 프로젝트가 시작되었다. 주말 동안 로직 구현은 어느 정도 해두었기 때문에 오늘은 머신러닝에 필요한 데이터를 찾고 정리했다.먼저 찾고 있던 데이터는 20230101~20241231까지 시간별 서울의 태양광 발전량 데이터였다. 하지만 24년도 데이터는
99.251111 [ Day 85 ] - Project (3)
오늘은 공공데이터포털과 기상청에서 2022년의 태양광 발전량 데이터와 일사량 데이터를 추가하는 것부터 시작하였다. 23~24년도의 데이터 일부분이 없기 때문에 이후에 학습, 검증, 테스트용 데이터를 분리할 생각을 하면 조금 부족할 것 같다는 생각이 들어 추가하게 되었다
100.251112 [ Day 86 ] - Project (4)
오늘은 어제에 이어 데이터 전처리를 조금 진행하다가 아두이노 릴레이 모듈에 대해서 공부하고 테스트를 해보았다.어제에 이어서 한 시간 전 발전량과 어제 같은 시간의 발전량 컬럼을 추가하였다. 어떻게 처리를 할지 찾아보면서 공부하니까 shift() , pd.to_datet
101.251113 [ Day 87 ] - Project (5)
오늘은 데이터 전처리를 마무리하고 어떤 모델을 프로젝트에 사용할지 시계열 데이터 예측 모델을 여러 가지 찾아보면서 특징들을 공부해보았다.시계열 데이터에 강점이 있는 모델을 찾아보니 RandomForest, LSTM 정도가 괜찮아 보였다. 이전 입력값을 기억해서 다음 출
102.251114 [ Day 88 ] - Project (6)
오늘은 RandomForest, GradientBoosting, LSTM 모델들을 간단하게 테스트 해보았다.아직 테스트라서 성능 자체는 RandomForest가 가장 높게 나왔지만, RandomForest는 파인튜닝을 해보면서 테스트를 진행해봤을 때 더 이상의 성장은
103.251115 - Project (7)
오늘은 어제 테스트했던 LSTM 모델을 파인튜닝하면서 성능을 향상시켜보았다.오늘 LSTM을 다뤄보니 지금 프로젝트에는 조금 무겁다는 체감이 들었다. LSTM 모델은 복잡한 시계열 데이터에 강점이 있지만, 지금 다루고 있는 데이터는 연속적인 날짜와 시간의 데이터라서 이
104.251116 - Project (8)
오늘은 RandomForest를 3시간 뒤 예측이 가능하도록 수정하고 파인튜닝을 진행해봤다.아직 파인튜닝도 방향성 결정을 위해 느낌만 본 정도라 이후에 성능이 달라질 수도 있겠지만, 지금 단계에서는 각 모델의 특징이 드러난 결과가 나왔다고 생각한다. RandomFore
105.251117 [ Day 89 ] - Project (9)
오늘도 모델 파인튜닝을 진행하면서 전에 만들어둔 채널 확인 로직을 백엔드에 연동하는 코드를 작성하였다.API 연동 자체는 미리 작성된 다른 API router 코드를 사용해서 쉽게 작성하였다. 작성을 하면서 새롭게 팀원들과 맞춰봐야 될 부분들이 있어서 정리해두었고, 내
106.251118 [ Day 90 ] - Project (10)
오늘은 팀원들과 의논을 하여 RandomForest를 사용하기로 결정을 하고, 모델 예측 API를 작성하였다.이제 DB와 서버 구축은 거의 마무리 단계인 것 같아서 아두이노와 서버 연동 테스트를 해봐야 할 것 같다.
107.251119 [ Day 91 ] - Project (11)
오늘은 API와 DB의 보안 정보들을 env로 관리를 하였고, Postman을 사용하여 API 테스트를 진행하였다.http://localhost:5001/api/channels/availablehttp://localhost:5001/api/channe
108.251120 [ Day 92 ] - Project (12)
오늘도 새로운 API를 만들고 테스트 해본 뒤, 다른 팀원분이 만든 API와 일관성을 유지하기 위해 다르게 처리한 부분들을 통일시키는 작업을 하였다. 이후에는 DB와 API에서 불필요하거나 비효율적인 부분들을 수정한 뒤, 아두이노의 와이파이 모듈과 서버 연결 테스트를
109.251121 [ Day 93 ] - Project (13)
API가 점점 늘어날수록 코드가 길어져 효율적으로 작업할 방법이 없는지 찾아보다, service 폴더에 기능을 분리하고 실제 라우터 파일에는 엔드포인트만 작성하는 방식으로 많이 사용한다고 해서 오늘은 아두이노와 연동 API 구현과 DB 구조 변경 및 API 기능 분리
110.251122 - Project (14)
오늘도 Service로 기존 코드 기능 분리를 하고 재사용 가능한 함수가 있는 부분을 처리해주었다.이제 어느 정도 기능들은 Service로 분리해두어서 이후 새로운 엔드포인트를 구현할 때 재사용을 하면서 구현이 가능해질 것 같다.
111.251124 [ Day 94 ] - Project (15)
오늘은 미리 작성했던 API 명세서를 모두 완료해서 Postman을 사용해서 테스트해보았다.POST /api/relay/control릴레이 제어 및 DB에 거래 내역 저장TestBodyLogGET /api/relay/status현재 릴레이 채널 활성화 상태 확인Test
112.251125 [ Day 95 ] - Project (16)
오늘은 DB 테이블을 수정한 뒤 24시간 이후 데이터를 시간별 평균으로 저장하는 로직을 구현해보았다.하나를 마치면 계속 새롭게 걸리는 부분이 보여서 내일 또 API 수정을 진행한 뒤 아두이노 회로 구성을 마무리해야 될 것 같다.
113.251126 [ Day 96 ] - Project (17)
오늘은 DB 연결 및 종료 기능을 Service 파일로 분리를 하였다. 다른 기능들과 마찬가지로 분리만 하면 될 줄 알고 시작했는데, 작업을 하면서 생각해보니 연결을 하고 SQL 등 작업을 한 다음에 종료 처리를 해야 되는데 일반적인 함수로는 불가능하기에 여러 방법을
114.251127 [ Day 97 ] - Project (18)
오늘은 머신러닝 모델을 불러올 때 조금 더 효율적이고 서버가 가벼워지는 방법을 공부해보고 이후 아두이노 회로 구상을 마친 뒤, 서버를 테스트해보았다. 서버에서는 flask의 jsonify를 반환할 때 한글이 깨져서 보이는 이슈가 생겨 로그 확인용 print는 한글로 유
115.251128 [ Day 98 ] - Project (19)
시작하며 오늘은 jsonify의 에러 메시지를 영어로 수정하면서 전체적으로 로그 확인용 print도 수정을 하였다. 그리고 서버 테스트를 해보면서 지금 사용 중인 ML 모델을 사용하면 약간 무거울 것 같아서 새로 파인튜닝을 하면서 경량화를 진행했다. 또한 새롭게 필요한
116.251129 - Project (20)
어제 수업이 끝나기 전에 아두이노와 와이파이 통신을 하여 서버에서 데이터를 전달하는 테스트를 해보았는데 실패를 해서 해당 부분을 조사해보니, 이번에 사용하는 와이파이 모듈은 따로 IP를 가지고 있지 않아 서버에서 POST는 불가능하고 아두이노가 주기적으로 서버에 요청을
117.251202 [ Day 99 ] - Project (21)
오늘은 서버와 아두이노 간의 연동 문제를 해결하기 위해 이것저것 시도를 해보았다.처음에는 기존 수정을 했었던 /api/relay/control 엔드포인트를 아두이노에서 요청하면 가공해둔 JSON 값을 아두이노에서 바로 받을 수 있을 거라 생각을 했었는데 많은 문제가 있
118.251203 [ Day 100 ] - Project (22)
오늘 서버 배포와 웹 연동을 테스트해보려 했는데 서버 담당을 했던 팀원분이 안 오셔서 아쉽지만 로컬 서버와 웹 연동을 테스트해보았다.웹 연동을 테스트하는 과정에서 먼저 프론트엔드 코드를 모두 pull 해온 뒤 React에서 로컬 서버의 주소를 env 변수로 선언하여 연
119.251204 [ Day 101 ] - Project (23)
오늘은 최종 아두이노 회로 설치 및 PPT 제작을 시작하였다. 아두이노 회로를 설치하기 전 마지막으로 서버와 연동 테스트를 해보았는데, 저번 테스트 이후로 달라진 게 없는데도 이번에는 실패를 하였다.지난번 성공했을 때의 로그 메시지와 이번 메시지를 비교해보니 실패 원인
120.251205 [ Day 102 ] - Project (24)
오늘은 프론트엔드랑 백엔드, 아두이노까지 연동 테스트를 진행한 뒤 PPT를 제작하였다.프론트엔드는 아직 수정할 부분이 많이 남아있어서 잘 동작이 되는지 정도만 테스트해보았고, 서버와 아두이노는 헤더 최소화 작업을 진행한 뒤로는 파싱 이슈가 없어져서 이제는 와이파이 모듈
121.251208 [ Day 103 ] - Project (25)
오늘은 프로젝트 마지막 날이라 최종 테스트를 진행한 뒤 PPT를 제작하였다.수정된 프론트엔드와 서버, 아두이노를 연동해보았는데 오라클 클라우드가 http이고, vercel이 https라서 배포 후 연동에 이슈가 생겼다. cloudflared을 사용해서 백엔드 URL을
122.251212 [ Day 104, 105, 106 ]
교육 과정의 마지막 파트인 포항 Posco 견학을 수요일부터 금요일인 오늘까지 다녀왔다. 첫날 포항에 도착해서 숙소에 도착했는데 최고급 호텔 부럽지 않은 정도의 숙소를 제공해주셔서 Posco 담당자님께 너무너무 감사하다고 말씀드리고 싶을 정도였다. 덕분에 많은 스케줄
123.251229 [ Day 1 ] - OT, 제조업 특강
오늘부터 청년취업사관학교 새싹 과정이 시작되었다. 면접 때도 느꼈지만 가자마자 느낀 점은 시설이 너무 좋았고, 교육 환경 또한 상당히 신경을 많이 써준 게 느껴졌다.오늘은 기본적인 OT와 제조업에 관한 특강을 진행했다.기업이 제품이나 서비스를 생산하고 고객에게 제공하기
124.251230 [ Day 2 ] - SQL (1)
오늘부터 본격적인 수업이 시작되었다. 오늘과 내일은 SQL에 대한 내용을 다루고 그다음에 Python을 배울 예정이다.데이터베이스(DB)는 다양한 형태의 데이터를 체계적으로 저장하고 관리하는 데이터의 집합데이터의 형태에는 문자열, 수치형(정수, 실수), 날짜시간 데이터
125.251231 [ Day 3 ] - SQL (2)
오늘은 SQL을 마무리하고 여러 실습 문제를 풀어보았다. 데이터를 요약 → 데이터의 특징을 알 수 있음 (EDA)COUNT(필드명) : 결측이 아닌 개수 반환SUM(필드명) : 결측이 아닌 값의 합계 반환AVG(필드명) : 결측이 아닌 값의 평균 반환MAX(필드명) :
126.260102 [ Day 4 ] - Python (1)
오늘은 데이터 분석을 배우기 전 데이터에 대한 내용과 분석에 대한 내용을 배웠고, 오후에는 기본적인 파이썬을 배우기 시작했다.디지털 전환 : 디지털 기술의 발전으로 인하여 인간의 삶 전반에 영향을 미치는 변화Digitization아날로그를 디지털로 전환텍스트, 이미지,
127.260103 - SQL 총정리
오늘은 SQL 내용 중 강사님께서 중요하고 많이 사용된다고 짚어주셨던 내용들을 정리해보았다.구조화된 질의 언어(Structured Query Language, SQL)는 DBMS에서 데이터를 정의하고, 관리하며, 활용하기 위해 사용하는 특수 목적의 프로그래밍 언어소프트
128.260105 [ Day 5 ] - Python (2)
오늘은 교육 2주 차의 첫날이다. 저번 교육 과정에서는 파이썬을 배우는데 2주 정도 걸렸던 것으로 기억하는데, 이번 과정에서는 오늘 파이썬 파트가 마무리되고 내일부터 데이터 분석에 대해서 배우기 시작한다.대괄호 안에 원소를 나열한 복합 자료형다양한 자료형의 원소를 가질
129.260106 [ Day 6 ] - Python (3), NumPy (1), Pandas (1)
오늘은 어제까지 배웠던 내용 중 중요한 내용을 다시 정리한 뒤, 객체 복사에 대한 개념을 배웠다. 그 뒤 NumPy와 Pandas에 대해 공부했다.소수점이 없는 수소수점이 있는 수여러 문자, 숫자, 기호 등의 시퀀스를 따옴표로 감싼 것소수점이 있는 문자열을 정수로 변환
130.260107 [ Day 7 ] - Data (1)
오늘은 본격적인 데이터 분석에 앞서 데이터 파일의 입출력에 대한 내용과 공공데이터포털 API를 사용해서 데이터를 수집하는 방법을 실습해보았다.Python에서 외부 파일을 입출력할 때 입출력 함수의 괄호 안에 ‘경로/파일명.확장자’ 형태의 문자열을 인수로 지정Window
131.260108 [ Day 8 ] - Data (2)
오늘은 데이터 전처리에 대해서 배우고 현업에서는 어떤 방식으로 전처리를 진행하고 편하게 할 수 있는 팁들을 배워보았다.데이터 품질이 머신러닝 알고리즘 간의 차이보다 분석 결과에 훨씬 큰 영향을 미침데이터를 수집하고 정리하는 업무가 전체 과정의 약 80% 차지결측값과 이
132.260109 [ Day 9 ] - Data (3)
오늘은 2주 차 마지막 날이다. 오늘까지 데이터 전처리를 마무리하고 다음 주 월요일에 시각화에 대해 배우면 이번 파트도 끝이 나는 것 같다.년도, 월, 일 원소 사이에 하이픈을 추가해서 날짜시간형 타입의 문자열로 병합날짜시간 기본형 문자열 ’yyyy-mm-dd’날짜시간
133.260112 [ Day 10 ] - Data (4)
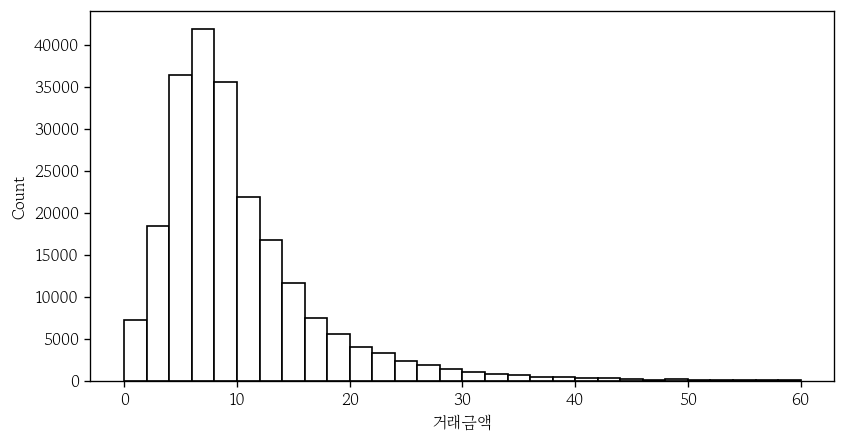
오늘은 파이썬 및 데이터 파트의 마지막 내용인 데이터 시각화에 대해서 배웠다. 지금까지 그래프를 그려는 봤지만 시각화에 대해서 본질적으로 배워본 것은 처음이라 많은 것을 배운 하루였다.모델 학습에 앞서 분석 대상 데이터셋의 구조와 특성을 이해하기 위해 수행다양한 기술통
134.260113 [ Day 11 ] - Data (5)
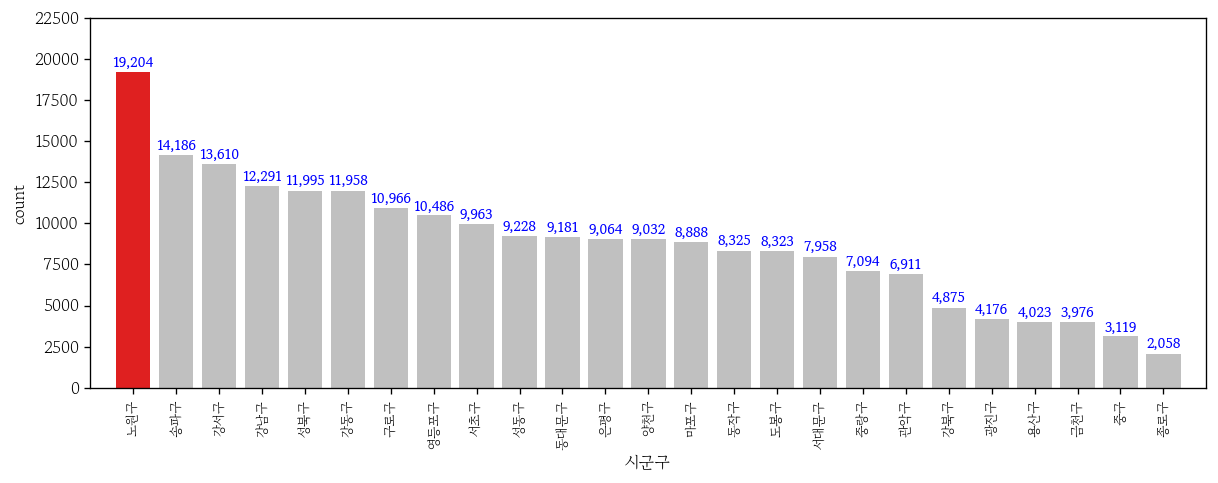
오늘은 수업은 따로 없고 Zoom을 통해서 취업 특강을 들었다. 그래서 마저 정리하지 못했던 그래프 시각화에 대해서 추가로 정리해보았다.특정 부분만 포인트 추가사용자 팔레트를 추가하려면 hue 매개변수에 x 축 변수명을 지정해야함order 매개변수로 x축 눈금명 순서를
135.260114 [ Day 12 ] - AI (1)
오늘부터 새로운 강사님과 AI에 대한 파트가 시작되었다. 처음으로는 AI에 필요한 기본적인 통계학 내용부터 기본적인 머신러닝 내용까지 배웠다.데이터를 수집, 정리, 분석, 해석하여 불확실한 현상 속에서 객관적인 사실을 이해하고 합리적인 의사결정을 내릴 수 있도록 돕는
136.260115 [ Day 13 ] - AI (2)
오늘은 머신러닝과 딥러닝에 대해 공부했다. 지난 교육 과정에서 처음 들었을 때는 모든 게 생소한 내용이라 너무 어려웠는데, 오늘은 그래도 한 번씩은 들어본 내용들이라 이해하기 수월했던 것 같다.손실 함수에 가중치의 합을 더하는 것Norm : 가중치 측정 방법L1 : L
137.260116 [ Day 14 ] - AI (3)
오늘은 지금까지 배운 머신러닝과 딥러닝에 대해 간단한 퀴즈 느낌의 테스트를 본 뒤, 생성형 AI에 대해 공부했다. 확실히 문제를 풀어보니까 개념들이 더 잘 기억나는 것 같다.기존 데이터에서 패턴을 학습하여 새로운 콘텐츠(텍스트, 이미지, 오디오 등)를 스스로 생성하는
138.260119 [ Day 15 ] - AI (4)
오늘은 LLM과 Token, Embedding, Transformer 등 AI에서 중요한 개념들에 대해 많이 배웠다. Large Language Model(대규모 언어 모델)방대한 텍스트 데이터를 학습해 인간의 언어를 이해하고 생성하는 인공지능 모델Transformer
139.260120 [ Day 16 ] - AI (5)
오늘은 어제에 이어 LLM에 대한 내용을 배운 뒤, AI를 더 잘 활용할 수 있도록 프롬프트 엔지니어링을 배웠다.Encoder : 전역적 문맥 분석 및 특징 추출Attention Score : 문장 내 토큰 간의 연관성을 수치화한 표현(가중치)Self-Attention
140.260121 [ Day 17 ] - AI (6)
오늘은 여러 AI 에이전트에 대해서 알아보고 각 에이전트별 특징과 토큰 가격 등을 알아보는 시간을 가졌다. 또한, 제미나이 Gems에 대해서도 배웠는데 상당히 유용해 보였다.GPT, 제미나이, 클로드 등 유명 AI 에이전트들의 여러 특징을 알아봤다. 대부분 알고 있던
141.260122 [ Day 18 ] - AI (7)
오늘은 GPT API를 사용해서 챗봇 느낌의 미니 게임을 만드는 팀 실습을 진행했다. 강사님의 GPT API를 연결해서 용의자의 자백을 이끌어내는 미니 게임을 만들었다. 그라디오(Gradio)라는 라이브러리를 사용해서 인터페이스를 생성하니, 실제 웹 페이지에서 게임을
142.260126 [ Day 19 ] - AI (8)
오늘은 지난 미니 게임 만들기 마무리 후 MCP에 대해서 배웠다.서로 다른 시스템 간 데이터 교환을 위한 공통 규칙데이터 형식, 해석 방식, 통신 타이밍 등을 정의규격만 맞으면 제조사 상관없이 소통하는 상호 운용성학습 데이터 기반 답변으로 실시간 정보 접근 불가부족한
143.260127 [ Day 20 ] - AI (9)
오늘은 MCP 팀 실습을 진행해보았다. 이번 팀 실습은 GitHub MCP를 사용해서 구글 스프레드시트에 기준에 맞는 레포지토리를 정리하는 실습을 했다.레포지토리를 가져온 뒤 GPT API를 연결해서 프롬프트를 작성해 레포지토리에 대한 설명 및 특징 등 추가적인 정보를
144.260128 [ Day 21 ] - AI (10)
오늘은 내일 시험을 대비해서 이번 AI 파트를 전체적으로 복습한 뒤 발표 준비를 위한 데이터 찾기 및 PPT 제작을 하는 시간을 가졌다.데이터 수집 및 분석불확실성의 계량화 및 예측합리적인 의사결정Induction(귀납추론)구체적인 사례 → 일반적인 원리 / 결론결론읜
145.260129 [ Day 22 ] - AI (11)
오늘은 이번 AI 파트의 마지막 날이었다. 그동안 준비했던 프로젝트 계획에 대한 발표와 머신러닝부터 LLM, MCP 까지의 테스트를 끝으로 마무리 하였다.AI 파트는 재밌기도 하고 관심도 많이 있어서 테스트에 자신이 있었다. 하지만 예상보다 문제가 어렵게 나오기도 했고
146.260202 [ Day 23 ] - ML, DL (1)
오늘부터 새로운 파트인 머신러닝과 딥러닝 심화 파트에 들어갔다. 본격적으로 머신러닝과 딥러닝에 대해 공부하기 전에 필요한 통계학에 대해 더 깊게 배운 뒤에 머신러닝과 딥러닝을 배울 것 같다. 이전 파트에서도 가볍게 통계학을 다루긴 했는데 이번에는 조금 더 복잡하고 어려
147.260203 [ Day 24 ] - ML, DL (2)
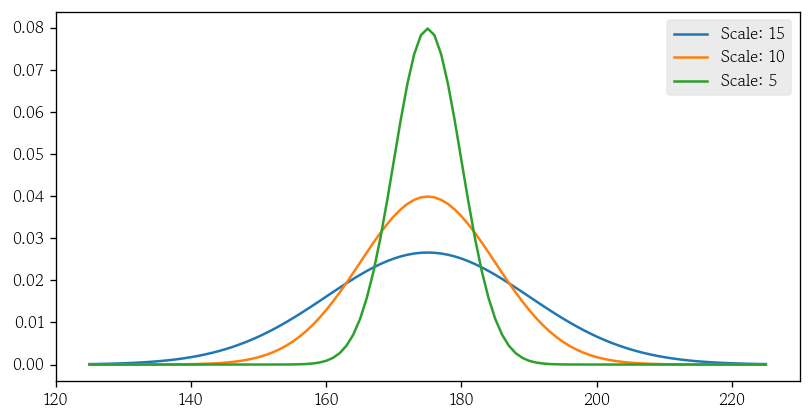
오늘도 어제에 이어 통계학 공부를 이어갔다. ADsP 공부를 하면서 지겹도록 복습한 귀무가설에 대한 내용들과 아직도 적응이 안되는 여러 분포와 검정들에 대한 내용들을 배웠다.정규분포를 따르는 무작위 값 생성평균 175, 표준편차 5인 정규분포를 따르는 가상의 키 데이터
148.260204 [ Day 25 ] - Algorithm 특강
오늘은 특강으로 알고리즘에 대한 내용들과 코딩 테스트에 관한 내용을 배워보았다.알고리즘의 효율성 평가단순 실행 시간으로 평가하기엔, 환경(컴퓨터 성능)에 의존적시간 복잡도(Time Complexity)입력 크기가 커질수록 알고리즘의 연산량 증가를 대략적인 수식으로 표현
149.260205 [ Day 26 ] - ML, DL (3)
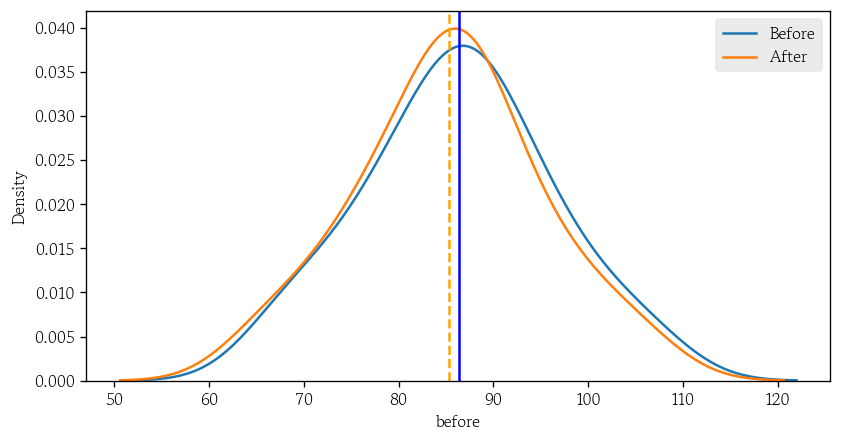
배우면 배울수록 통계학은 정말 어렵지만 그럼에도 재미가 느껴지는 묘한 매력이 있는 것 같다. 단일표본 t-검정검정통계량모분산을 알면(표준정규분포) $z = \\frac{\\bar{X} - \\mu_0}{\\frac{\\sigma}{\\sqrt{n}}}$모분산을 모르면(
150.260206 [ Day 27 ] - ML, DL (4)
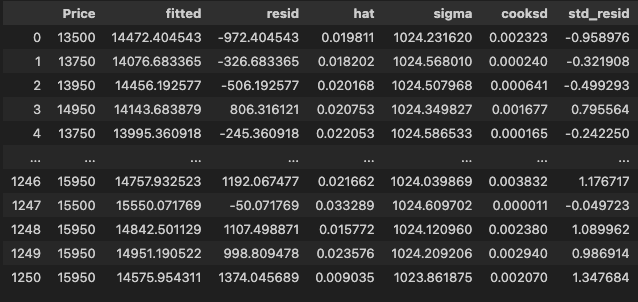
오늘로 통계학 내용은 마무리가 되었다. 정말 어렵고 복잡한 내용이 많았지만 묘하게 재미가 있어서 이후에 강사님께서 추천해주신 책을 구매해서 통계학도 공부해보고 싶다.스튜던트 잔차 : y중심레버리지 : x중심쿡의 거리 : 쿡의 거리가 4/n(행 개수)보다 큰 관측값을 영
151.260209 [ Day 28 ] - ML, DL (5)
오늘부터 본격적으로 머신러닝 파트에 들어갔다. 전반적으로 통계학보다는 할만했지만 내용이 너무 많고 복잡한 내용이 조금씩 있어서 따라가기만 해도 힘든 수업이었던 것 같다.AI인간의 학습, 추론 등 다양한 능력을 인공적으로 구현하려는 분야인간에게 어려운 과업을 컴퓨터는 쉽
152.260210 [ Day 29 ] - ML, DL (6)
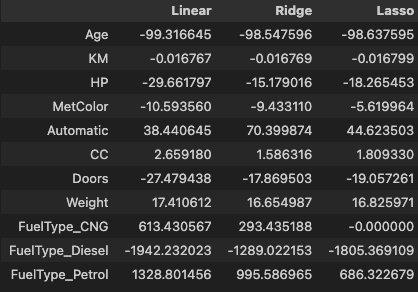
오늘도 머신러닝에 대해 배웠다. 확실히 머신러닝 파트에 들어오고부터는 이론도 많지만 코드로 접근하는 시간이 많아져서 한결 편한 것 같다. 그러면서 동시에 생각보다 코드는 어려운 부분이 없고 많은 부분이 정해져 있어서 그 이전 과정인 데이터 전처리와 핸들링, 통계 분석
153.260211 [ Day 30 ] - ML, DL (7)
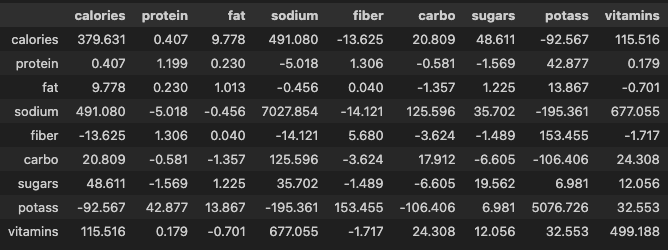
오늘은 주성분 분석과 군집화에 대한 내용을 배웠다. 주성분 분석이 엄청 복잡하지만 이후 작업을 할 때 매우 유용하게 사용할 수 있는 내용이라 어렵지만 최대한 이해하려고 들어서 대략적인 이미지는 그릴 수 있었다.주성분 분석 : 고차원의 데이터를 저차원으로 축소하는 기법열
154.260212 [ Day 31 ] - ML, DL (8)

오늘은 최근들어 가장 컨디션이 안 좋은 날이었다. 그래도 최대한 내용들의 이미지는 가져가려고 집중을 했기 때문에 주말부터 시작되는 연휴 간 복습을 꾸준히 해야겠다.타겟 변수 quality = 서열형서열형 → 명목형 변환불필요한 컬럼 제거목표변수 도수 확인연속형 변수 간
155.260213 [ Day 32 ] - ML, DL (9)
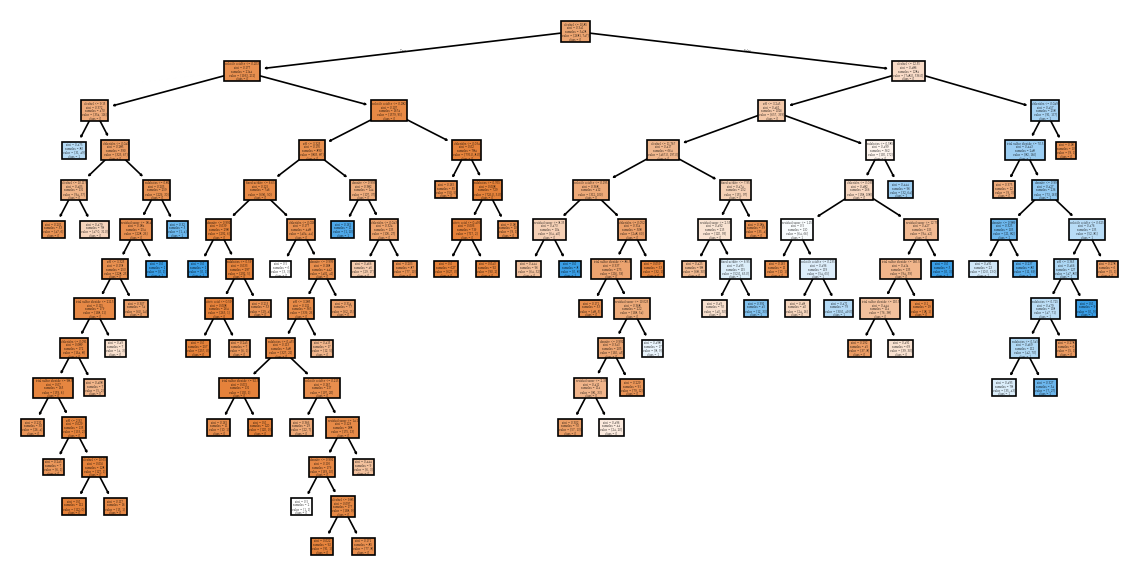
오늘은 연휴 전 마지막 수업이었다. 의사결정나무에 이어 앙상블, 랜덤포레스트에 대한 내용을 배웠다.분류와 회귀 문제에 널리 쓰이는 대표적인 알고리즘각 노드에서 타겟의 불순도 계산지니 계수, 엔트로피, 카이제곱 통계량 등을 사용노드에서 타겟의 클래스가 완전하게 섞여 있을
156.데이터 통계 분석 정리
오늘은 그동안 배웠던 내용들을 정리하면서 데이터 통계 분석을 할 때 나만의 워크플로우를 만들어봤다.1단계 : 척도 파악 → 2단계 : 탐색적 데이터 분석(EDA) → 3단계 : 분석 방법 선택 → 4단계 : 귀무가설 및 사후 검정os : 데이터 파일 경로 제어hds :
157.데이터 전처리 정리 (1)
오늘은 그동안 사용했던 코드와 캐글, 깃허브에서 다른 사람들의 코드를 찾아보면서 데이터 전처리 과정을 템플릿으로 정리해 보았다. 전처리 과정이 워낙 복잡하고 정해진 순서가 없다 보니, 전체적인 구조 잡기와 여러 데이터를 찾아보느라 오늘 다 끝내지는 못해서 내일 이어서
158.데이터 전처리 정리 (2)
오늘은 어제에 이어서 데이터 전처리 템플릿을 마무리했다. 작성하면서 앞부분도 약간의 수정을 진행했다.단일 열 선택 → Series 반환여러 열 선택 → DataFrame 반환(팬시 인덱싱)loc 사용(끝 포함)str 사용한 열 이름 패턴 매칭수치형 비교단일 조건범위 조
159.260224 [ Day 34 ] - 제조 도메인 (1)
오늘부터 제조 도메인 파트가 시작되었다. 오전에는 간단하게 OT를 하면서 보냈고, 오후부터 본격적으로 수업을 시작했다.제조 / 생산 시스템의 트렌드최신 정보기술(IT Infomation Technology)의 도입 및 활용정보(시스템)의 통합 및 공유 : ERP, ME
160.260225 [ Day 35 ] - 제조 도메인 (2)
오늘도 제조 도메인 파트를 이어서 공부했다. 처음에 강의 자료를 받았을 때 200페이지 가량의 PPT가 4개 있어서 일주일만에 가능할까 싶었는데 대부분 내용들은 넘어가고 현업에 대한 내용들 위주로 수업을 진행해주셔서 외우는 내용보다는 이해가 필요한 내용들이 더 많았다.
161.260226 [ Day 36 ] - 제조 도메인 (3)
오늘은 제조 도메인의 MPS와 단기 생산 계획 및 우선순위에 대해서 배웠다.MPS : 제품별 월 생산계획(보통 3개월 기준)계획 수립 대상 파악영업 → 생산관리 요청(정보 시스템 사용)반품 : 수리 / 재작업품공정 불량 : 수리 / 재작업품시제품 테스트(R&D)A/S,
162.260227 [ Day 37 ] - 제조 도메인 (4)
오늘은 제조업에서의 정보 시스템과 실적에 대한 내용들을 배웠다.ERP(Enterprise Resource Planning) : 전사적 자원 관리MES(Manufacturing Execution System) : 생산 관리 시스템유통 POS(Point of Sales)
163.260303 [ Day 38 ] - 제조 도메인 (5)
오늘은 성과지표와 구매에 대해서 공부했다.수요예측 부정확품질 문제물류 문제일정 변경협력사의 부품 공급 지연안전재고 보유생산능력의 여유율 고려우선순위 조정아웃소싱 처리생산계획 확정구간 정책 활용확정구간 : 생산 계획의 안정성을 확보하기 위해 설정하는 수정 불가 기간을 의
164.260304 [ Day 39 ] - 제조 도메인 (6)
오늘은 원가관리에 대해서 배웠다.기업회계기준재무상태표(Balance Sheet) : 과거 대차대조표자산 = 자본 + 부채손익계산서(Income Statement, Profit and Loss Statement, P/L)총 매출액총 매출원가매출 총이익관리 판매비영업 이익
165.260305 [ Day 40 ] - 제조 도메인 (7)
오늘은 제조업 파트의 마지막 날이다. 자재 재고에 대해 배운 뒤 그동안 배운 내용들에 대해 시험을 보고 마무리했다.WMS(Warehouse Management System) : 창고 관리 시스템WMS 기능입고저장 / 보관고정형랜덤형출고 / 출하재고 관리로케이션 관리(L
166.260306 [ Day 41 ] - ML, DL - Part 2 (1)

오늘부터 머신러닝, 딥러닝 파트가 다시 시작되었다. XAI라는 설명 가능한 인공지능에 대해 배웠는데, 이전에 프로젝트를 준비하면서 관심을 가졌던 내용이라 상당히 흥미롭게 수업을 들었다.범주형 데이터 조회crosstab 으로 함께 조회연속형 입력변수 간 산점도 행렬 시각
167.통계 이론 정리 (1)
오늘은 SQLD 시험을 보고온 뒤 통계학 이론 내용들을 정리해보았다.통계 개요기술 통계이상치 탐지 맟 처리확률 기초확률 분포표본 이론가설 검정모집단 → 표본 추출 → 표본 → 통계적 추론 → 모집단에 대한 결론모수는 고정된 값이지만 알 수 없고, 통계량은 표본마다 달라
168.260309 [ Day 42 ] - ML, DL - Part 2 (2)
오늘은 이상탐지에 대해 배웠다. 이상탐지 파트도 내용이 엄청 많고 하나하나 다 어려운 개념들이라 정말 힘들었다. 그래도 기초 통계 이론을 정리해둬서 도움이 되는 부분이 많아 빨리 머신러닝 통계 이론도 정리해야 될 것 같다.센서 오작동, 기록/입력 오류로 인해 발생한 이
169.260310 [ Day 43 ] - ML, DL - Part 2 (3)
오늘로 머신러닝 파트가 끝이 났다. 이상탐지 부분이 어려운 개념들이 많아서 진이 많이 빠졌지만 어려운만큼 이후에 도움이 될 거라고 생각해서 열심히 들었던 것 같다.SPE(Squared Prediction Error)는 PCA 모델로 복원한 값과 실제값의 차이를 사용실무
170.260311 [ Day 44 ] - Git, GitHub 특강
오늘은 Git과 GitHub에 대한 특강을 들었다. 실무에서 사용하는 협업 기능이나 AI를 활용한 PR 자동화 등의 내용을 기대했지만 다소 기초적인 내용들이라 약간 아쉬웠다.Git 파트에서는 기본적인 add/commit/push에 대한 내용들부터 init으로 초기화한
171.260312 [ Day 45 ] - ML, DL - Part 2 (4)
오늘부터 딥러닝 파트가 시작되었다. 딥러닝이 무엇인지에 대해 간단하게 배우고 딥러닝 데이터 처리를 위한 PyTorch를 배웠다.데이터에 내재된 패턴을 학습사람이 직접 특성을 설계해야 한다는 한계가 존재문제 해결에 어떤 특성이 필요한지 스스로 판단 못함특성 설계에 크게
172.260313 [ Day 46 ] - ML, DL - Part 2 (5)

오늘은 MNIST 이미지 처리와 퍼셉트론에 대해 배웠다. 복잡한 코드를 많이 배우니 따라가기도 벅찬 하루였다. 그래도 이전에 한 번 배웠던 내용이라 괜찮을 줄 알았는데 이전에 맛보기로 배웠던 내용들을 본격적으로 배우려니 생각보다 어려웠던 것 같다.이미지 분류 문제를 다
173.260316 [ Day 47 ] - ML, DL - Part 2 (6)
오늘은 다층 퍼셉트론과 클래스를 사용한 딥러닝 모델 생성에 대해서 공부했다.다층 퍼셉트론은 퍼셉트론 사이에 은닉층을 추가한 구조은닉층 : 입력과 출력 사이에서 중간 표현(특징)을 학습하는 역할여러 층을 거치며 신경망은 입력 데이터(특성)를 점점 의미 있는 형태로 변환각
174.260317 [ Day 48 ] - ML, DL - Part 2 (7)

오늘은 새로운 맥북으로 처음 듣는 수업이었다. 그동안 커널이 터져버리던 무거운 작업들이 바로 돌아가는 것도 좋았지만 다른 사람들은 10분 걸리던 작업이 1분도 안 돼서 완료되는 성능이 당황스러울 정도로 좋았다.행렬을 벡터로 평탄화하는 과정에서 이미지의 공간적 구조가 완
175.260318 [ Day 49 ] - ML, DL - Part 2 (8)
오늘은 컬러 이미지에 대한 내용들과 CIFAR-10 이미지 데이터를 사용한 실습 위주로 진행하였다.CIFAR-10은 컬러 이미지이고 배경이 복잡하며 클래스 간 유사성이 높기 때문MLP는 픽셀 간의 공간적 정보 및 국소적 패턴을 구조적으로 표현하지 못함CIFAR-10 이
176.260319 [ Day 50 ] - ML, DL - Part 2 (9)
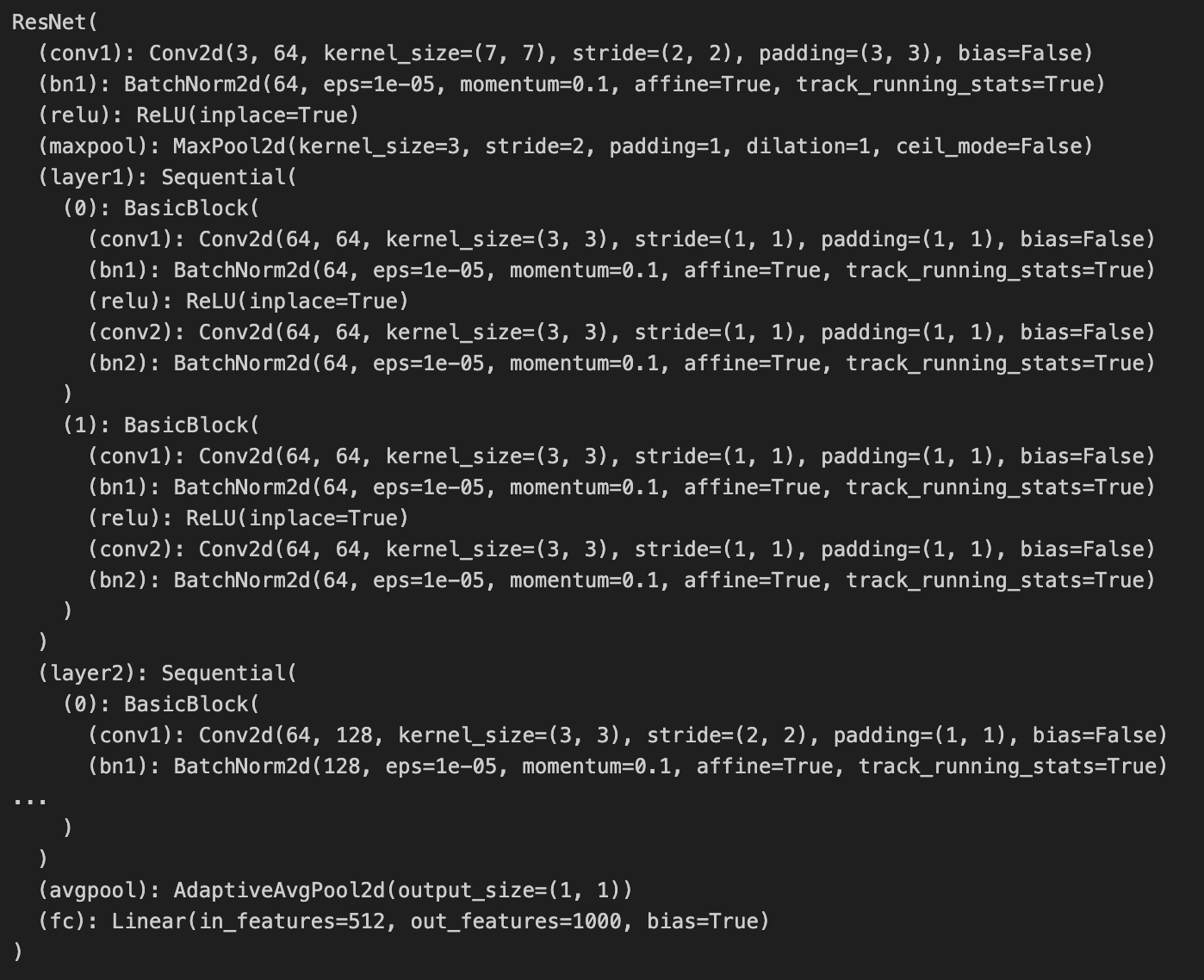
오늘은 ResNet 모델에 대해서 배웠다. 분명 전에 다뤄본 모델이었는데 이름만 익숙했지 사용법은 전혀 달라서 놀랐다.대규모 데이터셋으로 미리 학습된 모델을 가져와 특징을 재사용하고, 새로운 데이터에 맞게 일부만 조정하는 방법사전 학습 된 모델 준비준비한 데이터셋에 적
177.260323 [ Day 51 ] - ML, DL - Part 2 (10)
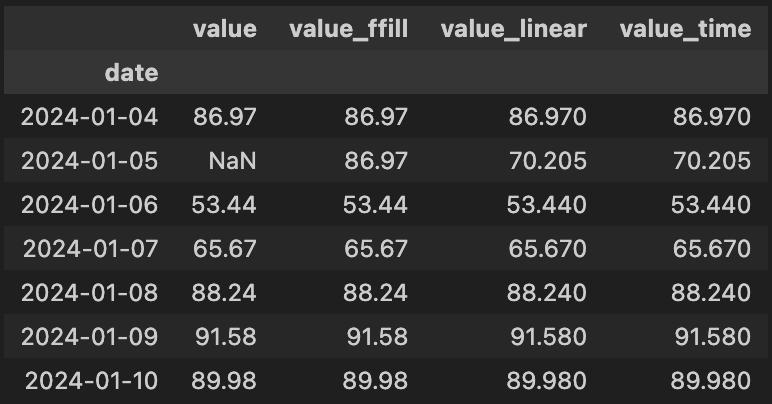
오늘부터 시계열 데이터 파트가 시작되었다. 오늘은 시계열 예측에 앞서 시계열 데이터에 대해서 배우고 데이터 자체를 다뤄보는 시간을 가졌다.시계열 데이터 : 시간의 흐름에 따라 순차적으로 관측된 데이터관측값이 독립적이지 않고, 이전 시점 값과 밀접한 관계를 가짐시계열 데
178.260324 [ Day 52 ] - ML, DL - Part 2 (11)
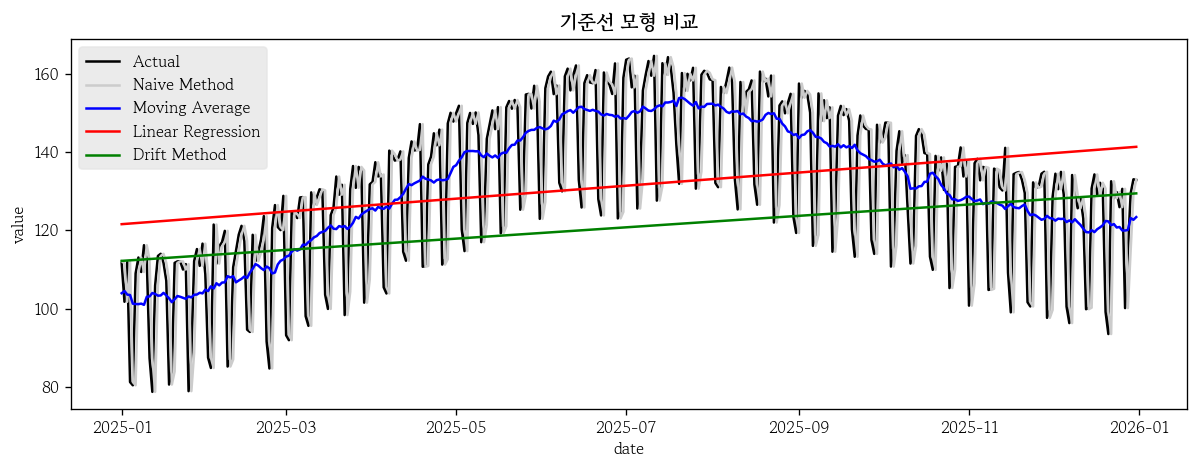
오늘은 시계열 데이터 2일차로 기준선 모형과 ARIMA 모형에 대해서 배웠다. 이론적으로 상당히 어려운 하루였다.기준선 모형은 학습을 거의 하지 않는 규칙 기반 예측시계열 데이터의 구조적 특성이 얼마나 예측 가능한지를 판단하기 위한 최소 기준아무리 복잡한 딥러닝 모델을
179.260325 [ Day 53 ] - ML, DL - Part 2 (12)
오늘은 시계열 데이터의 마지막 Prophet과 머신러닝, 딥러닝을 사용한 시계열 데이터 예측을 배웠다.전통적 통계 모형인 ARIMA는 자기상관 구조를 정교하게 적합할 수 있다는 장점이 있음 → 정합성 판단, 차수 선택, 계절성 처리 등의 사전 판단이 필요하다는 한계가
180.260327 [ Day 54 ] - 제조 AI (1)
오늘부터 제조 AI 파트가 시작되었다. 이번 파트는 제조업의 실제 데이터를 사용해서 실습해보는 것이 주된 내용이라 보안상의 이유로 정리 내용을 거의 올리지는 못할 것 같다.오늘은 실제 제조 도메인의 회사에서 진행했던 프로젝트의 데이터를 보면서 어떤 도메인 전문성이 포함
181.[ CLAUDE ] - HarnessDA (3)
오늘과 내일은 제조업 데이터를 사용한 팀 프로젝트가 진행된다. 실제 현업의 데이터라 작업 내용을 올리기가 허용되는 내용인지 아직 확실하지 않아서 오늘 진행한 프로젝트 내용을 작성하기로 했다.일단 오늘 큰 좌절을 느끼고 다시 한번 프로젝트를 돌아보는 시간을 가졌다. 그
182.260331 [ Day 56 ] - 제조 AI (3)
오늘은 하루종일 팀 프로젝트를 하며 시간을 보냈다. 이번 프로젝트는 제조 데이터를 사용한 연구 분석 프로젝트로, 실제 제조업 데이터를 강사님께서 가공하여 공유해주셨다. 해당 데이터 중 원하는 데이터를 골라 문제를 정의하고 가설을 세운 뒤 EDA, 데이터 전처리, 피처