Within-Subject 실험 디자인은 비교적 적은 사람 수로 Independent variable이 미치는 통계적 유의성을 확인할 수 있게 해준다. SPSS 프로그램으로 repeated measure (within-subject) ANOVA를 돌려보는 과정을 정리해보자.
IBM SPSS Statistics 25버전
어떤 테스트?
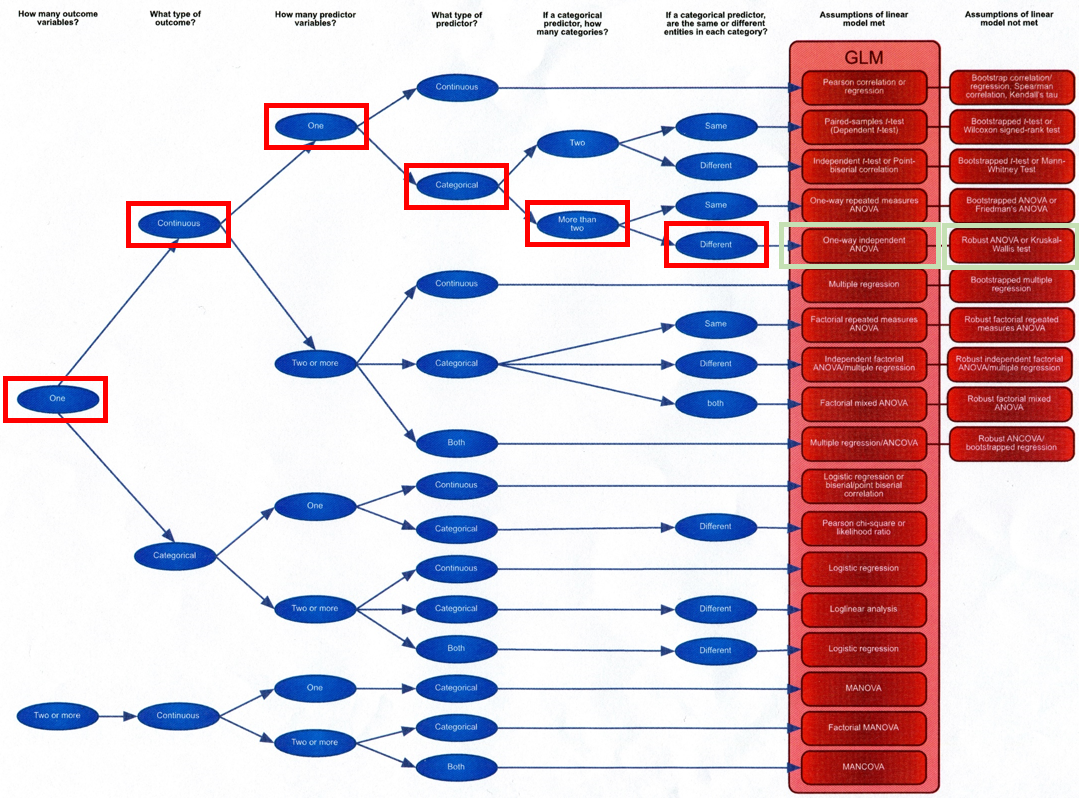
SPSS로 들어가기 전에, 누군가 잘 정리해놓은 수형도를 보자. 가장 최근 내가 분석한 데이터는
- Outcome variable 개수 = 1개 (Accuracy)
- Outcome variable type = Continuous
- Predictor variable 개수 = 1개(착용한 디바이스 종류)
- Predictor variable type = Categorical
- How many categories? = More than two (3개, 디바이스 종류)
- Same or different entities in each category? = Same
(이 조건이 Same이면 within-subject, Different면 between-subject 디자인이다)
마지막으로 정규성 검정을 통과한다면 One-way Repeated measures ANOVA를 하면 되고, 통과하지 못하면 Bootstrapped ANOVA 혹은 Friedman's ANOVA를 하면 된다.
Toetskeuzeschema Field
지금부터 SPSS로 할 것은 다음과 같다:
- 데이터의 정규성 검정
- 각 테스트 (One-way RM ANOVA / Friedman's ANOVA)
- 구형성 체크
- 방법 간 차이의 significant effect (p-value) 체크
- post-hoc 분석
1. 정규성(Normality) 검정
프로그램 사용
- 분석 - 기술통계량 - 데이터 탐색 클릭
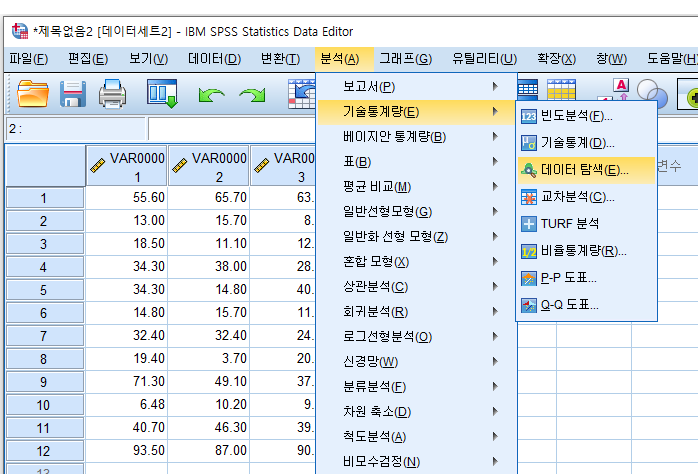
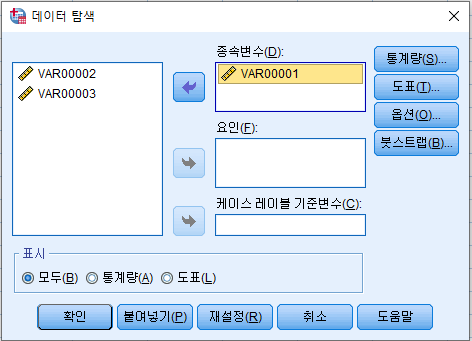
- 검사하려는 변수를 종속변수에 추가한 후 '통계량' 클릭
- 아래 옵션으로 설정 후 '계속' 클릭
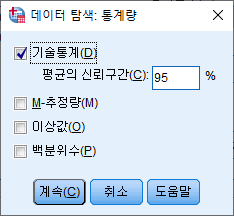
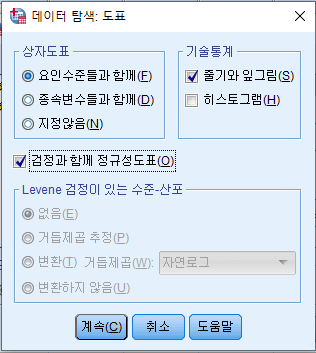
- 도표 클릭
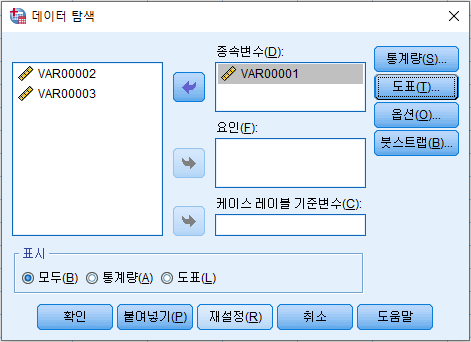
- 아래 옵션으로 설정 후 '계속' 클릭
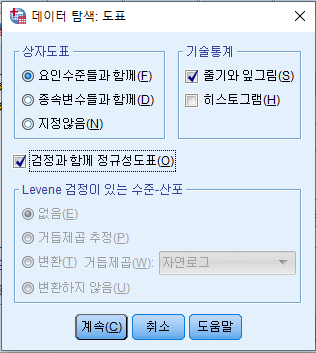
- '확인' 클릭
결과 분석
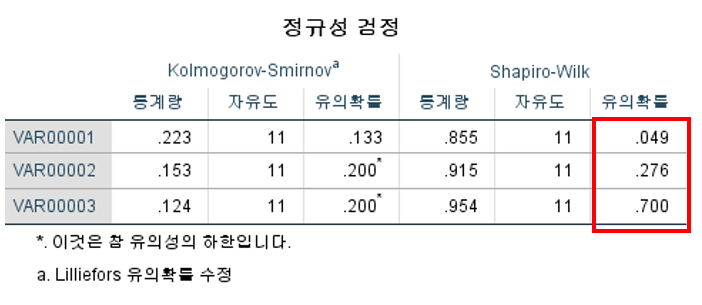
- 정규성 검정 표 확인
- Shapiro-Wilk Test의 유의확률(p-value)이 0.05보다 크면 정규성 성립
- VAR 1는 정규성이 성립하지 않고 VAR 2, 3는 성립함을 알 수 있음
2-1. One-way Repeated Measure ANOVA
이 글에서 가장 중요한 부분이고 앞으로 가장 많이 쓰게될 테스트다.
프로그램 사용
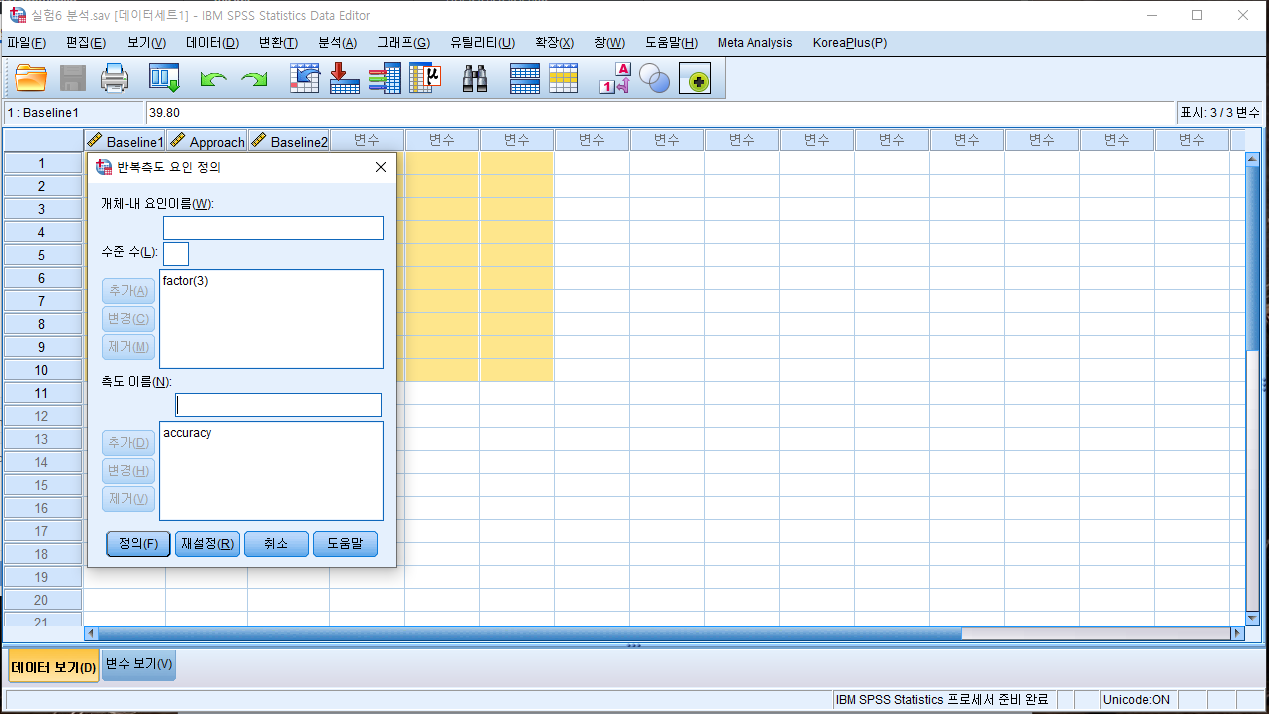
- 분석 - 일반선형모델 - 반복측도 클릭
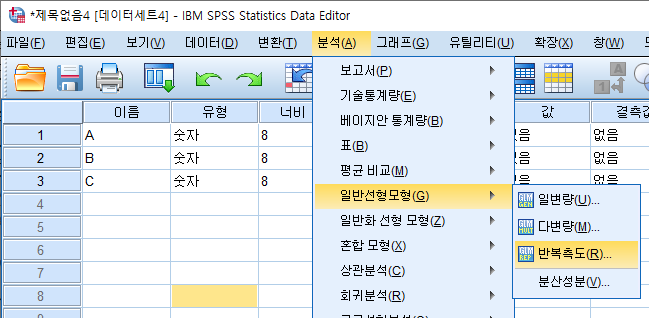
- 요인 이름, 측도 이름을 임의로 정함. 수준 수에는 조건 개수 입력. 추가한 뒤 '정의' 클릭
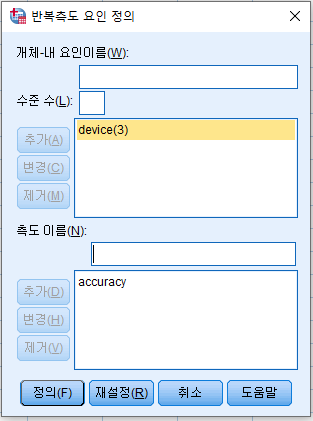
- 왼쪽의 Column들을 개체-내 변수로 이동
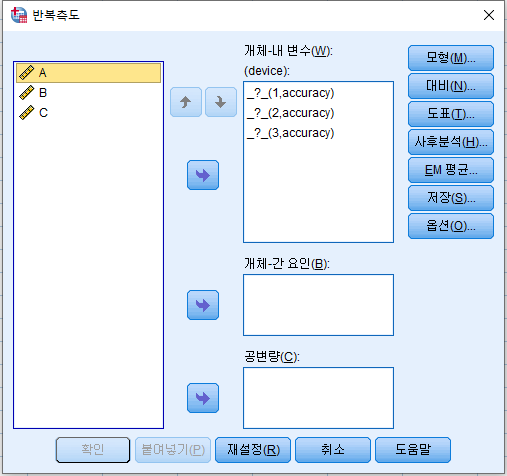
- 'EM 평균' 클릭. 독립 변수를 오른쪽으로 옮기고 '주효과 비교' 체크, 아래는 Bonferroni 선택
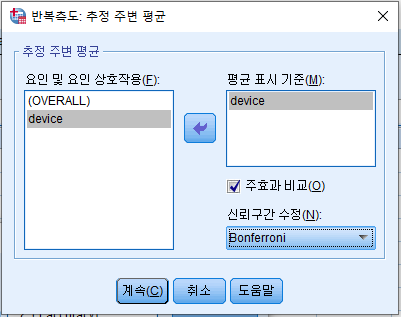
- '옵션' 클릭. '기술통계량' 체크
- '확인' 클릭
결과 분석
- 구형성 확인
- Mauchly's Test에서 유의 확률(p-value)이 0.05보다 크면 구형성 만족
- 본 데이터는 구형성이 만족됨
- 구형성이 만족되지 않으면 significant effect를 볼 때 Greenhouse-Gesser (p < 0.05 &&
Greenhouse-Geisser Epsilon < 0.75) 혹은 Huynh-Feldt (p < 0.05 && Greenhouse-Geisser Epsilon > 0.75) 에 따른 결과를 사용해야 한다. - Reapeated Measure의 level이 여기서는 3개지만, 2개라면 자동으로 구형성이 만족되어 체크할 필요가 없다.
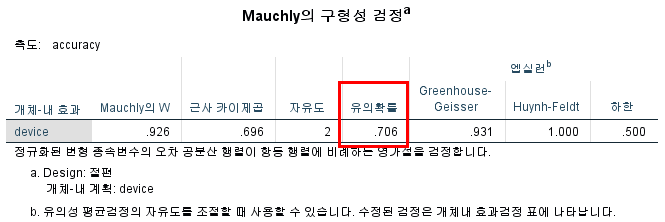
- 방법 간 차이의 significant effect 체크
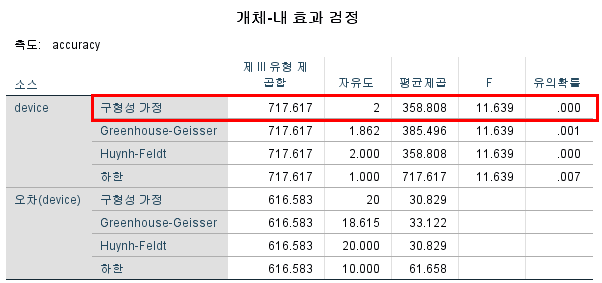
- 구형성 가정이 만족됐기 때문에 가장 위의 유의확률(p-value)를 보면 된다. p < 0.05로 방법 간 차이의 significant effect가 확인됨
- "There was a significant effect of type of device on accuracy (F(2,20)=11.639, p=.000)"
- 사후 분석(post-hoc analysis w/ Bonferroni Correction)
- 아래 표를 확인해보면 (device 1 - device2), (device 3 - device 2) 사이에는 유의미한 차이가 있고, (device 1 - device 3) 사이에는 유의미한 차이가 없음을 확인할 수 있다.
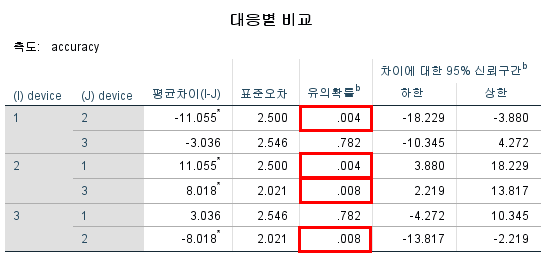
- 아래 표를 확인해보면 (device 1 - device2), (device 3 - device 2) 사이에는 유의미한 차이가 있고, (device 1 - device 3) 사이에는 유의미한 차이가 없음을 확인할 수 있다.
2-2. Friedman's test
Friedman's test의 사후분석은 비모수검정(non-parametric test)의 post-hoc 분석에 쓰일 수 있는 Wilcoxon Signed-Rank Test를 따로 사용해야 하기 때문에 섹션을 나눈다.
프로그램 사용 (1)
- 분석 - 비모수 검정 - 레거시 대화상자 - K-대응표본 클릭
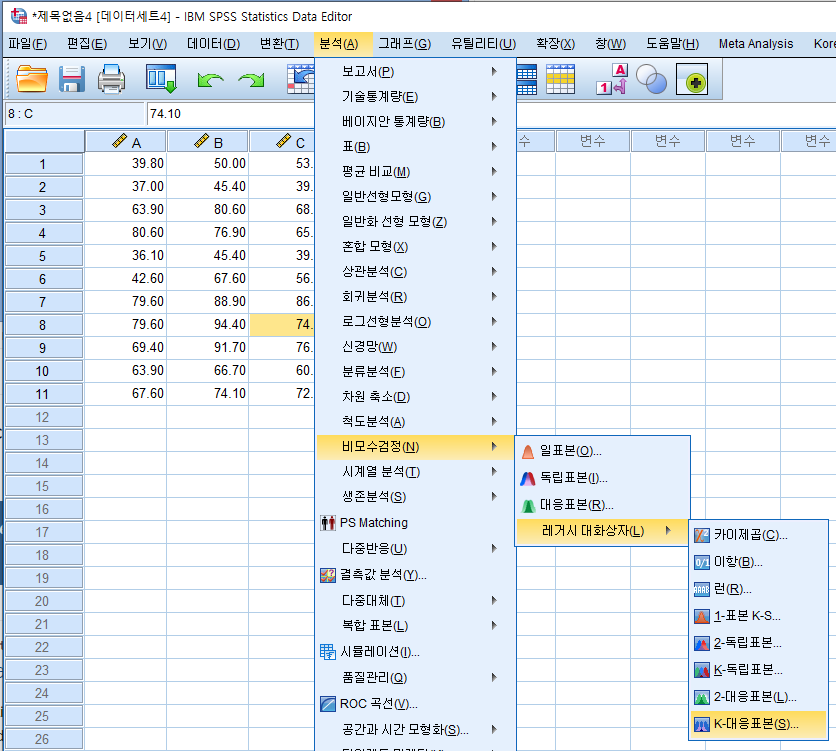
- 왼쪽의 Column들을 검정 변수로 이동. 아래 Friedman에 체크된 것 확인
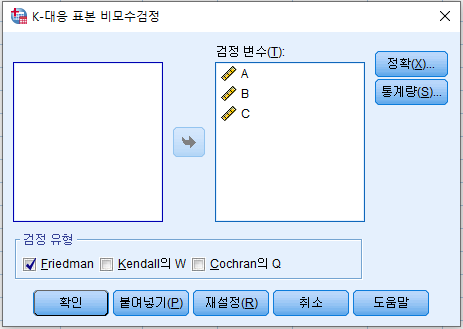
- '통계량' 클릭 - '사분위수' 체크 후 '계속' 클릭
- '확인' 클릭
결과 분석 (1)
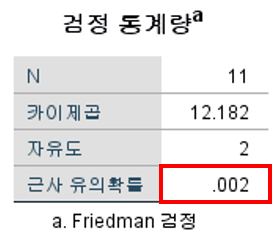
- 검정 통계량의 근사 유의확률이 0.05보다 작으므로 significant effect가 있다.
프로그램 사용 (2) - 사후 분석 (Wilcoxon signed-rank test)
- 분석 - 비모수 검정 - 레거시 대화상자 - 2-대응표본 클릭
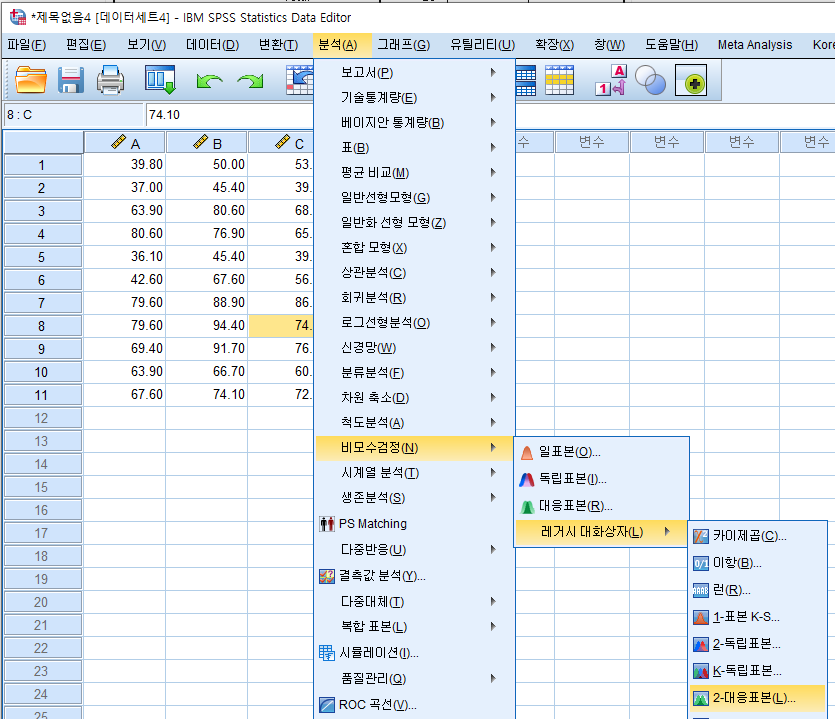
- 비교하고 싶은 변수의 pair를 모두 오른쪽으로 옮긴다
- '옵션' 클릭 - '기술통계', '사분위수' 체크 후 '계속' 클릭
- '확인' 클릭
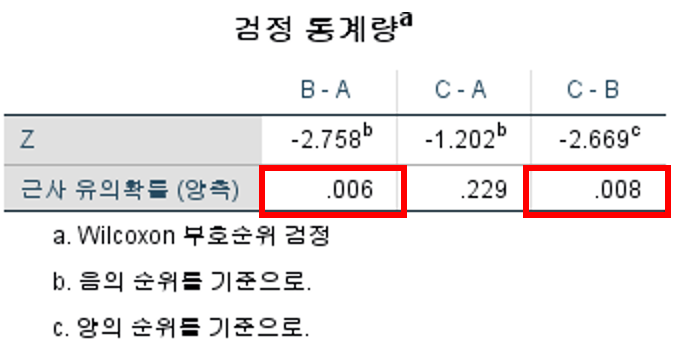
결과 분석 (2) - 사후 분석 (Wilcoxon signed-rank test)
- 검정 통계량의 유의 확률이 0.05보다 작다면 각 pair 사이에는 유의미한 차이가 있다.
변경 이력
- 2020년 2월 3일: 글 등록
- 2021년 12월 1일: "그래프 그리기" 섹션 삭제, Velog로 이전

Ph.D. Candidate in HCI Lab KAIST
안녕하세요. 통계분석 관련하여 문의드리고 싶은 내용이 있는데, 혹시 질문드려도 될까요?