json 형식으로 된 데이터 내 특정 부분을 발췌하여 table 형태로 저장할 필요가 있어 python을 활용하여 추출하는 방법을 정리하였다.
필요 라이브러리 부터 import를 하였다.
import pandas as pd
import json그리고 json 파일을 불러왔다
# file 경로 입력
file_path = './example.json'
# json file load
with open(file_path,encoding='UTF-8') as json_file:
data = json.load(json_file)예시로 쓰일 json파일은 아래 형태와 같다
{
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" },
{ "id": "1002", "type": "Chocolate" },
{ "id": "1003", "type": "Blueberry" },
{ "id": "1004", "type": "Devil's Food" }
]
,
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" },
{ "id": "5005", "type": "Sugar" },
{ "id": "5007", "type": "Powdered Sugar" },
{ "id": "5006", "type": "Chocolate with Sprinkles" },
{ "id": "5003", "type": "Chocolate" },
{ "id": "5004", "type": "Maple" }
]
}이 문서 내에서 "batters" 내 id와 type 항목을 모아서 담아가려 한다.
먼서 json 내 상위부분까지 설정한다
json_strc=data["batters"]이후 dataframe화 작업을 진행하였다.
빈 dataframe에서 concat 반복이 안되는 문제가 생겨
리스트에 수집항목을 이어붙인 후 이것을 빈 df에 concat하는 방식을 취했다
# 빈 리스트 생성
df_list = []
# 수집할 column 리스트 생성
json_range=json_read.columns.tolist()
# 수집항목 리스트에 이어붙인 후 다시 dataframe에 삽입
for i in range(len(json_range)):
jsn = pd.json_normalize(json_strc[json_range[i]])
df_list.append(jsn)
df_total = pd.concat(df_list, join='outer')여기서 json_normalize는 json 문서를 table형식으로 만들어 주는 flatten 작업이다.
https://pandas.pydata.org/docs/reference/api/pandas.json_normalize.html
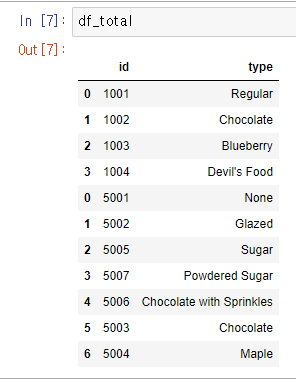
위 모든 작업을 수행한 후 결과는 아래와 같다.

학습기록