
엑셀파일 작업 중 몇백개의 괄호 안 텍스트를 뽑아내야 할 일이 생겼다.
이 것을 일일히 작업하기에는 불합리적이었고, 뭔가 자동화를 하고 싶은 마음이 들었다.
우선 필요 라이브러리부터 import
import pandas as pd
import numpy as np그 다음 작업할 파일을 불러오자
파일 업로드
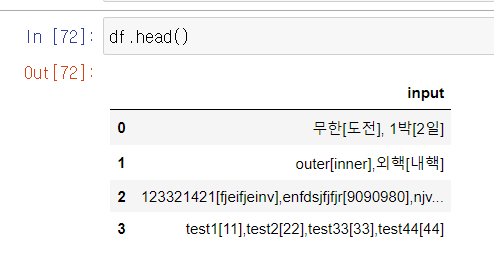
df = pd.read_excel('./input.xlsx')예제파일의 구조는 아래와 같다.
전처리
이제 전처리 과정을 진행하려고 한다.
column 이름을 바꿔주고, 쉼표로 구분된 요소들을 옆 열로 분배하는 과정을 진행하였다.
그 이전에 한 셀에 최대 몇개의 요소들이 들었는지 세어 반복문에 활용하였다.
# column 이름 전처리
df.columns = ['input']
#특정 요소 count(쉼표)
max_comma=int(df.input.str.count(',').max())+1
# column 컴마단위애들 쪼개기
for i in range(0,max_comma):
df[i] = df.input.str.split(',').str[i]
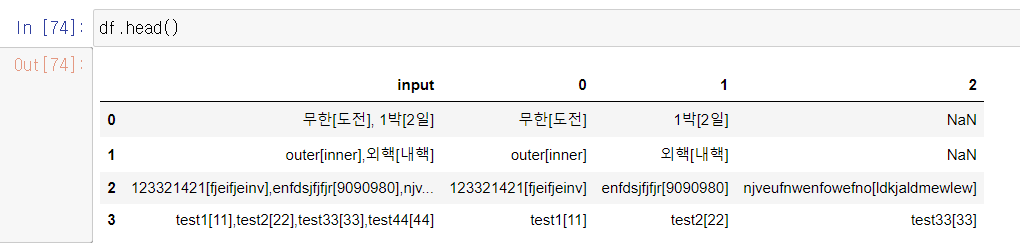
그리고 한번더 전처리 작업을 하여 NaN 제거를 하여 string 형식으로 바꿔주고, 뒤 중괄호를 지워준다
뒷부분의 ]을 찾기 위하여 replace에 정규표현식을 적용하였다.
#전처리_Nan String 변경 & 뒤 중괄호 제거
df = df.iloc[:,1:max_comma].replace(np.nan, '', regex=True).replace(']$','',regex=True)텍스트 추출
각자 셀의 중괄호 부분만 걸러내는 작업을 실행하였다.
split을 이용하여 "[" 기준 뒷부분만 남기는 작업을 반복하는 것이다.
# 분리 컬럼 내 중괄호 안 텍스트만 추출
for i in range(len(df)):
df[i] = df.iloc[:, i].str.split('[').str[1]텍스트 병합 및 저장
나온 결과물을 바탕으로 다시 하나의 셀로 만들어야 하므로 하나의 열로 만드는 작업을 진행하였다.
# 반복횟수 숫자 만들기
col=[]
for i in range(df.shape[1]):
col.append(i) # append로 요소 추가
#추출 컬럼 join
df['output'] =df[col].apply(lambda row: ','.join(row.values.astype(str)), axis=1)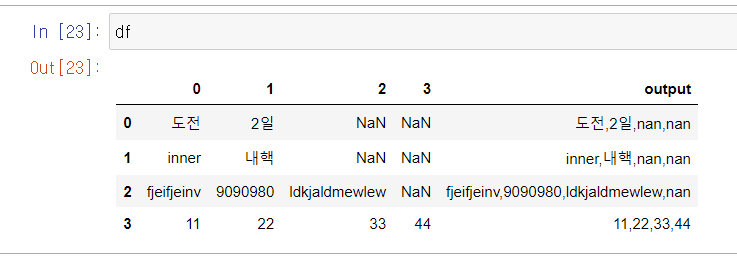
위의 들러붙은 nan과 끝부분의 쉼표를 정리를 해주자.
# nan 글자 지우기
df["output"]=df["output"].str.replace("nan,","").str.replace("nan","").replace(',$',"",regex=True)마지막으로 output 파일로 저장하면 작업이 마무리 된다
# output 파일 저장
df["output"].to_excel("output.xlsx")다음 번엔 엑셀 내의 기능으로 같은 결과를 도출할 수 있는 방법을 소개하려고 한다.

학습기록