만들게 된 계기
빌딩 구내식당 메뉴를 매일 받아보는 취지로 만들어보았다
해당 식당의 메뉴가 블로그 글을 매일 수정하는 방식으로 알려주기 때문에 전에 배웠던 웹크롤링을 어렵지 않게 사용할 수 있을 것 같은 느낌에 바로 도전
web crawling이란?
crawling
사전적 의미로는 기어다닌다는 뜻으로 웹에서 요청할 사이트에 들어가 필요한 정보를 수집하는 의미로 쓰인다

Web Scraping이라는 비슷한 용어도 있지만, 차이점이 있다면 스크래핑은 특정 정보를 가져오는 것을 목적으로 두고있고
크롤링은 자동화와 인터넷 사이트들을 인덱싱하는 것을 목적으로 두고 있다.
필요한 라이브러리
- requests
- BeautifulSoup4
requests
requests 라이브러리는 파이썬으로 http를 호출할 때 많이 쓰이는 라이브러리이다
import requests
url = 'https://m.blog.naver.com/blog_name/blog_page'
response = requests.get(url)
if response.status_code == 200: # 정상 연결시
#아래 코드들을 사용
else:
print(response.status_code)
url을 연결하고 response 했을 때 status_code가 200이 뜬다면 정상 작동하는 것이고
만약 다른 코드가 나온다면 해당 코드를 찾아보면서 오류의 원인을 찾아보면 된다
status code 종류
1xx (정보): 요청을 받았으며 프로세스를 계속한다
2xx (성공): 요청을 성공적으로 받았으며 인식했고 수용하였다
3xx (리다이렉션): 요청 완료를 위해 추가 작업 조치가 필요하다
4xx (클라이언트 오류): 요청의 문법이 잘못되었거나 요청을 처리할 수 없다
5xx (서버 오류): 서버가 명백히 유효한 요청에 대해 충족을 실패했다
페이지가 자동으로 연결 되었다면 BeautifulSoup 라이브러리를 이용하여 text들을 뽑아보자
BeautifulSoup
BeautifulSoup는 가져오고 싶은 페이지에서 원하는 html 태그를 가져올 수 있게 도와준다
import requests
from bs4 import BeautifulSoup
url = 'https://m.blog.naver.com/blog_name/blog_page'
response = requests.get(url)
if response.status_code == 200: # 정상 연결시
soup = BeautifulSoup(response.text, 'html.parser') # 수프 text 형태로 만들기위처럼 요청한 페이지를 text의 형태로 만들 수 있다
그리고, 크롬(또는 엣지 브라우저)에서 정보를 가져오고 싶은 페이지에서 F12키를 누르면 개발자 도구가 나오는데 여기에 있는 인스펙터를 이용하면 태그를 쉽게 찾을 수 있다
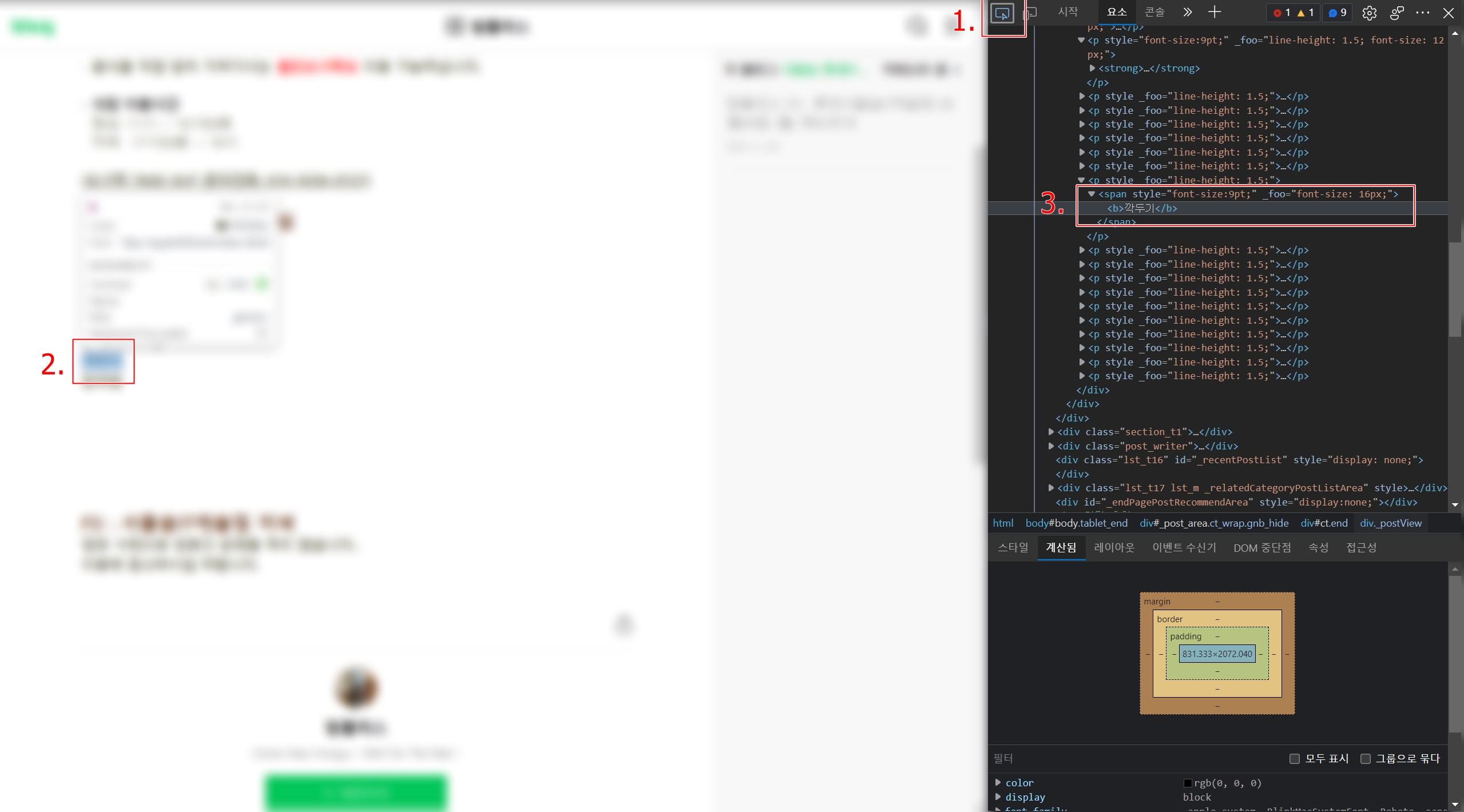
1. 인스펙터 클릭
2. 확인할 텍스트 영역에 마우스 커서를 위치한다
3. 개발자 도구에서 tag를 확인한다
위 단계를 통해 보다 쉽게 코드를 찾을 수 있다.
코드 작성
이제 코드를 작성해 보자
import requests
from bs4 import BeautifulSoup
url = 'https://m.blog.naver.com/blog_name/blog_page'
response = requests.get(url)
if response.status_code == 200: # 정상 연결시
soup = BeautifulSoup(response.text, 'html.parser') # 수프 text 형태로 만들기
text = str(soup.find(id='postViewArea')) # 본문 내용만 담긴 css 코드 뽑아내기
print(text.get_text().split('점심')[3].split('F3')[0]) # 점심메뉴 부분만 잘라내기
else:
print(response.status_code)get_text()를 통하여 텍스트 구문만 불러오기를 했더니 결과가 아래처럼 나와버렸다

차라리 html 코드영역을 통으로 뽑아내어 별도의 html을 만들어야겠다고 방향을 바꿨다
if response.status_code == 200: # 정상 연결시
soup = BeautifulSoup(response.text, 'html.parser') # 수프 text 형태로 만들기
text = str(soup.find(id='postViewArea')) # 본문 내용만 담긴 css 코드 뽑아내기
menu = text.split('점심</span>')[1].split('F3')[0] # 메뉴 나온 내용만 자르기
print(menu)
#div 태그의 특정 클래스를 가져오는 경우
text = soup.find("div", {"class":'se-module se-module-text'}).find_all('span') # 특정 클래스내에서 span부분 전부 정리

위와 같이 html 태그 덩어리를 잘라낸 다음에 새로운 html 파일에 집어 넣어 버리는 것이다
# 파일 열기 및 저장
f = open('C:/menu.html', 'w', encoding='utf-8') #utf-8로 인코딩해야 한글이 들어감
head = "<!DOCTYPE html> <html lang=\"ko\"> <head> <meta charset=\"UTF-8\"><title>menu</title> </head> <body>"
tail = "</body> </html>"
bobpl_contents = [head, menu, tail]
for i in bobpl_contents:
f.write(i)
f.close()빈 html 파일을 만들어서 위처럼 본문 내용만 갈아끼워 작업하는 것이다.

코드를 돌리면 이렇게 html 파일이 만들어진다
bat 파일 만들기 및 작업지정
처음 이 것을 만들게 된 목적이 매일 알아서 메뉴를 업데이트 하는 것이었다
매번 .py 파일을 실행시키기엔 번거롭기 때문에, 이 파일을 실행시켜줄 bat 파일을 만들고 매일 알아서 동작을 시키게 만들 것이다.
bat(배치 파일)은 기록된 명령어를 실행시켜주는 파일이다.
아래는 DOS의 명령어인데 bat파일에도 동일하게 동작하는 구문이므로 참고
ECHO – 화면에 텍스트 출력
@ECHO OFF – 출력되는 텍스트 감추기
START – 기본 프로그램으로 파일 실행
REM – 프로그램에 글자 입력
MKDIR/RMDIR – 디렉토리를 생성하거나 삭제
DEL – 파일 삭제
COPY – 파일 복사
XCOPY – 추가 기능에 따라 파일 복사
FOR/IN/DO – 파일 지정.
TITLE- 현재 창 이름 편집.
이제 menu파일을 실행시키는 코드를 작성
@echo menu crawling...
start cmd.exe /c "python C:/menu.py"
@echo menu crawling complete
PAUSE이렇게 작성한 코드는 메모장에서 다른이름으로 저장하기를 통해 .bat 파일을 만들어 쓸 수 있다.
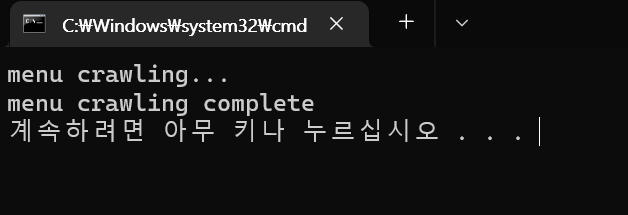
만들어둔 bat 파일을 실행하면 이렇게 잘 작동되는 것을 확인하였다.
이제 bat 파일을 원하는 시간에 돌려주는 작업이 남았는데, 작업 스케줄러를 통하여 특정 시간에 이 파일을 실행하도록 만들어 주었다.
윈도우즈의 [시작] 메뉴를 열어 '작업 스케줄러'를 검색하면 바로 앱을 찾을 수 있다
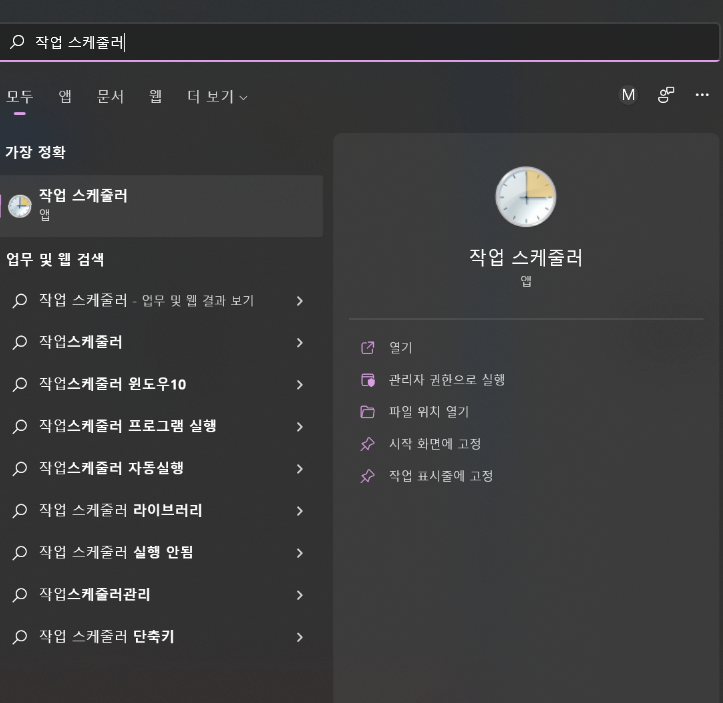
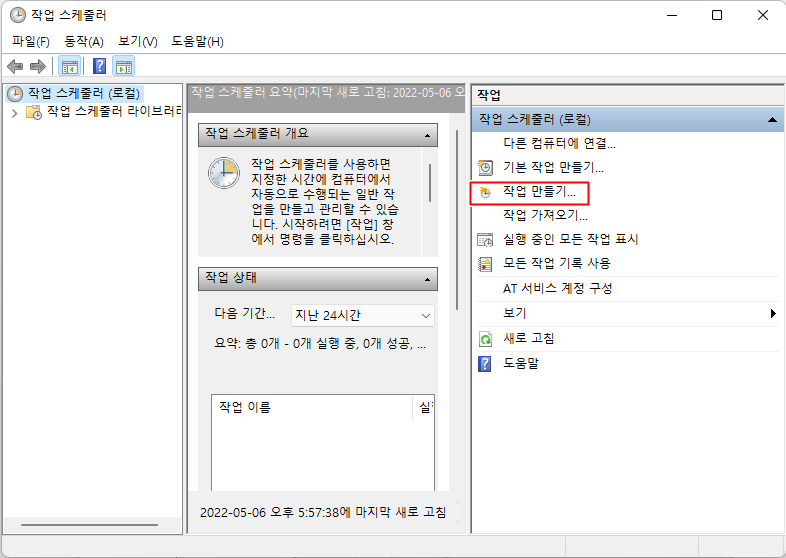
작업 스케줄러 내에서 [작업 만들기]를 통해 작업을 생성
일반 탭에서 작업의 이름과 설명을 기입할 수 있다
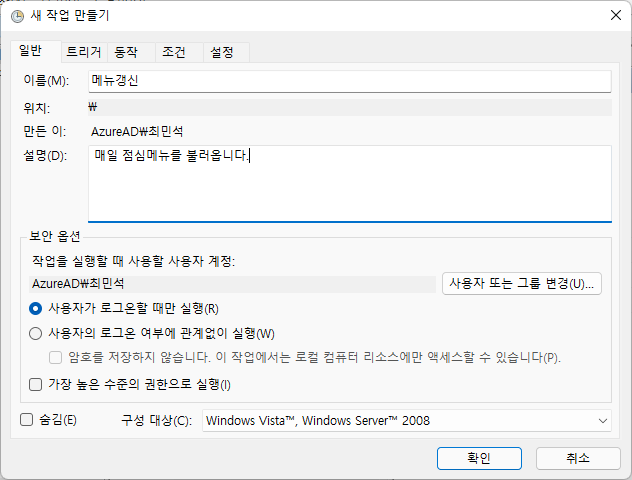
트리거 탭에서 작업이 시작하는 시간과 반복 주기를 설정할 수 있다.
새로 만들기를 통해 작업 트리거를 설정하였다
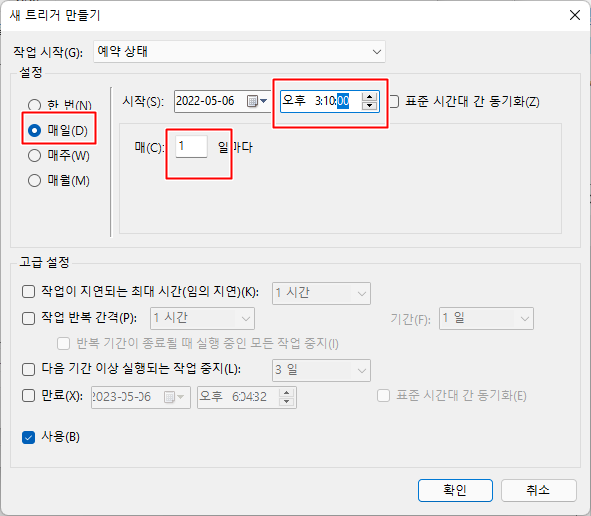
식당 블로그는 매일 3시마다 다음날 메뉴를 올리기 때문에 위 사진과 같이 세팅을 하였다
동작 탭으로 넘어가 실행할 파일을 설정하였다.
아까 만든 bat파일을 연결하여 파일을 시작하게 만들었다
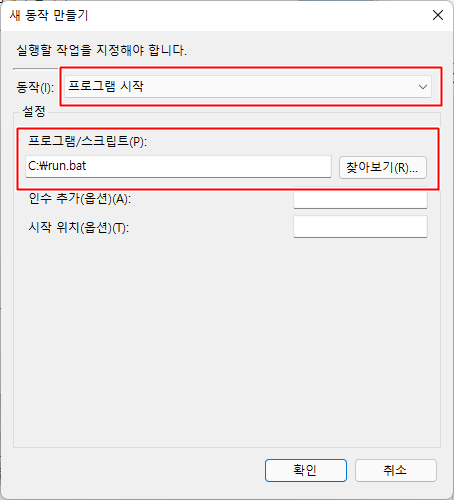
이제 작업이 만들어졌으니 컴퓨터가 켜저있는 동안 이 작업이 수행될 것이다.
