이전 포스트의 웹페이지가 서비스가 종료가 되었는지 파일을 불러올 수 없었다.
하는 수 없이 대안을 찾기 시작했고, 네이버의 환율창에 비슷한 테이블을 발견할 수 있었다.
이번엔 웹페이지의 테이블을 가져오는 방식을 통하여 pandas로 테이블을 만들어 보자.
필요한 라이브러리와 웹페이지를 불러오자
import pandas as pd
import requests
from bs4 import BeautifulSoup
#네이버 환율테이블 페이지 접근
url = 'https://finance.naver.com/marketindex/exchangeList.naver'
page = requests.get(url)웹페이지의 여러 tag부분을 발췌해야 하기 때문에 BeautifulSoup을 통하여 웹페이지의 tag들을 깔끔하게 불러오는 방식을 진행하였다.
soup = BeautifulSoup(page.content, 'lxml')웹페이지에서 개발자 도구(F12)를 열어서 페이지 구조를 확인할 수 있으니 참고하면서 가져올 범위를 찾아보자

가져올 table tag를 BeautifulSoup로 찾아서 선택해보자
#table tag 사용 범위 확인
text1 = soup.find('table')
# 현재 페이지에서 table 태그 모두 선택하기
table1 = soup.select('table')
# 하나의 테이블 태그 선택하기
table = tables[0]pandas의 read_html을 사용하여 table을 간편하게 가져올 수 있다.
# 판다스의 read_html 로 테이블 정보 읽기
table_df_list = pd.read_html(str(table1))
# 데이터프레임 선택하기
table_df = table_df_list[0]
table_df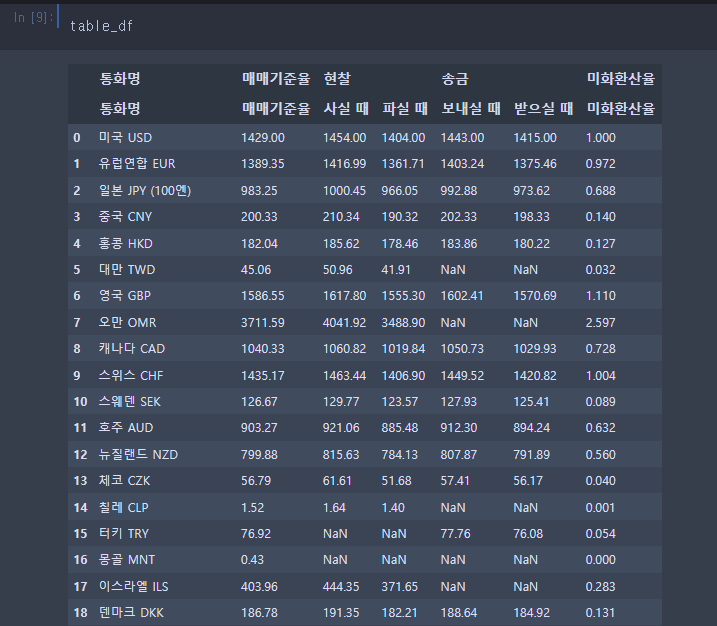
이렇게 만든 table을 excel로 저장하거나 다른 곳에 보내어 사용할 수 있다.

학습기록