
해당 스터디는 90DaysOfDevOps
https://github.com/MichaelCade/90DaysOfDevOps
를 기반으로 진행한 내용입니다.
Day 11 - Crafting & Validating Our Disaster Recovery Plan
1. 재해 복구 (DR) 개념
AWS의 특정 리전에서 때때로 장애가 발생하곤 한다. 핵심 서비스가 다운되고, 그에 의존하는 많은 서비스들이 함께 다운되곤 한다.
따라서, 아키텍처를 복원력 있게 설계하고, 모두가 다운될때 함께 다운되는 서비스 중 하나가 되지 않을 힘을 가지는 것이 중요하다.
AWS 문서에 나오는 복원력 (Resiliency) 의 정의
"부하, 공격, 그리고 실패로 인해 유발된 장애로부터 시스템이 복구할 수 있는 능력"
복원력 있는 아키텍처를 가졌다는 가장 좋은 지표 중 하나는 멋진 DRP (Disaster Recovery Planning) , 즉 재해 복구 계획을 가지고 있다는 사실이다.
❓ 그렇다면 DR 이란?
재해 (Disaster) + 복구 (Recovery)
해당 강의에서는 '프로덕션 리전의 장애' 라는 재해에 대처해야 되는 상황을 제시하였으며, 제안된 복구는 '멀티 리전 아키텍처'를 이용한 복구 아키텍처 구축이었다.
즉, 모든 재해는 상황에 따라 다르게 처리되어야 하며, DR (Disaster Recovery) 을 시작하기 전에 "내가 처리하는 재해는 무엇이고, 내가 제안하는 복구 방안은 무엇인가"를 스스로에게 물어보는 것이 중요하다.
2. 재해 복구 계획 (DRP) 아키텍쳐
재해 복구 계획(DRP : Disaster Recovery Planning)이란, 재해 발생 시,정해진 절차대로 혼선 없이 업무 복구 순서에 따라 체계적으로 복구할 수 있도록 수립한 절차와 문서의 집합이다.
이때, DRP는 투자수익률(ROI) 관점에서 접근해야 한다.
기술적인 설계를 시작하기 전에, 먼저 비즈니스 및 제품팀과 협력하여 재해 시 시스템에 요구되는 가용성 수준(SLA)을 명확히 정의해야 한다.
이 과정에서 DRP 구축 및 유지에 드는 비용과 시간이 그만한 가치가 있는지 모든 관련자가 합의하는 것이 중요하고 , 이처럼 비즈니스 요구사항이 확정되면 이를 바탕으로 실용적인 DRP 기술 아키텍처를 설계해야 한다.
DRP를 설계하기 위해 먼저 알아야할 몇 가지 기본 용어가 존재하는데, RPO와 RTO가 있다.
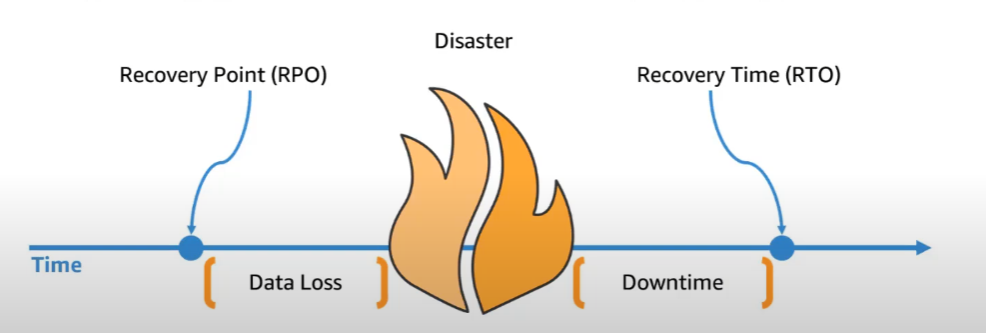
- RPO (Recovery Point Objective) : 복구 목표 시점
- 시스템이 다시 정상 가동되었을 때 시간을 얼마나 거슬러 올라갈 것인지
- 얼마나 많은 데이터를 잃게 될 것인지
- RTO (Recovery Time objectvie) : 복구 목표 시간
- 시스템이 다시 활성화되기까지 얼마나 걸리는지
즉, 낮은 RPO와 RTO 값은 다운타임과 데이터 손실을 줄이지만, 더 높은 비용과 운영 복잡성을 초래하게 된다.
요구되는 RTO와 RPO를 이해한 후, 일반적인 DRP 아키텍처에 대해서 알아보겠다.
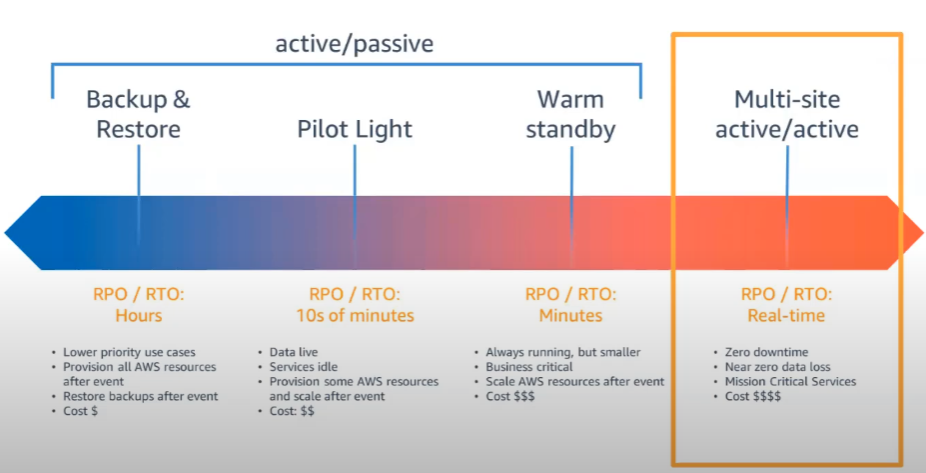
2-1 액티브-액티브 (Active-Active)
액티브-액티브 (Active-Active)는 실제로 선택할 수 있는 가장 비싼 아키텍처로, 운영환경과 DR 환경, 두 개의 환경이 항상 병렬로 실행된다.
예시로, 넷플릭스는 Active-Active-Active 아키텍처를 사용한다.
즉, 스타트업에서 해당 아키텍처를 구현시, 재해에서는 살아남더라도 운영비용측면에서 부담이 심해질 것이다.
2-2. 액티브-패시브 (Active-Passive)
이에 반대로, Active-Active 아키텍처보다 DR 품질이 RTO와 RPO 측면에서 저하되지만, 비용이 절감된다.
다만, 비용을 더 많이 절약할수록, 필요할 때 DR 환경을 완전히 운영 가능한 상태로 만들기 위해 추가적으로 운영자가 수행해야 할 조치들이 더 많아 진다.
2-3. 백업 및 복원 (Backup and Restore)
운영자가 가질 수 있는 최소한의 DRP로, 단지 몇분, 몇 시간, 몇일에 한번씩 데이터를 백업하는 아키텍쳐이다.
재해가 발생하면 별도의 준비 없이, 데이터 백업을 사용하여 처음부터 환경을 구축해야 한다.
2-4. 파일럿 라이트 (Pilot LIght)
데이터와 같이 가장 중요하고 복구에 시간이 오래 걸리는 핵심 서비스만 DR 리전에서 항상 실행한다. 하지만, 어플리케이션 서버와 같은 나머지 인프라는 설치는 되어있되, 평소에는 꺼져있는 상태로 운영하는 방식이다.
해당 아키텍처는 평소에는 꺼져있는 시스템이 존재하여 '웜 스탠바이'보다 저렴하지만, 복구시간 (RTO) 은 길다. (서버를 켜고 설정하는 데 시간이 걸리기 때문)
2-5. 웜 스탠바이 (Warm Standby)
DR 리전에 프로덕션 환경의 축소된 버전이 항상 실행되고 있으며, DB 복제본은 물론 최소한의 수의 어플리케이션 서버도 항상 켜져있는 아키텍쳐이다.
파일럿 라이트보다 비용이 많이 나가게 되지만, 복구시간 (RTO)가 매우 짧다.
즉, 목표로 하는 복구 시간(RTO)과 복구 시점(RPO)이 무엇이냐에 따라 선택해야 할 재해 복구(DR) 아키텍처가 달라지는 것이다.
'파일럿 라이트'나 '웜 스탠바이' 같은 아키텍처는 기술적 우위가 아닌, 우리 비즈니스가 감당할 수 있는 다운타임과 데이터 손실량에 맞춰 선택하는 것이다.
또한, 모든 서비스를 동일하게 보호할 필요는 없다. 핵심 서비스만 DRP에 포함하고 '있으면 좋은' 부가 기능은 제외함으로써 비용(ROI)을 최적화하는 것이 중요하다.
3. 클라우드 환경에서 멀티 리전 DR 구현 사례
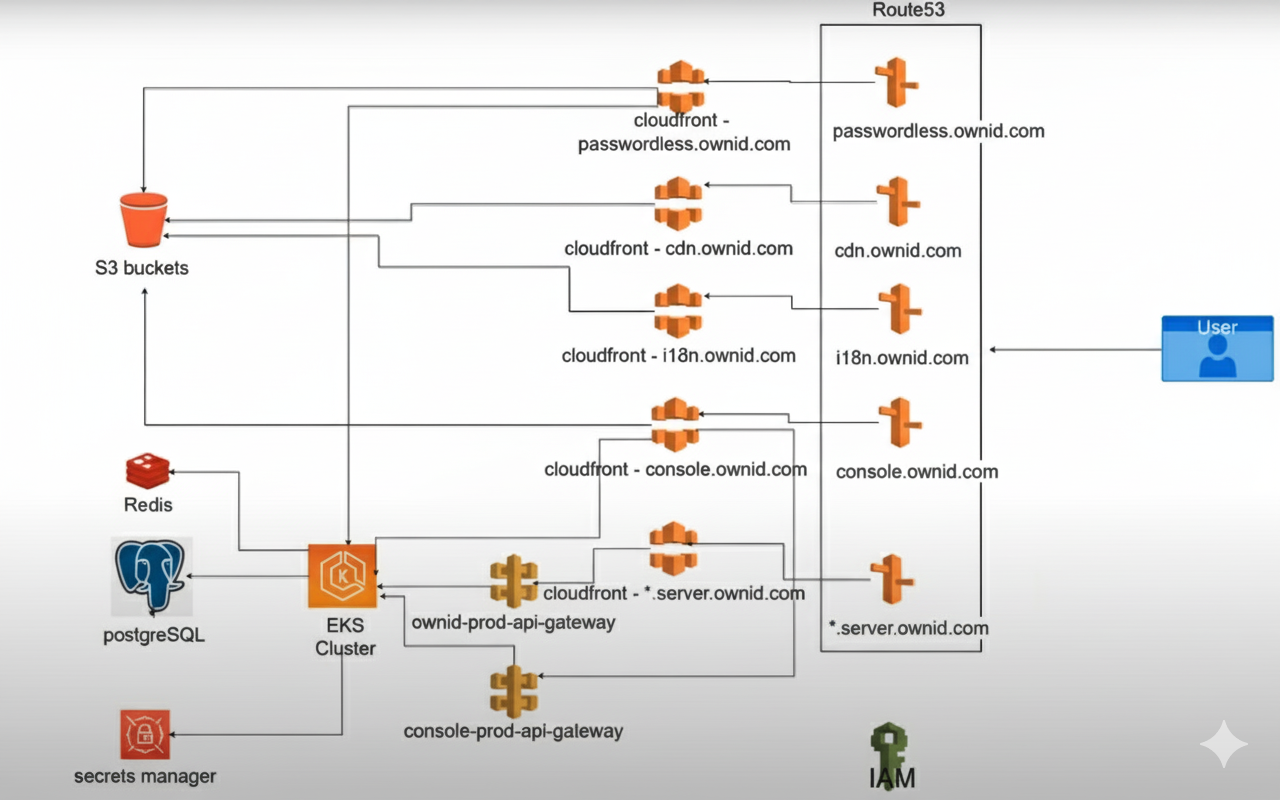
해당 아키텍처는 세션에서 예시로 제시한 아키텍처 워크플로우이다.
- 최종 사용자는 브라우저에서 관련 도메인으로 요청을 보냄
- AWS의 DNS 서비스인 'Route 53'은 CloudFront 배포를 참조
- EKS (쿠버네티스 클러스터)는 Postgres DB, Redis, Secrets Manager AWS 서비스와 통신
해당 방식처럼 1) DRP에 무엇이 포함되어야 하는지 먼저 알아본 후, 2) 리전(Regional) 종속성과 비리전(Non-Regional) 종속성을 정의해야 한다.
CloudFront, Route 53, IAM은 글로벌 서비스인 유일한 서비스들이다. 즉, 주 리전이 다운되더라도 해당 서비스들은 계속 작동할 것이라고 고려할 수 있다. (AWS가 뒤에서 이들의 복원력을 처리해줌)
그렇다면, 리전이 다운되면 사용할 수 없게 될 구성 요소는 S3, Redis, Postgres, Kubernetes, API Gateway, Secrets Manager임을 알 수 있다.
1단계: 시스템의 상태 저장(Stateful) 구축
데이터 도메인은 대부분의 경우 재해상황에서 처리하기 가장 복잡한 부분이 된다.
해당 케이스에서는 Postgres DB, Redis, Secrets Manager, S3 Bucket이 해당된다.
1-1단계 : RDS (Postgres DB)
RDS는 고객 설정의 원천이므로, 해당 강의에서는 다른 리전에 데이터 백업을 보장하기 위해, DR 리전에 '읽기 전용 복제본 (Read Replica)'를 구성하였다.
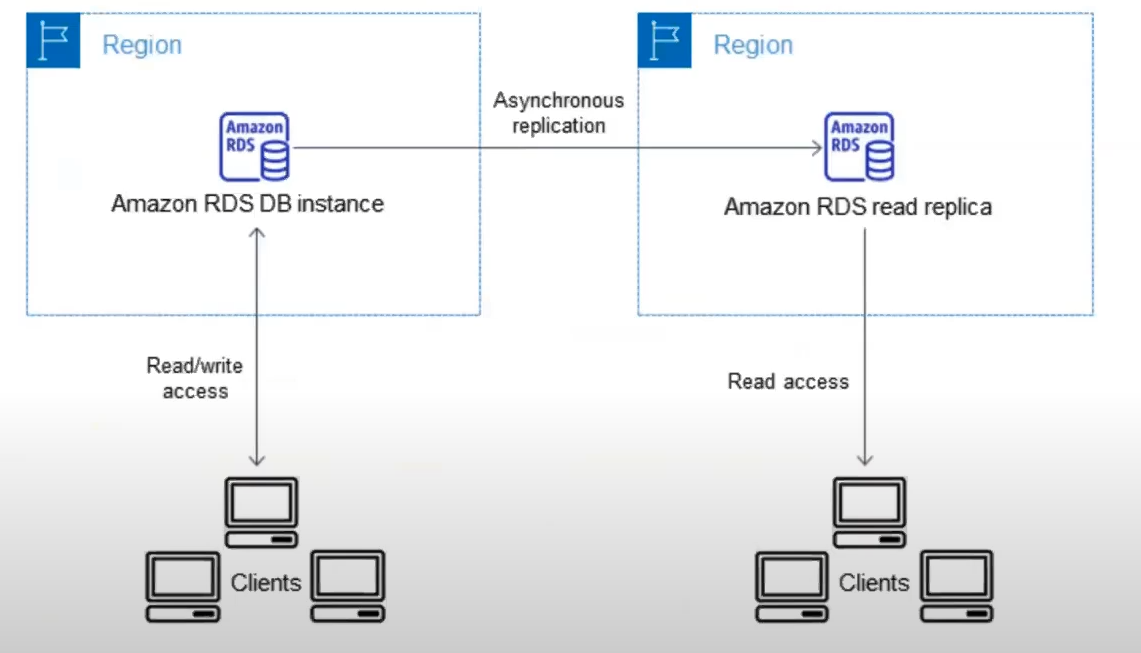
해당 읽기 전용 복제본은 주 복제본에 쓰기가 발생할 때마다 비동기적으로 업데이트되며, 이때 복제본의 지연시간은 몇 밀리초에서 몇 초 사이일 수 있으므로, 자신의 비즈니스가 감당할 수 있는 지연시간이면 적합한 방법이다.
이때, 주 리전을 사용할 수 없는 경우에는 읽기 전용 복제본을 주 복제본으로 승격시키게 되면, 해당 복제본이 주 DB가 된다.
1-2 단계 : Secrets Manager
1-1단계의 RDS 방식과 동일하게 DR 리전에 보안 암호 복제본을 구성하는 방식으로 Secret Manager를 구축하였다.
1-3 단계 : S3 Bucket
S3 버킷은 웹 앱 코드와 번역 파일 같은 정적 콘텐츠를 저장하기 위하여 사용한다.
해당 강의에서는 각 버킷에 대해 DR 리전에 동일한 버킷을 두기로 결정하였다.
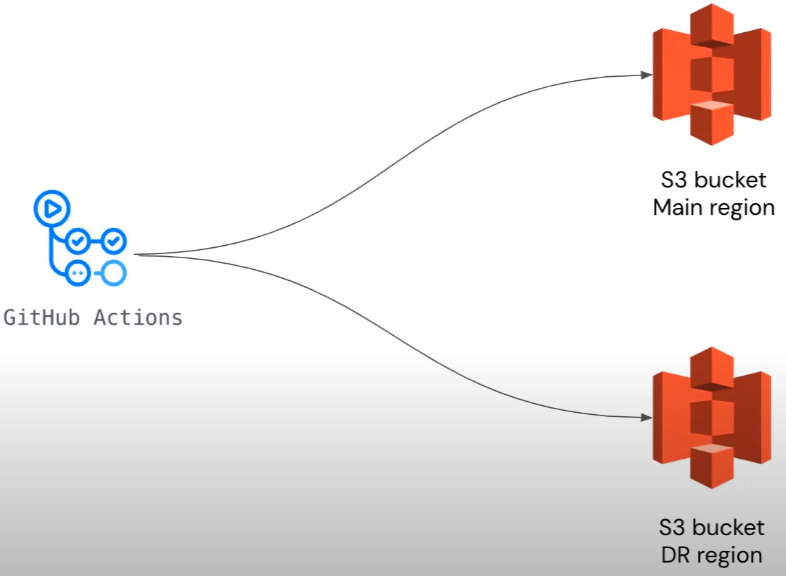
주 버킷과 그에 상응하는 백업 버킷에 콘텐츠를 업로드하고, 데이터가 자주 변경되는것이 아니라 배포시에만 변경되므로 CD 프로세스에서 수동으로 백업을 수행하는 방법을 사용하였다.
1-4 단계 : Redis
해당 강의에서는 재해 시에는 Redis 데이터를 잃어도 괜찮다고 판단하여 DRP를 단순화하기 위해 다른 리전에 복제본을 만들어 그 데이터를 백업할 필요가 없다고 결정하였다고 한다.
2단계: 글로벌 서비스 및 컨트롤/데이터 플레인 이해
AWS의 글로벌 서비스(CloudFront, Route 53, IAM)는 단일 리전 장애에 높은 복원력을 가지지만, 재해 시 기능이 저하될 수 있음을 이해해야 한다.
AWS 서비스는 컨트롤 플레인(Control Plane)과 데이터 플레인(Data Plane)으로 나뉜다.
- 컨트롤 플레인: 리소스 생성/변경/삭제 등 관리자 API 작업 (복잡하고 가용성이 상대적으로 낮음)
- 데이터 플레인: 데이터 읽기/쓰기 등 간단하고 일반적인 작업 (매우 높은 가용성)
재해 복구 시에는 컨트롤 플레인에 의존하는 작업을 피해야 한다. 예를 들어, 재해 발생 후 CloudFront의 오리진(원본 서버)을 DR 리전으로 변경하는 작업은 컨트롤 플레인 작업이므로 실패할 수 있다.
해결책: 컨트롤 플레인 의존성 제거
재해가 발생하기 전에 DR 리전을 가리키는 CloudFront 배포판, IAM 역할 등을 미리 생성해 두면, 재해 시에는 데이터 플레인 작업인 DNS 트래픽 전환 (Route 53)만으로 빠르고 안정적인 복구가 가능하다.
3단계: 인프라 코드(IaC)를 통한 관리
Terraform과 같은 인프라 코드(IaC) 도구를 사용하면 프로덕션 환경과 DR 환경을 일관되게 관리할 수 있다.
코드를 세 가지 유형으로 나누어 관리하면 효율적이다.
- 동일하게 복제할 구성 요소: 쿠버네티스 클러스터, API 게이트웨이 등
- 다르게 구성할 구성 요소: 주 데이터베이스 vs 읽기 전용 복제 데이터베이스
- 재사용할 구성 요소: Route 53 레코드 등
이를 통해 DR 환경 구축을 자동화하고, 두 환경 간의 설정 차이를 최소화하여 관리 복잡성을 줄일 수 있다.
4. 재해 복구 계획 (DRP)의 지속적인 검증과 개선
DRP는 한 번 만들고 끝나는 문서가 아니다. 지속적으로 테스트하고 검증하지 않는 DRP는 없는 것과 마찬가지이다.
4-1. 상세한 실행 계획 문서화
모든 복구 절차를 상세하게 문서화해야 한다. 재해 상황에서는 누구나 당황할 수 있으므로, 시스템을 잘 모르는 사람도 문서를 보고 따라 할 수 있을 정도로 구체적이어야 한다.
가장 좋은 방법은 첫 번째 DR 모의 훈련을 진행하면서 실제 수행하는 작업을 그대로 문서로 옮기는 것이다.
4-2. AWS 검증 도구 활용
AWS는 DRP를 검증하고 개선하는 데 도움이 되는 훌륭한 도구들을 제공한다.
-
AWS Resilience Hub: 인프라 전체를 스캔하여 복원력 수준을 평가하고, 'RDS가 다중 AZ 구성이 아니다' 와 같은 개선점을 찾아주는 리포트를 제공
-
AWS Fault Injection Simulator (FIS): 카오스 엔지니어링(Chaos Engineering) 도구로, 의도적으로 장애를 주입하여 시스템이 어떻게 반응하는지 테스트 가능함. ( ex. 핵심 서비스 파드(Pod) 4개 중 3개를 강제로 종료시켜 연쇄적인 장애 발생 여부를 확인)
4-3. 카오스 엔지니어링을 통한 지속적인 개선
가설만 세우는 대신, 실제로 장애를 주입하고 시스템의 반응을 관찰하는 것이 최고의 검증 방법이다. 카오스 엔지니어링은 다음과 같은 무한한 개선 루프를 만들어 냅니다.
안정 상태 확인 → 가설 수립 → 장애 실험 실행 → 결과 검증 → 시스템 개선 → 다시 실험
이러한 과정을 조직의 문화로 정착시켜, 실제 재해가 발생했을 때 작동하지 않을 이론적인 DRP가 아닌, 실전에서 검증된 강력한 DRP를 갖추는 것이 최종 목표가 되어야 한다
5. 결론: 성공적인 DRP의 핵심 원칙
성공적인 재해 복구 계획(DRP)은 단순히 기술적인 구축을 넘어, 비즈니스 가치(ROI)에 기반한 전략적 선택에서 시작한다. 자신의 비즈니스에 대한 목표 RTO/RPO를 명확히 정의하여 아키텍처를 선택하고, 핵심 서비스에 집중하여 비용 효율성을 확보하는 것이 가장 중요하다.
또한, DRP는 한 번 만들면 끝나는 것이 아니라 '살아있는 문서'가 되어야 한다.
카오스 엔지니어링과 같은 지속적인 테스트와 검증을 통해 실제 재해 상황에서도 신뢰할 수 있는 계획을 유지하는 것이 무엇보다 중요하다.
