
해당 스터디는 90DaysOfDevOps
https://github.com/MichaelCade/90DaysOfDevOps
를 기반으로 진행한 내용입니다.
Day 12 - Know your data: The Stats behind the Alerts
1. 모니터링에 통계가 필요한 이유
모니터링은 본질적으로 '숫자 게임'이다.
우리가 수집하는 Metric은 시스템의 특정 동작을 나타내는 숫자들의 연속이며, 대두분 타임스탬프 및 관련 속성 (Key-Value 쌍)과 함께 제공된다.
하지만, 시스템과 어플리케이션에서 분출되는 방대한 양의 데이터를 그대로 바라보는 것은 모든 서버의 시스템 로그를 동시에 실시간으로 지켜보는 것과 같이 무의미하다.
데이터로부터 의미있는 정보를 얻기 위해서는 반드시 집계, 분석, 시각화 과정이 필요하다.
통계는 바로 이 과정의 핵심 도구로, 다량의 원시 데이터 속에서 패턴을 발견하고 시스템의 상태를 정확하게 이해할 수 있도록 돕는다.
2. 중심 경향성 (Central Tendency)
데이터의 '중심 경향성 (Central Tendency)'를 파악하는 것은 분석의 첫걸음이다.
평균, 중앙값, 최빈값을 사용하여 DevOps의 목적에 따라 다양한 측정 방법을 활용해야 한다.
2-1. 평균 (Mean)
-
산술 평균 (Arithmetic Mean) : 가장 일반적인 평균으로, 모든 값을 더해 개수로 나눔
- DevOps 활용: 시스템 성능의 기준선(Baseline)을 설정하는 데 주로 사용됨.
- ex) '평소 시간당 평균 요청 수' 나 '평균 CPU 사용률' 같은 기준선을 설정하고, 현재 산술 평균이 이 기준선에서 크게 벗어날 때 경고를 발생시키는데 활용 가능
-
기하 평균 (Geometric Mean) : 모든 값을 곱한 후 n제곱근을 취하는 평균. 이전 결과에 영향을 받아 복리처럼 쌓이는 값들의 평균 변화율을 계산하는 데 최적화 되어있음.
- DevOps 활용: 지속적인 개선율을 측정할 때 유용
- ex) 여러 스프린트에 걸쳐 배포 시간을 각각 5%, 10%, 7% 단축했을 때, 전체적인 평균 개선율이 얼마인지 정확히 계산하려면 기하 평균을 사용해야 함. (산술 평균은 복합적인 개선 효과율을 왜곡할 수 있음.)
-
조화 평균 (Harmonic Mean): : 값들의 역수를 이용해 계산하며, 가장 낮은 값에 더 큰 가중치를 두는 평균 방식
- DevOps 활용: 여러 서버로 구성된 클러스터의 최악 성능 (Worst-case performance)을 감지하는 데 탁월
- ex) 3대의 서버가 각각 초당 100, 200, 300개의 요청을 처리하다가 한 대의 성능이 초당 10개로 급격히 저하되면, 산술 평균은 크게 변하지 않지만 조화 평균은 급락함. 따라서 클러스터 내의 병목 현상을 감지하는 데 훨씬 민감한 지표
2-2. 중앙값 (Median) 과 이상치
중앙값은 정렬된 데이터셋에서 정확히 가운데에 위치하는 값이다. 해당 값의 가장 큰 특징은 '이상치 (Outlier)에 대한 저항성'이다.
시스템 장애나 트래픽 급증으로 인해 비정상적인 값이 발생했을 때, 평균은 그 값에 즉시 크게 영향을 받아 왜곡되고 회복도 느리다.
반면, 중앙값은 하나의 이상치에 거의 영향을 받지 않으며, 시스템이 안정화되면 즉시 정상 수치로 돌아온다.
이러한 중앙값의 특성 덕분에 '이상 탐지 (Anomaly Detection) 및 응답 시간 (Response Time) 모니터링'에 매우 유용하다.
일시적인 이상치 스파이크로 인한 경고 피로를 줄이고 시스템의 안정적인 상태를 더 정확하게 파악할 수 있다.
서비스 수준 목표 (SLO, Service-Level Objective: 구체적인 수치의 품질 약속) 의 기반이 되는 P50 (50th percentile: 전체 요청 중 중간 수준의 성능) 지연시간과 같은 핵심 지표로 사용하기에 이상적이다.
극단적인 이상치 사례는 무시되고 대다수의 사용자가 경험하는 안정적인 성능을 기준으로 품질을 판단할 수 있기 때문이다.
2-3. 최빈값 (Mode)
최빈값은 데이터셋에서 가장 빈번하게 나타나는 값으로, 실시간 경고보다는 주로 다음과 같은 추론적인 분석에 사용된다.
- 로그 분석: 가장 빈번하게 발생하는 오류 코드 (ex: HTTP 502)를 찾아내 문제 해결의 우선순위를 정함
- 보안 모니터링: 시스템을 공격하는 가장 흔한 IP 주소나 공격 벡터를 식별함
- 사용자 행동 분석: 사용자들이 가장 많이 사용하는 기능이나 이동 경로를 파악하여 서비스 최적화에 집중함
3. 변동성 측정과 샘플링의 함정
중심 경향성(평균, 중앙값 등)만으로는 데이터의 전체 그림을 볼 수 없다.
"중앙값은 16"이라는 정보만으로는 부족하지만, "68의 범위 내에서 중앙값은 16"이라고 하면 데이터의 분포를 훨씬 더 잘 이해할 수 있다.
이처럼 데이터가 얼마나 흩어져 있는지를 나타내는 변동성(Variability)을 함께 파악해야 한다.
3-1. 변동성 측정과 이상치 탐지
사분위수 범위 (Interquartile Range, IQR): 데이터를 정렬했을 때 하위 25% 지점(Q1)과 상위 75% 지점(Q3) 사이의 범위를 의미한다. IQR은 이상치(Outlier)를 식별하는 유용한 경험 법칙의 기준이 된다.
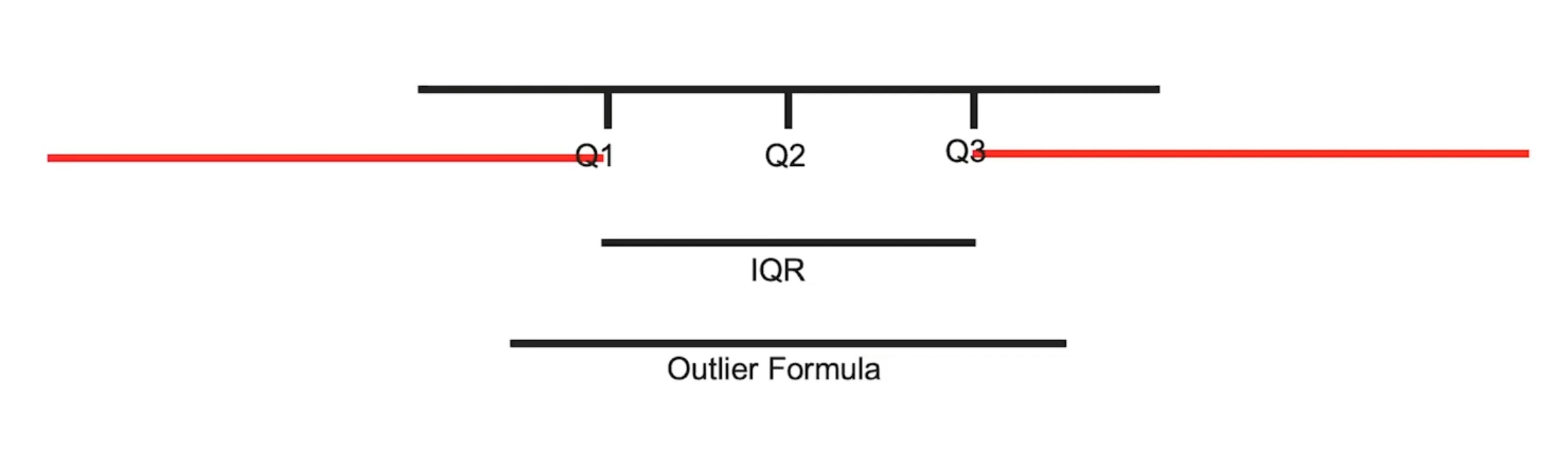
경험 법칙: Q1 - 1.5*IQR 보다 작거나 Q3 + 1.5*IQR 보다 큰 값은 이상치일 가능성이 높다고 판단하는 법칙
-> 통계적으로 증명된 법칙은 아니지만, DevOps 환경에서 '정적 임계치를 넘어선 동적이고 지능적인 경고 시스템을 구축'하는 데 효과적인 기준을 제공한다.
3-2. 샘플링의 함정
모든 데이터를 저장하고 분석하는 것은 현실적으로 불가능하다.
예를 들어, 한 기업은 시간당 46TB의 로그를 처리했으며, 트레이싱을 추가하자 그 양은 시간당 93TB로 늘어났습니다. 이러한 막대한 데이터량 때문에 우리는 샘플링(Sampling)에 의존할 수밖에 없다.
하지만 샘플링은 '필요악'이며, 심각한 맹점을 가진다.
- 기술 통계 : 전체 데이터를 분석하는 것
- 추론 통계 : 일부 샘플로 전체를 추정하는 것
샘플링은 우리를 추론의 영역으로 이끌며, 필연적으로 정보 손실을 감수해야 한다.
이때, 샘플링 중 무작위로 데이터를 추출하는 '헤드 기반 샘플링'은 시스템에 심각한 문제를 일으키는 결정적인 이상치를 누락시킬 수 있다.
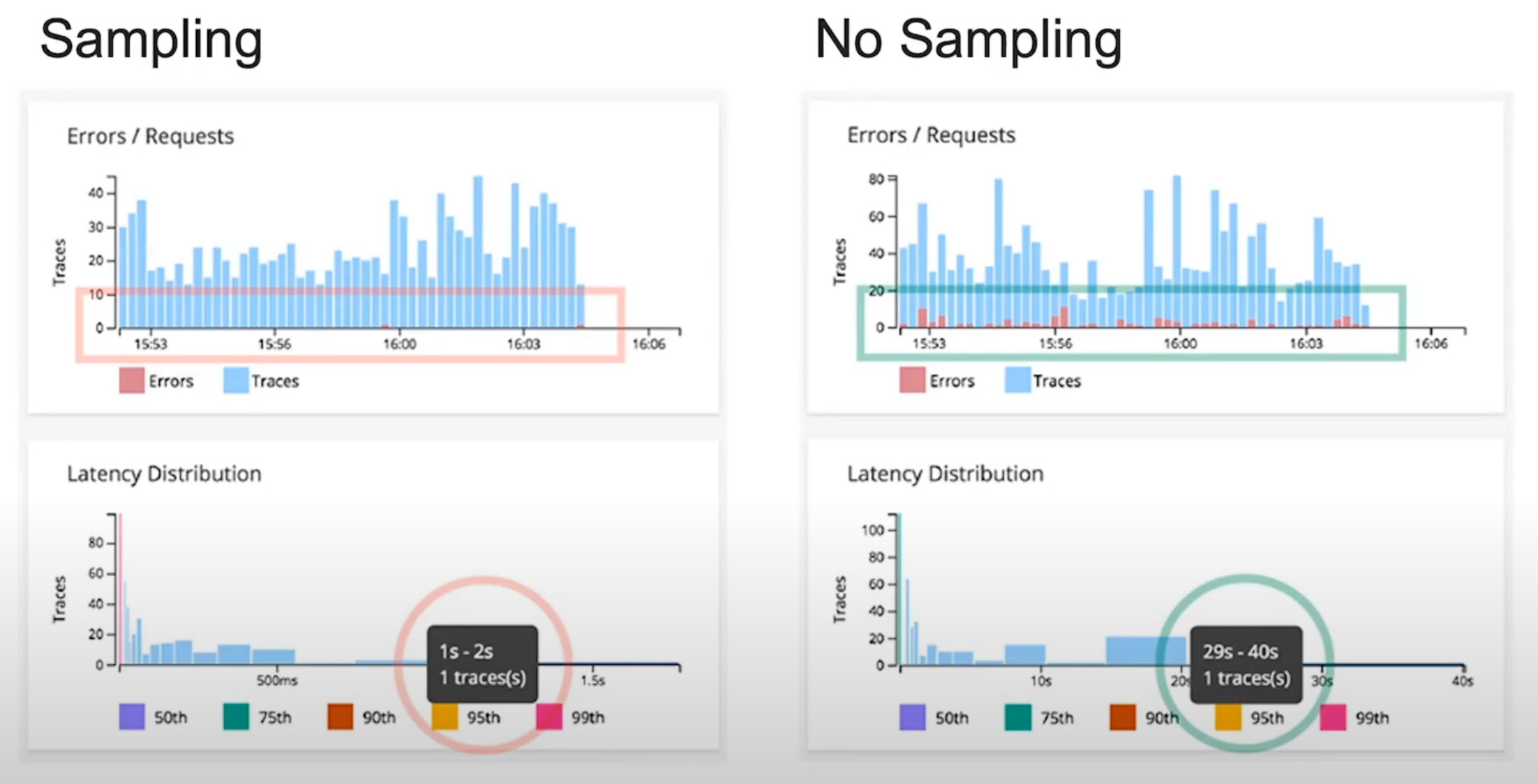
한 시스템의 데이터를 샘플링했을 때는 오류가 거의 없고, 95% 지연시간이 1~2초로 나타났다.
하지만, 전체 데이터를 분석했을 때는 다양한 오류가 발견되었으며, 29~40초에 달하는 치명적인 지연 시간 스파이크가 존재했다.
이처럼 샘플링은 '선택 편향 (Selection Bias)'를 만들어내고, 가장 중요한 문제점을 숨길 수 있다는 심각한 맹점을 가지고 있다.
4. 분포와 확률
4-1. 데이터 패턴 이해를 위한 분포
데이터의 패턴을 이해하기 위해 다양한 분포(Distributions)를 활용할 수 있다.
- 정규 분포 (Normal Distribution): 벨 모양 곡선으로, 리드 타임이나 복구 시간처럼 평균을 중심으로 대칭적인 데이터를 모델링하는 데 사용된다.
- 지수 분포 (Exponential Distribution): 네트워크 요청 간의 시간처럼 서로 독립적인 이벤트 사이의 시간을 모델링하는 데 적합하며, 지연 시간(Latency) 분석에 특히 유용하다.
4-2. 확률에 대한 새로운 관점
-
동전 던지기는 50:50이 아니다 : 동전 던지기는 물리학의 영향을 받는다. 35만 번의 동전 던지기 실험 결과, 50.8%의 확률로 동전은 던지기 시작한 면이 위로 나오는 경향이 있었다. 이는 우리가 가진 데이터가 많아질수록 확률에 대한 이해가 바뀔 수 있음을 시사한다.
-
베이즈 정리 (Bayes' Theorem) : 새로운 데이터가 주어졌을 때 기존의 확률을 업데이트하는 강력한 도구
- 대표적인 예시 : 몬티 홀 문제 (세 개의 문 중 하나에 차가 있고, 당신이 문 하나를 고른 뒤 진행자가 다른 문 뒤의 염소를 보여줬을 때, 선택을 바꾸는 것이 유리)
- DevOps 활용 : 예측 모니터링(예: 메모리 증가 패턴을 기반으로 장애 가능성 예측)이나 A/B 테스트 최적화 등에 활용될 수 있음.
5. 결론
통계는 DevOps 엔지니어와 SRE가 시스템에서 발생하는 수많은 메트릭을 정확히 측정하고 이해하기 위한 필수적인 방법론이다.
통계는 개별 데이터가 아닌 집계된 행동을 보여주며, 데이터의 특성에 맞는 올바른 통계 도구를 선택함으로써, 단순한 숫자 너머의 깊은 통찰력을 얻고 더 빠르고 정확한 의사결정을 내릴 수 있다.
이 모든 분석의 본질은 개발자 브라이언 커니핸의 말에 담겨있다.
"가장 효과적인 디버깅 도구는 여전히 신중한 생각과 적재적소에 배치된 print문이다."
브라이언 커니핸 (1979)
이 말은 오늘날의 DevOps 환경에 그대로 적용된다. 과거의 print문이 코드 속 변수 하나를 보여주는 '돋보기'였다면, 오늘날 우리의 print문은 시스템 전체를 들여다보는 '현미경'과 같다는 의미이다.
- 과거의 print문: 코드 한 줄로 변수 값 하나를 확인.
- 오늘날의 print문: 메트릭, 로그, 트레이스를 통해 시스템의 상태 전체를 확인.
문제 해결은 여전히 '신중한 생각'과 '내부를 들여다보는 행위'에서 시작된다. 다만 이제는 그 행위를 통해 시스템 전체를 훨씬 더 깊고 명확하게 이해할 수 있는 강력한 도구를 갖게 된 것이다.
