- 실제 강의 내용의 일부분만 발췌했습니다.
<웹 데이터>
<결과데이터>
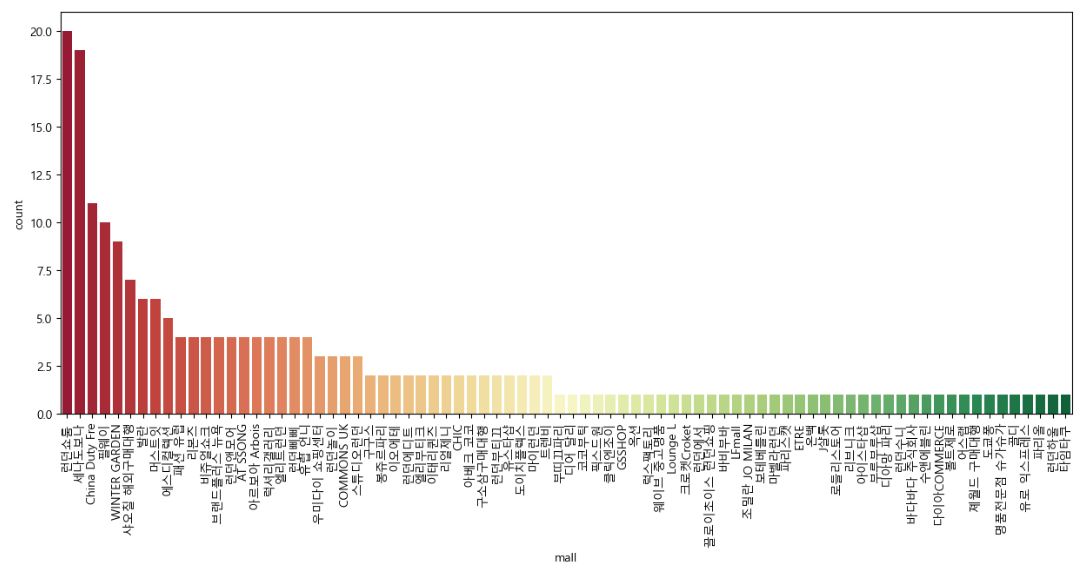
네이서 쇼핑에 샤넬을 검색했을 때 상위 1000개의 데이터를 분석하여 네이버 자사몰을 제외한 쇼핑몰별 검색 노출 빈도를 조사해보자
import os
import sys
import urllib.request
import pandas as pd
# api_node : 쇼핑몰, 영화, 책 등 어느 카테고리에서 검색할 지 지정
# search_text : 찾는 키워드
# start_num: 처음 노출되는 콘텐츠가 몇번째 콘텐츠인지 지정
# disp_num: 총 노출되는 콘텐츠가 몇 개인지 지정
# 지정한 쿼리대로 호출하는 URL 생성 함수
def get_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node +".json"
param_query = "?query="+urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp
# 해당 url 데이터를 json 데이터로 읽어옴
def get_result_onpage(url):
request = urllib.request.Request(url)
client_id = "**네이버에서 할당해준 ID**"
client_secret = "**네이버에서 할당해준 비번**"
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
return json.loads(response.read().decode("utf-8"))
# 샤넬을 검색하기 전에 몰스킨으로 먼저 검색해서 데이터 형태를 보자.
url = get_search_url("shop","몰스킨", 1, 5)
one_result = get_result_onpage(url)
one_result
딕셔너리 형태로 데이터가 담아져 있고, 'items'라는 키워드가 우리가 원하는 데이터를 요소로 갖고 있는 list를 값으로 짝 지어져 있는 것을 확인할 수 있다.
print(one_result["items"][0]["title"])
print(one_result["items"][0]["lprice"])
print(one_result["items"][0]["mallName"])다니엘크레뮤 22FW 헤비 코튼 몰스킨 팬츠 3종
103340
네이버
result_mol = []
for n in range(1, 1000, 100):
url = get_search_url("shop","샤넬", n, 100)
json_result= get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)
result_mol.reset_index(drop=True, inplace= True)
result_mol.tail()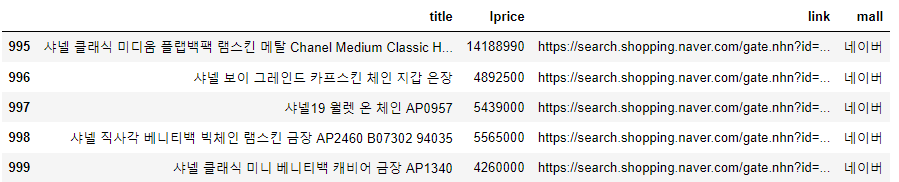
# 네이버 자사몰은 제외하고 나머지 데이터를 분석해보자
result_mol = result_mol[result_mol["mall"] != "네이버"]
plt.figure(figsize = (15, 6))
sns.countplot(
x = result_mol["mall"],
data = result_mol,
palette = "RdYlGn",
order = result_mol["mall"].value_counts().index
)
plt.xticks(rotation = 90)
plt.show()

쉽고 유익하게 널리널리