제로베이스 강의요약
1.(파이썬 강의 중급) 함수 문법 요약

매개변수는 없을 수 있다.return 값도 없을 수 있다.함수 안에 다른 함수를 다시 호출할 수 있다.함수를 선언했을 때 매개변수의 수와 함수를 호출할 때 인수의 수는 같아야 한다.함수를 선언할 때 return을 선언했어서 반환하는 결과값이 있도록 정의되었다면, 해당
2.(파이썬 강의 중급) 모듈 문법 요약
44, 55, 36, 47, 100도입하고 싶은 모듈 앞에 import를 붙여 모듈을 불러온다.모듈명.모듈내함수명(인수)를 통해 모듈이 가지고 있는 함수들을 사용한다.'from 모듈명 import 함수명'으로 모듈 내 특정 함수만 사용할 수 있다.'from 모듈명 im
3.(EDA강의)Pandas 기초
서울특별시를 대상으로 구별로 집계된 신규 설치 CCTV 개수 데이터와 구별로 집계된 인구 수 데이터를 가공해서 합친 뒤 상관관계를 분석해보자.
4.(EDA강의)matplotlib 기초
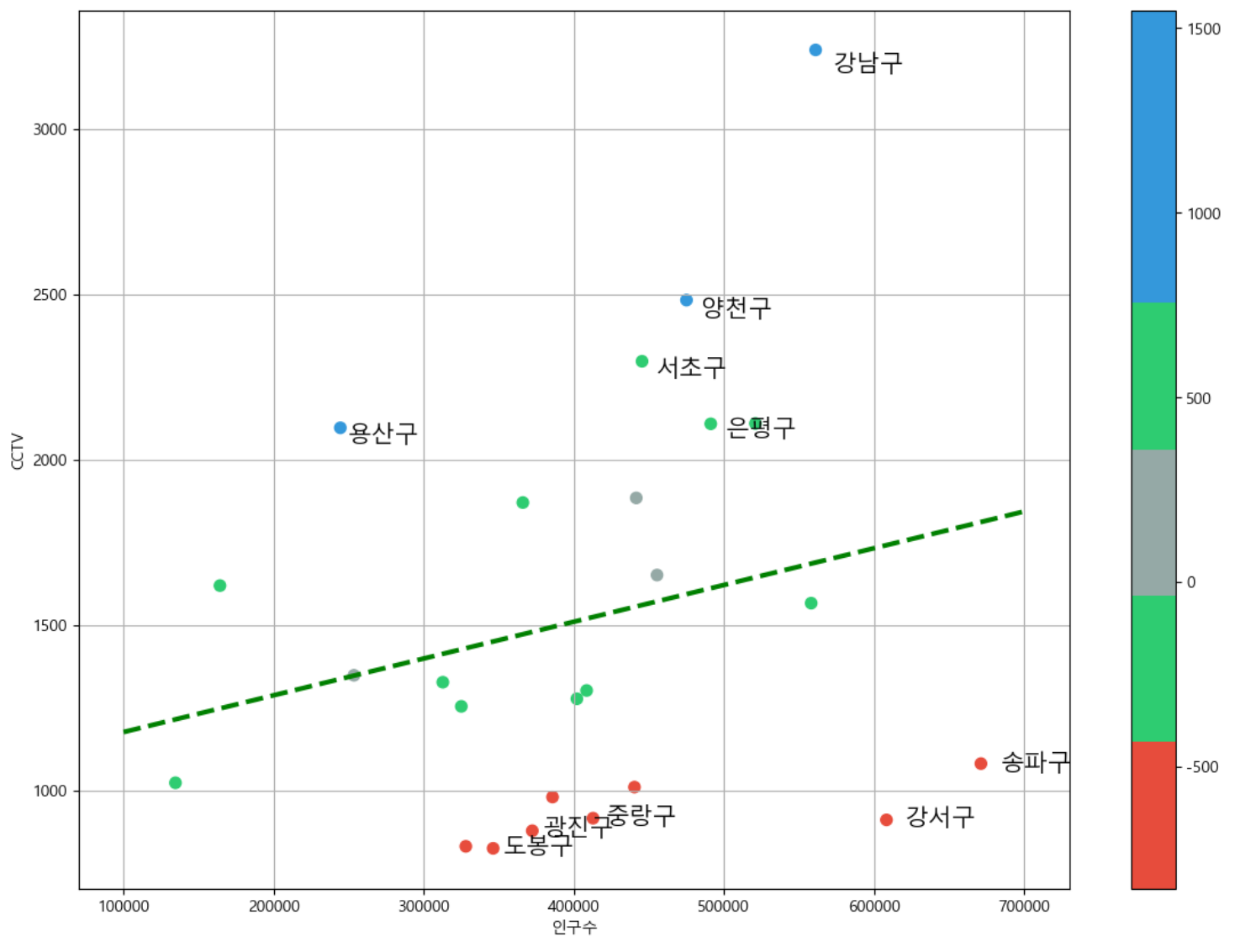
구별 인구수와 CCTV 설치 대수의 산포도 및 추세선을 그려보고 경향에서 크게 벗어난 데이터를 강조해보자기타 matplotlib 기초
5.(EDA강의)Pandas의 Pivot Table
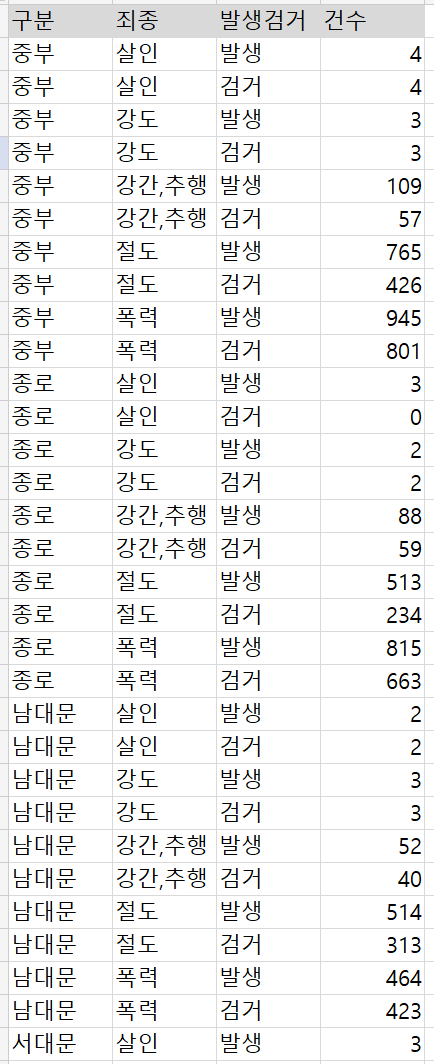
<원본데이터>경찰서별 5대 범죄 발생 검거 현황<가공 후 데이터 형태>pandas pivot table 기능을 활용하여 서울시 경찰소별 5대 범죄 현황 데이터를 가공해보자데이터는 65,534개인데 그중 실제로 정보가 담겨져 있는 데이터는 310개이고 나머지는
6.(EDA강의)Google Maps API 사용
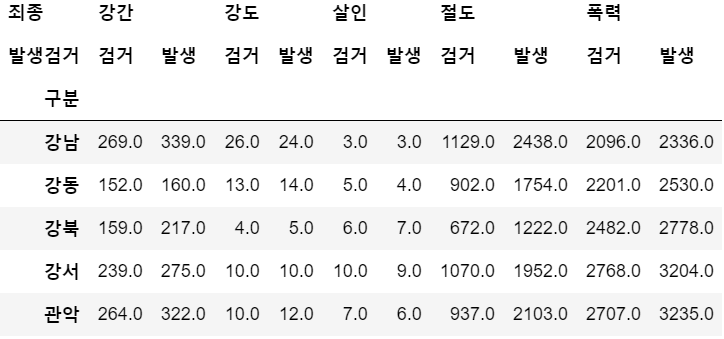
<1차 가공데이터> - 경찰서 기준으로 분류된 데이터<2차 가공데이터> - 행정구역 기준으로 분류된 데이터Google Maps API를 사용하여 경찰소 기준으로 분류된 데이터를 행정구역 기준으로 분류된 데이터로 가공하자연관 포스팅 구글맵 API 키 할당 받는
7.(EDA강의)seaborn으로 데이터 시각화
실제 강의 내용의 일부분만 발췌했습니다. seaborn 기초
실제 강의 내용의 일부분만 발췌했습니다.boxplot은 1분위수(상위 25%)부터 3분위수(상위 75%)까지 box로 나타낸 그래프box 가운데 선은 중위수(상위 50%)를 나타낸다.box 폭이 좁을 수록 밀집되어 있음을 뜻한다.box plot 밖의 점은 아웃라이어다.
9.(EDA강의)folium 기초
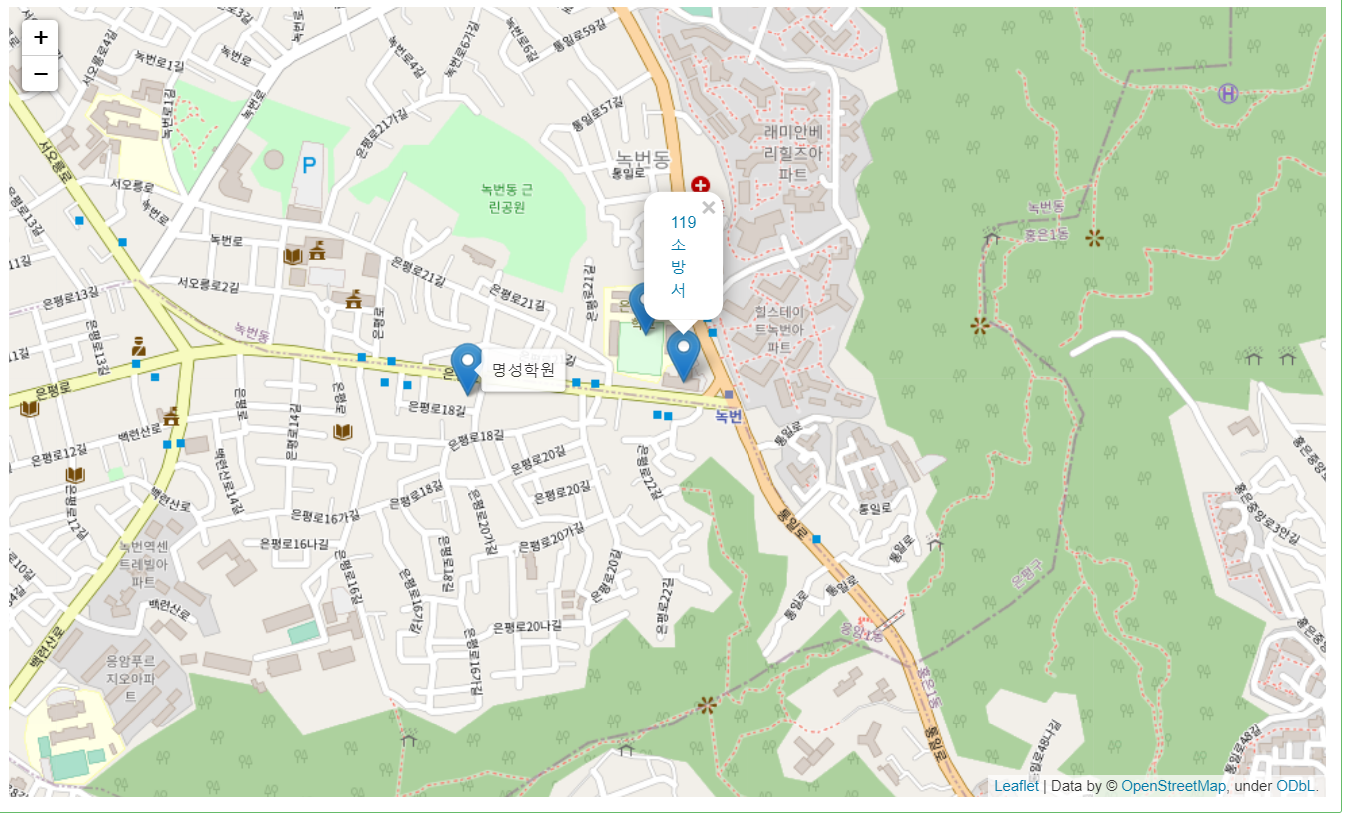
실제 강의 내용의 일부분만 발췌했습니다.
10.(EDA강의)folium으로 데이터 시각화
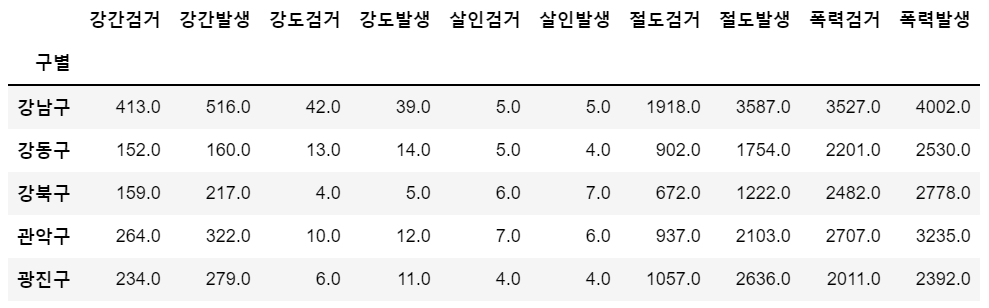
실제 강의 내용의 일부분만 발췌했습니다.<원본 데이터 1>직전 포스팅 데이터에서 살인, 강도, 성범죄, 절도, 폭력을 정규화정규화란 0에서 1사이 값으로 변환한 것으로 컬럼/(컬럼.max())로 구함<원본 데이터 2><결과 데이터>서울시 구별로 인구수
11.(EDA강의)BeautifulSoup으로 웹스크랩핑
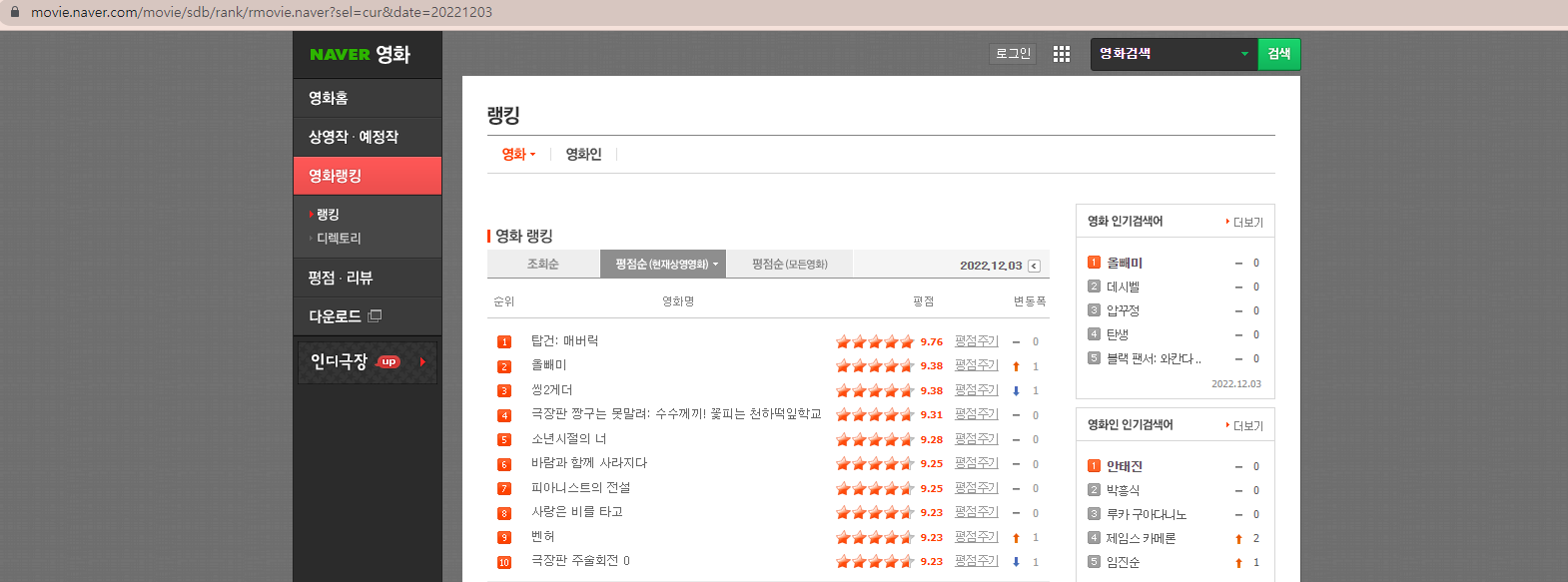
실제 수업 내용 중 일부분만 발췌하였습니다.아직 작성 중인 포스팅입니다.(미완)<크롤링하고자 하는 페이지><결과 그래프>날짜별로 영화 평점을 표현해보자
12.(EDA강의)BeautifulSoup 기초
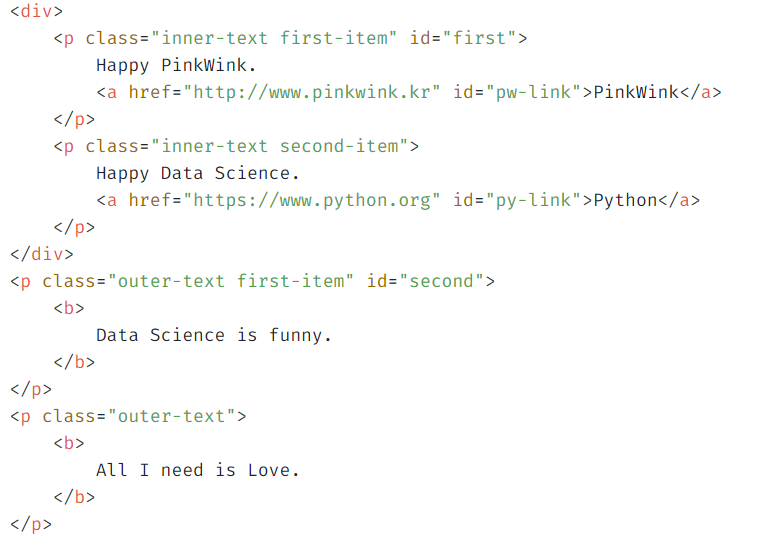
실제 강의 내용의 일부분만 발췌했습니다.<크롤링하고자 하는 페이지 html 중 body>
13.(EDA강의)크롬 개발자 도구 기초
<크롤링 하고자 하는 페이지><결과 데이터>대표적인 12가지 시장 지표를 크롤링해보자.개발자 도구 활용법오른쪽 상단 아이콘 > 도구더보기 > 개발자도구왼쪽 상단 아이콘 > 크롤링하고자 하는 데이터에 마우스 커서> 해당 태그 음영처리
14.(EDA강의)Beautiful Soup 기초 2
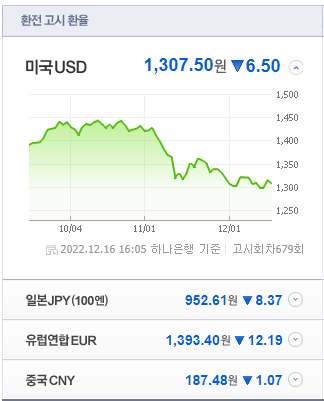
<원본 웹 데이터><결과 데이터>find, find_all과 같은 기능의 메소드인 select_one, select를 활용해서 4개국 환율과 등락, 관련 링크를 크롤링해보자.
15.(EDA강의)위키백과 데이터 스크랩핑
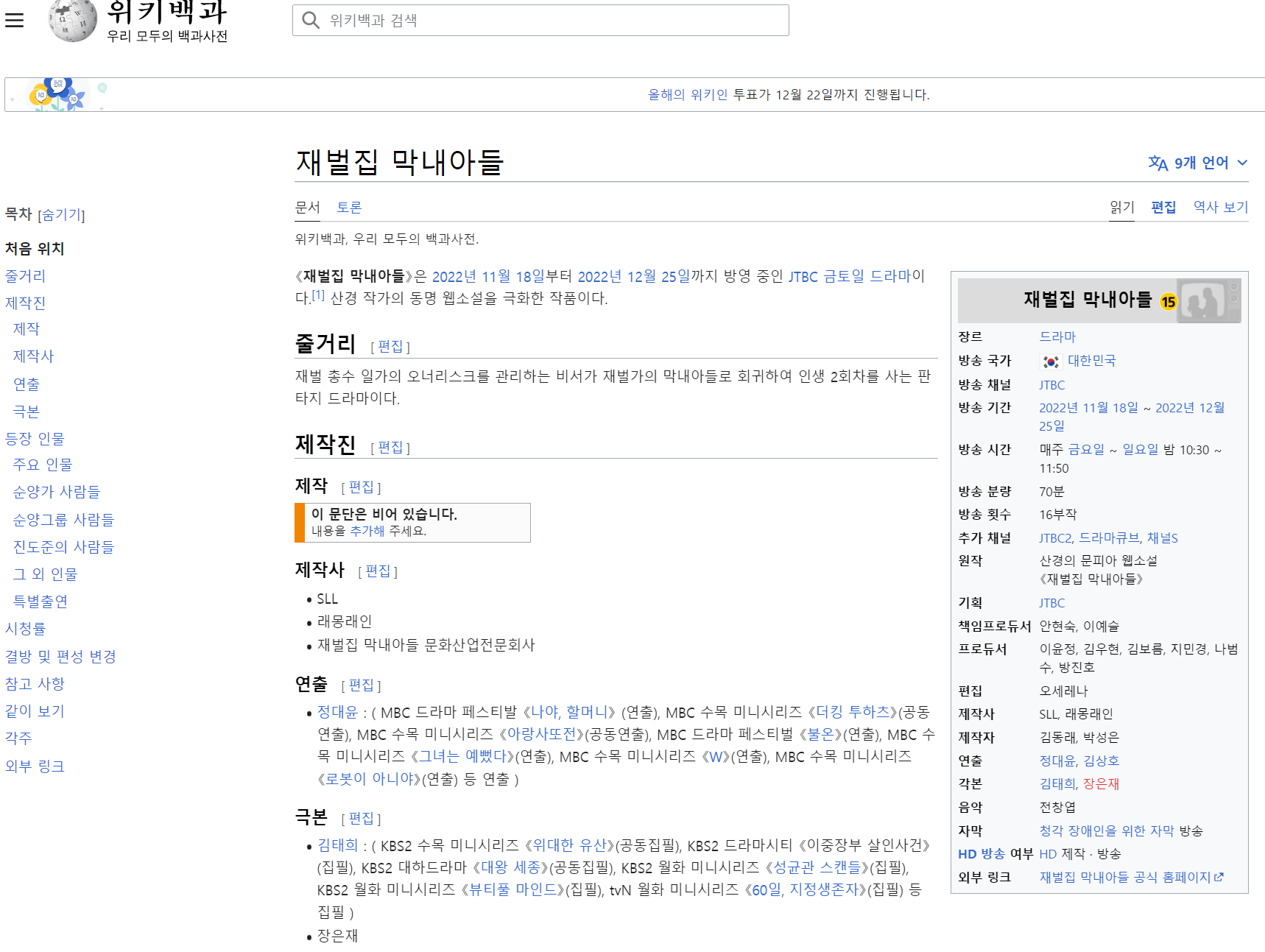
실제 강의 내용의 일부분만 발췌했습니다.<원본데이터><결과데이터>200
16.(EDA강의)시카고 맛집 웹 데이터 스크래핑

<원본데이터>시카고 맛집 50선<결과데이터>메인 페이지에서 각 가게의 정보를 가져온다가게 이름, 대표 메뉴위와 같이 접근을 하면 403error가 뜬다. 서버에서 접근을 거부한 것이다. 이를 해결하려면 header를 지정해주어야 한다. 원래는 하기에 표기된
17.(EDA강의)Selenium 기초
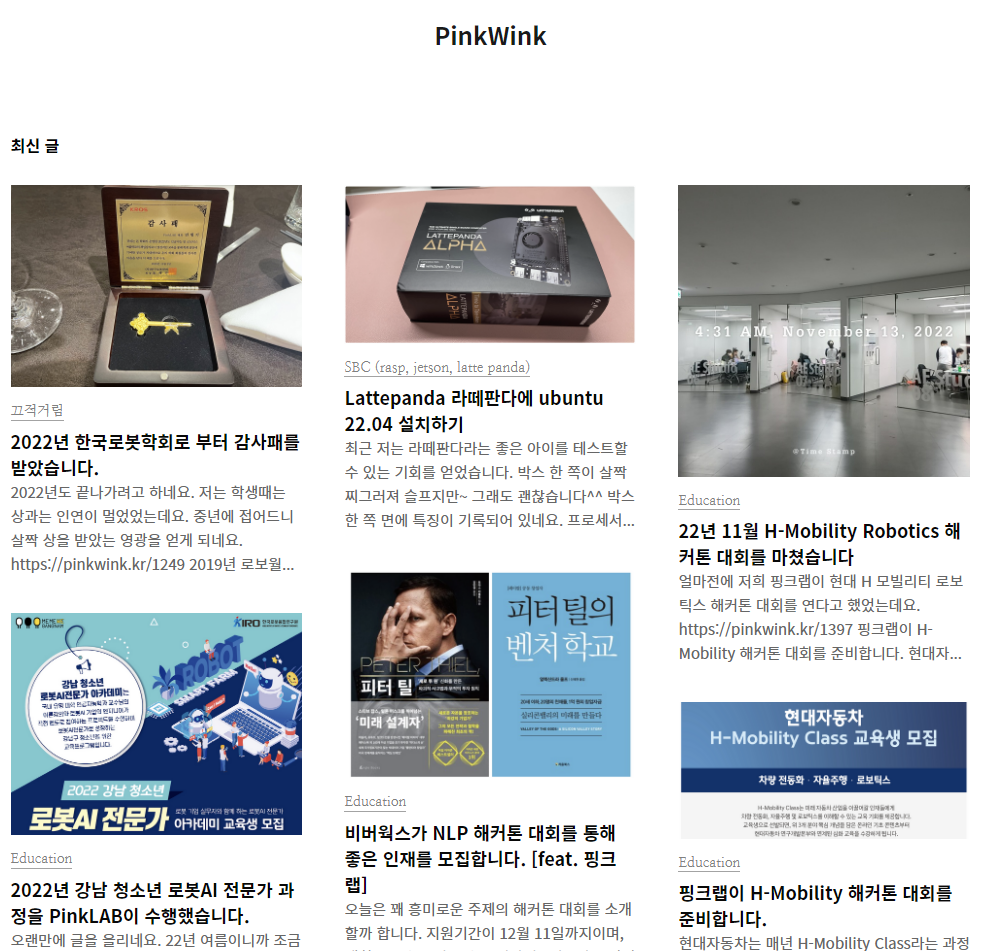
<첫 화면><결과 화면>셀레니움을 활용하여 블로그 특정 태그까지 스크롤을 내려보자.{'width': 1050, 'height': 1000}{'x': 10, 'y': 10}{'height': 1000, 'width': 1050, 'x': 10, 'y': 10}
18.(EDA강의)Selenium 기초 2
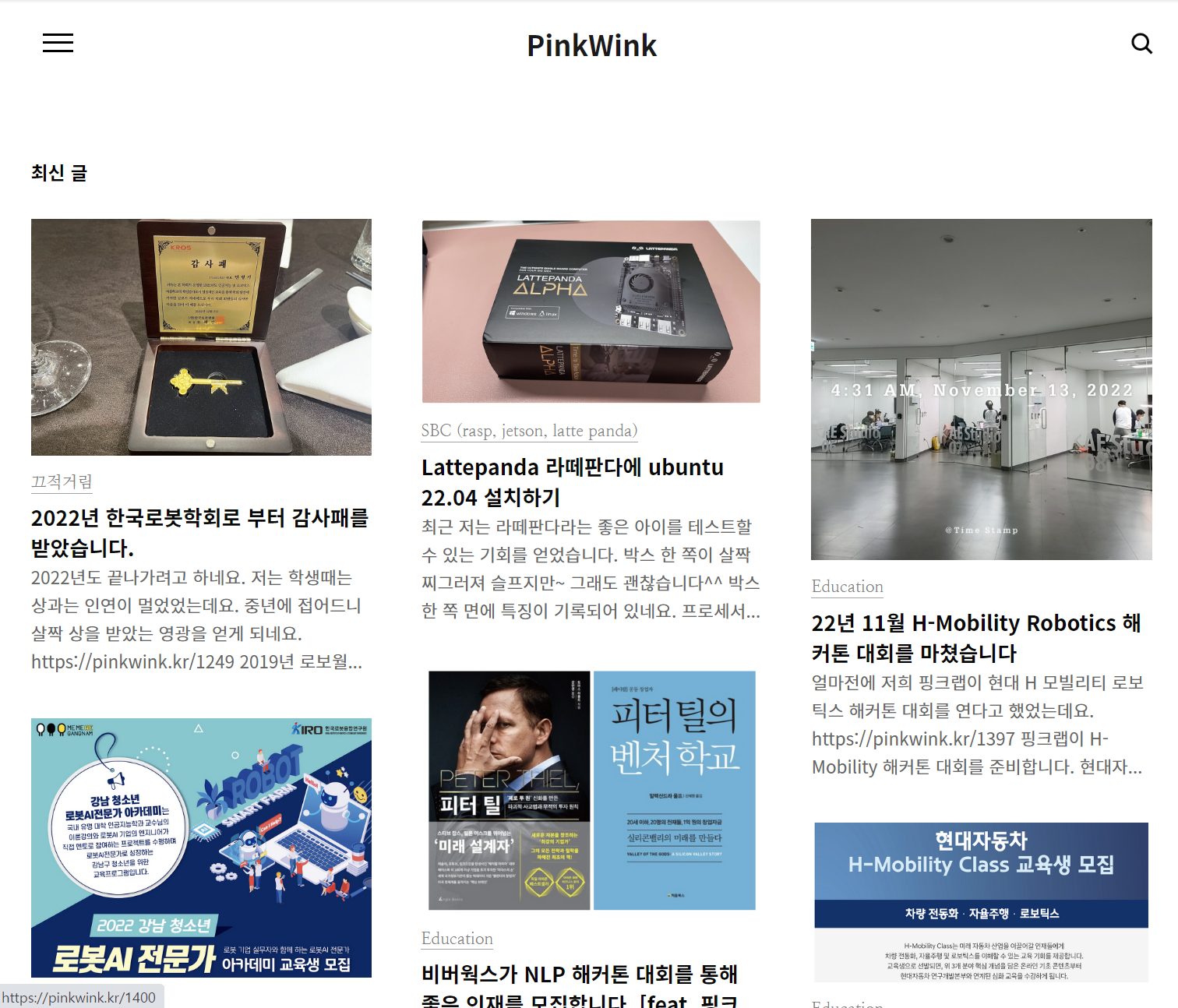
<첫 화면><결과 화면>셀레니움을 활용하여 블로그 검색창에 키워드를 입력하고 검색해보자
19.(EDA강의)유가 분석
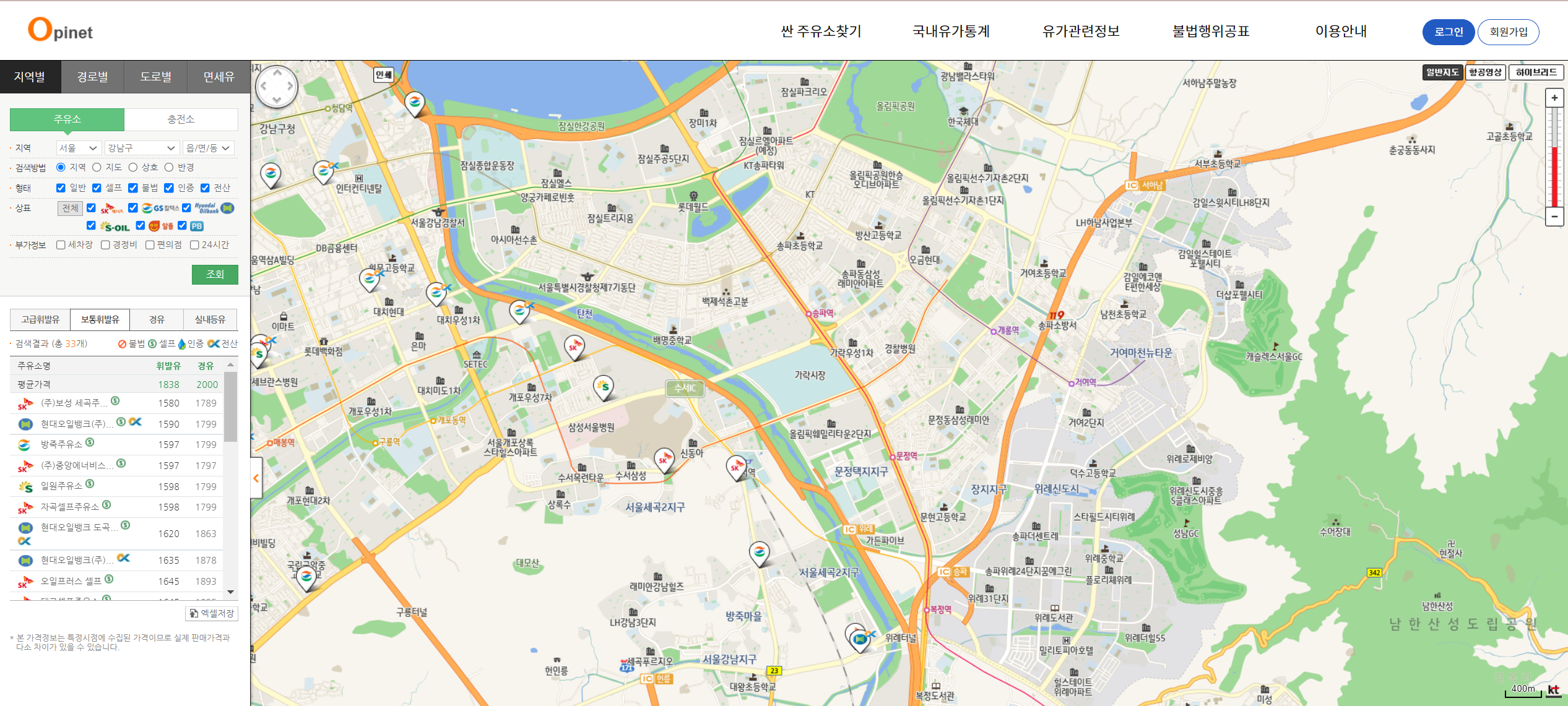
실제 강의 내용의 일부분만 발췌했습니다.<웹데이터><결과데이터>셀프 주유소가 다른 주유소보다 저렴한지 비교해보자'서울특별시', '부산광역시', '대구광역시', '인천광역시', '광주광역시', '대전광역시', '울산광역시', '세종특별자치시', '경기도', '
20.(EDA강의)NAVER API 활용하기
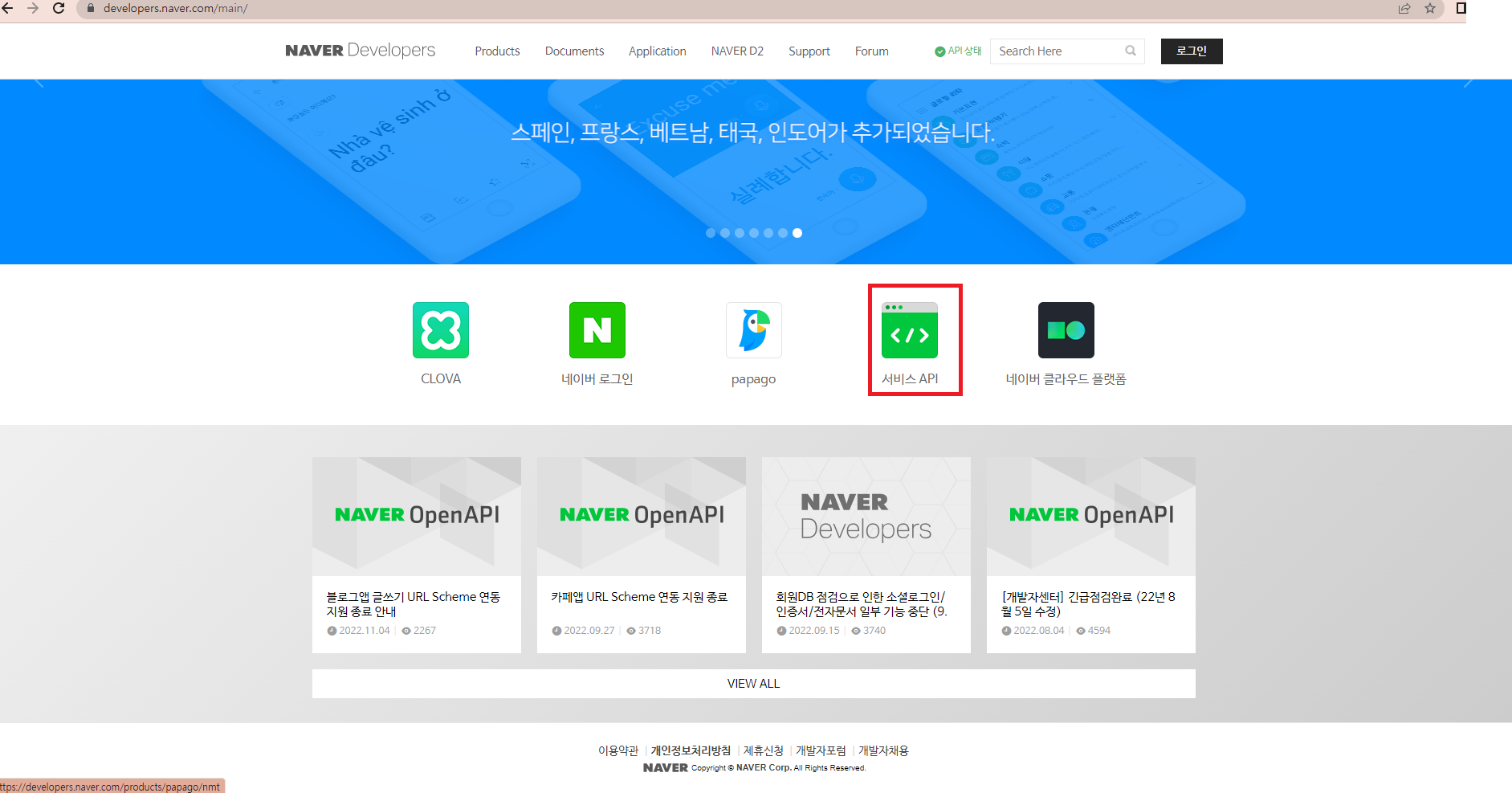
실제 강의 내용의 일부분만 발췌했습니다.네이버 검색 API를 사용해 네이버 포탈 검색 콘텐츠를 읽어오자https://developers.naver.com/main/ 접속서비스 API 클릭 > 오픈 API 이용 신청 > Application 등록사용 API 지정
21.(EDA강의)NAVER API 활용하기 2
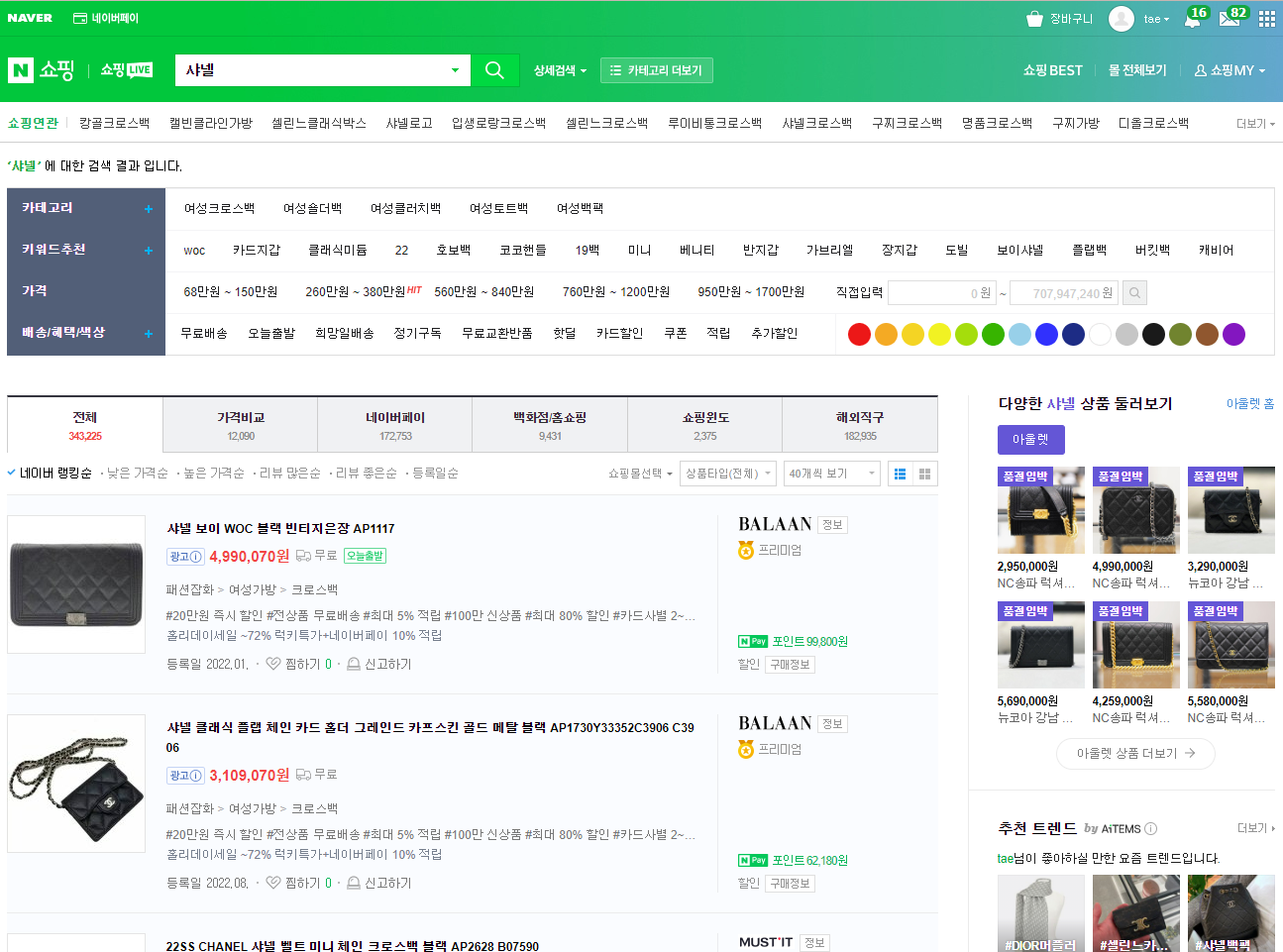
실제 강의 내용의 일부분만 발췌했습니다.<웹 데이터><결과데이터>네이서 쇼핑에 샤넬을 검색했을 때 상위 1000개의 데이터를 분석하여 네이버 자사몰을 제외한 쇼핑몰별 검색 노출 빈도를 조사해보자딕셔너리 형태로 데이터가 담아져 있고, 'items'라는 키워드가
22.(MySQL)Database/USER 관리

Database 관리 mysql -u root -p 로컬
23.(MySQL)Table 관리

database_name이라는 명의 데이터 베이스를 생성하는데 character set은 utf8mb4로 생성각 열은 column_name이라는 이름을 갖고, column_name의 데이터타입은 data_type인 table_name이라는 이름의 테이블을 형성테이블 명
24.(MySQL) 삽입, 조회, 조건, 갱신, 삭제

각 컬럼(id, name, age, sex)에 순차적으로 values 뒤에 기입한 데이터값(1, '이효리', 43, 'F')을 입력해서 person이라는 테이블의 한 행으로 삽입다른 방법으로 data를 insert 할 수 있다.각 컬럽 명 언급을 생략하더라도 모든 값을
25.(MySQL) order by, operator

select 뒤에 기재한 컬럼은 order by 절에 기재한 컬럼을 포함해야 한다.order by 절에 기재한 컬럼 기준으로 순서를 정렬해서 보여준다.컬럼명 뒤에 ASC : 오름차순으로 정렬. 디폴트 값으로 생략 가능.컬럼명 뒤에 DESC : 내림차순으로 정렬ex) s
26.(MySQL) UNION/JOIN

여러 개의 SQL 문을 합쳐서 하나의 SQL 문으로 만들어주는 방법컬럼의 갯수가 같아야 한다union: 중복된 값을 제거하여 알려준다.union all: 중복된 값도 포함하여 모두 보여준다.celeb테이블에서 성별이 여자인 행의 이름, 성별, 소속사를 조회한 데이터와
27.(MySQL)concat/alias/distinct/limit

문자열을 연결하여 호출한다.concat teststring1과 column의 value들을 연결해서 조회데이터 조회시 컬럼명과 테이블명을 다른 이름으로 지정한다.검색한 결과의 중복 제거검색 결과를 정렬된 순으로 주어진 숫자만큼만 조회celeb 테이블에서 남자 연예인 중
28.(MySQL)AWS RDS
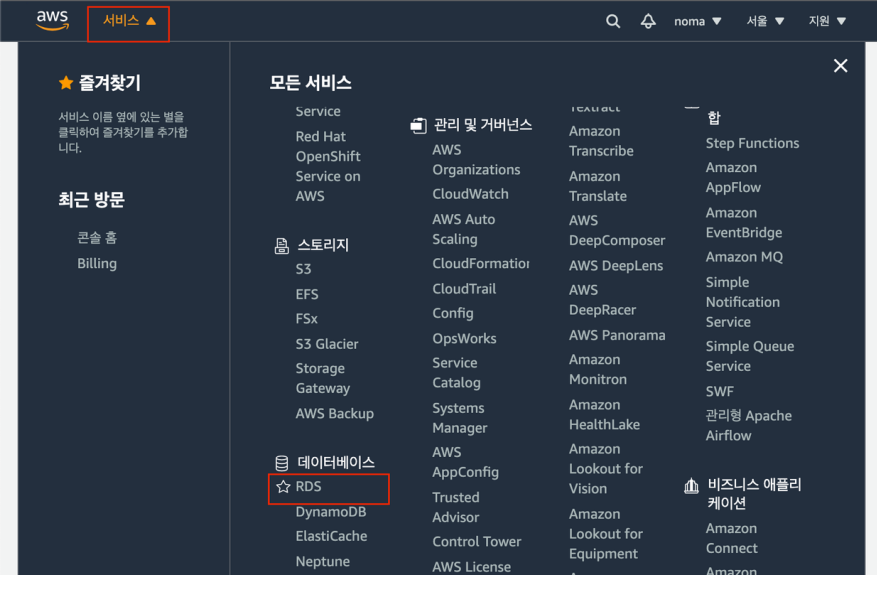
회원가입 참고아래 주소 이동https://portal.aws.amazon.com/billing/signup이메일 주소, 암호, 계정이름, 인적사항 기입카드 정보 기입 (프리티어를 사용한다고 해도 필요한 단계)문자 인증버전 선택MySQL RDS 생성 및 데이터베
29.(MySQL) SQL File

sql 쿼리를 모아 놓은 파일. 확장자: .sql해당 파일을 불러와서 쿼리를 한꺼번에 실행시킬 수 있다.sql 파일로 database를 백업할 수 있다.데이터베이스를 백업한 SQL 파일을 실행하여 그 시점으로 복구할 수 있다.Table 단위로도 백업할 수 있다.데이터를
30.(MySQL)Python with MySQL

데이터베이스 지정은 생략할 수 있다.로컬 접수일 경우 포트도 생략할 수 있다.SQL File내에 Query가 여러개 존재하는 경우 execute 파라미터 중 multi=True 설정 추가읽어오는 양이 많은 경우 cursor 생성시 buffered = True로 설정
31.(MySQL)PK / FK

하나의 컬럼만 지정할 수도 있고, 여러개의 컬럼을 지정할 수도 있다.primary key로 지정하는 칼럼은 not null이어야 하고 유일무이해야한다.constraint는 생략할 수 있다.한 테이블을 다른 테이블과 연결해주는 역할참조되는 테이블의 항목은 그 테이블의 기
32.(MySQL)Aggregate Function

police_station테이블의 모든 행은 총 몇 개인지 반환crime_status에서 발생한 사건 수의 총합을 반환중부경찰서에서 검거된 총 범죄건수 반환평균 폭력 검거 건수 반환경찰서별 강도 발생 건수가 가장 적은 경우의 강도 발생 건수 살인이 가장 많이 검거 된
33.(MySQL)서브쿼리

select 절에 사용서울은평경찰서의 강도 검거 건수와 서울시 경찰서 전체의 평균 강도 검거 건수를 조회from 절에 사용하는 서브쿼리메인쿼리에서는 인라인뷰에서 조회한 column만 사용가능경찰서 별로 가장 많이 발생한 범죄 건수와 범죄 유형을 조회하나의 열을 검색하는
34.(GIT)Local Repository 생성

Local Repository를 생성해보자폴더에서 Git을 초기화하는 명령어해당 폴더를 Git이 관리하기 시작숨김 폴더 포함, 현 위치 내 모든 폴더 표기현위치에 test.txt 파일명의 빈 파일 생성git에 존재하는 파일 확인working directory: 작업공간
35.(GIT)Remote Repository 생성

Remote Repository를 생성하고 Local Repository와 연동해보자https://github.com/ 접속, 로그인create repository 버튼 클릭repository name은 local repository 명과 동일하게 설정오른쪽
36.(GIT)Push / Pull

local repository(head)에 반영된 변경내용을 remote repository에도 반영git push origin <branchname>Remote Repository 페이지에서 새로고침하면 Push된 파일이 보임Remote Repository의 내
37.(GIT)Default Branch / Remote Repository 복제하기

github 로그인 상태 > new이름설정/private/add a readme file/ add gitignore(python) > create repository만든 repository 들어가면 master가 아니라 main으로 이름이 지정되어 있다.변경할 이름은
38.(GIT)Branch

로컬 branch를 조회remote branch를 조회local과 remote의 branch를 모두 조회로컬에 branch_name 이라는 이름의 branch를 현 위치에서 생성로컬에 branch_name이라는 이름의 branch로 이동로컬에 branch_name이라는
39.(GIT)Git Graph on VSCode

Git Graph를 VSCode에서 설치해보자Git Graph는 각 branch의 파생 정보, merge정보 등을 그래프로 보여준다.Git Extension에서 'git graph'검색하여 설치Git Source에서 그래프 아이콘 클릭
40.(GIT)Log / Diff

git bash에 git config --global core.editor "code --wait" 입력vim이 기본설정VSCode로 설정 변경 권장\--wait 옵션(VSCode창이 닫히기 전에 터미널에서 작업 불가) 추가 권장git bash에 git config -
41.(GIT)Merge / Conflict

git bash에 git config --global -e 입력 > VSCode창 openVSCode에 하기 내용 입력현재 위치한 Branch에 다른 Branch 병합main branch에 "my name is noma" 내용의 test.txt 파일 생성, add, c
42.(GIT)Tag

git tag tag_name 현재 버전에 tag 달기 git tag tagname commithash 특정 버전에 tag 달기 git push origin tag_name tag를 remote repository에 push 데이터 전처리

Tableau로 데이터를 불러오고 데이터 전처리를 해보자.
44.(Tableau)인터페이스 / 데이터 필드의 유형

데이터 필드의 유형에 대해서 알아봅니다.
45.(Tableau)기본 차트 만들기

태블로를 이용하여 기본 차트를 만들어 보자.
46.(Tableau)대시보드

태블로로 간단한 대시보드를 만들어보자.
47.(Tableau)이중축

이중축을 활용하여 다양한 차트를 그려보자
48.(Tableau)동작 기능

대시보드에서 동작 기능을 구현해보자
49.(Tableau)그룹 / 집합 / 결합된 집합

태블로 내 그룹, 집합, 결합된 집합에 대하여 알아보자.
50.(Tableau)계층 / 드릴다운

태블로에서 계층과 드릴다운에 대해서 알아보자.
51.(Tableau)맵 차트

태블로를 이용하여 맵차트를 그려보자
52.(Tableau)워드 클라우드 / 달력형 히트맵

태블로로 워드 클라우드와 달력형 히트맵을 만들어보자.
53.(Tableau)대시보드 2

필터, 하이라이트를 응용하여 대시보드를 만들어 보자.
54.(Tableau)매개 변수 활용

매개변수를 활용하여 대시보드 동작 기능을 응용해보자.
55.(Tableau)집합값 변경

집합값 변경을 이용해 동적 기능을 구현해보자.
56.(Tableau)URL 연동

대시보드에 URL을 연동하여 동적 기능을 추가해보자.
57.(Tableau)퀵 테이블 계산_1

퀵 테이블 계산을 이용하여 누계, 차이, 구성비, 순위를 표기해보자.
58.(Tableau)퀵 테이블 계산_2

퀵 테이블 계산을 활용하여 비율차이, YoY 성장률, 백분위수, 이동평균을 표기해보자.
59.(ML)붓꽃 품종 분류하기

명시적인 프로그램에 의해서가 아니라, 주어진 데이터를 통해 규칙을 찾는 것붓꽃의 3가지 품종 versicolor, virginica, setosa를 꽃잎(petal), 꽃받침(sepal)의 길이, 너비로 구분해보자붓꽃은 프랑스 국화로 그리스 신화의 무지개의 여신인 Ir
60.(ML)타이타닉 생존자 예측

타이타닉 생존자를 예측해보자
61.(ML)Scaler

Scaler에 대하여 알아 보자.
62.(ML)Wine 분류기

DecisionTreeClassifier를 활용하여 와인을 분류해보자
63.(ML)Pipeline

파이프라인을 활용하여 전처리부터 label 예측까지 간소하게 코딩해보자
64.(ML)GridSearchCV

GridSearchCV에 대하여 알아보자.
65.(ML)모델 평가의 개념

모델 평가 지표에 대하여 알아보자
66.(ML)ROC와 AUC

ROC와 AUC에 대하여 알아보자.
67.(ML)Basic of Regression

회귀에 대하여 알아보자.
68.(ML)Cost Function

비용함수와 경사하강법에 대하여 알아보자.