- 실제 강의 내용의 일부분만 발췌했습니다.
<웹데이터>
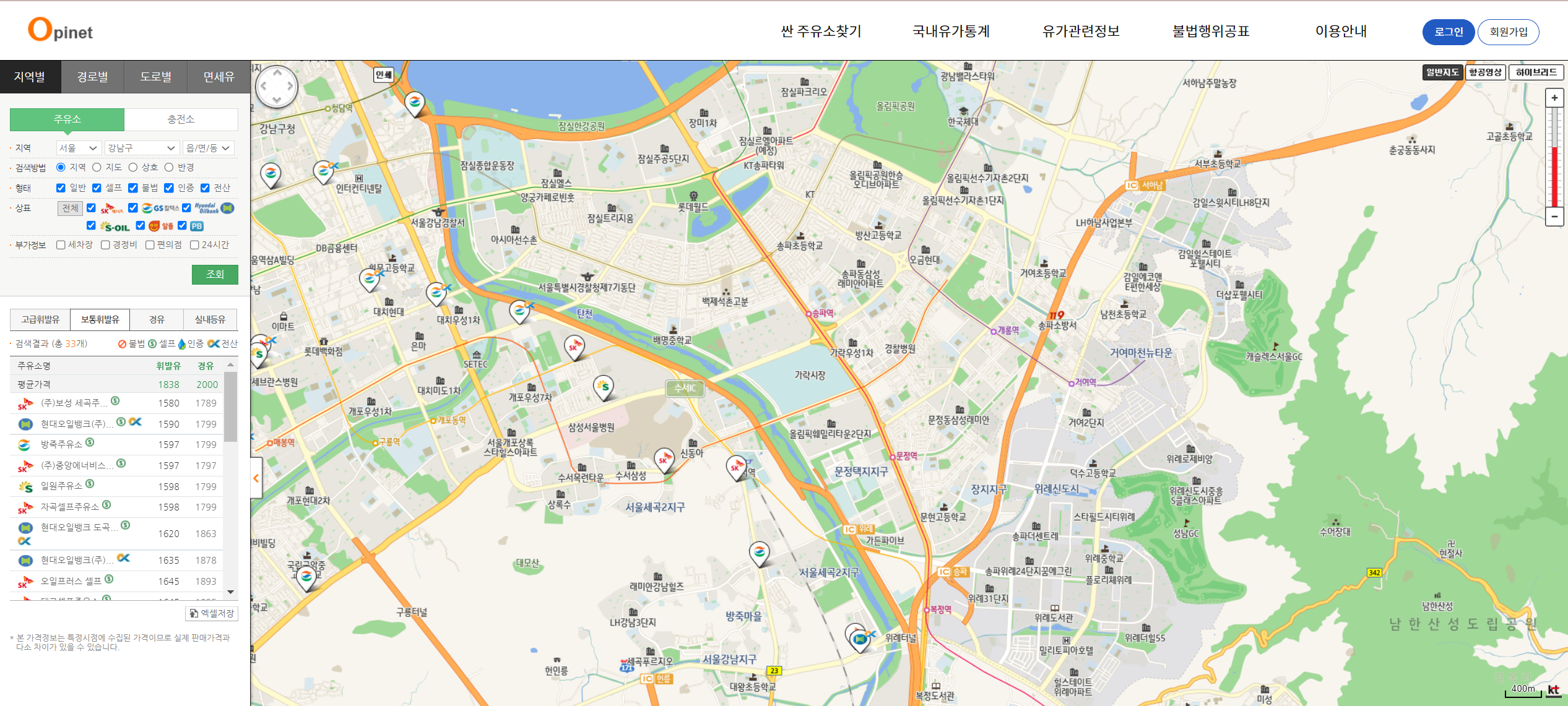
<결과데이터>
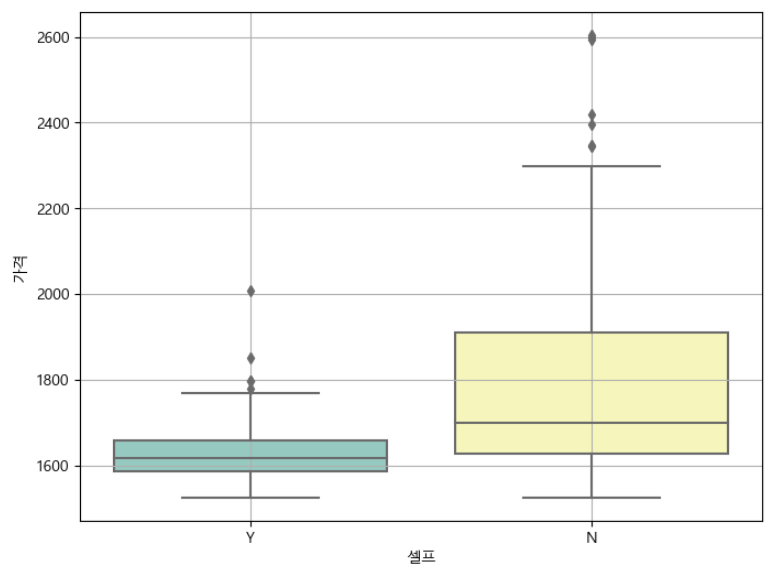
셀프 주유소가 다른 주유소보다 저렴한지 비교해보자
셀레니움으로 구별 유가 엑셀데이터 모으기
# 오피넷 사이트 열기
from selenium import webdriver
import time
url = "https://www.opinet.co.kr/searRgSelect.do"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(url)
# 시간간격을 두고 셀레니움 기능이 웹속도를 추월하는 현상 방지
time.sleep(3)
# 팝업창 화면 전환 후 닫아주기
driver.switch_to_window(driver.window_handles[-1])
driver.close()
time.sleep(3)
# 접근 페이지 다시 요청
driver.switch_to_window(driver.window_handles[-1])
driver.get(url)
# 시도명 긁어오기
sido_list_raw = driver.find_element_by_id("SIDO_NM0")
sido_list = sido_list_raw.find_elements_by_tag_name("option")
sido_names = []
for option in sido_list:
sido_names.append(option.get_attribute("value"))
sido_names
sido_names = sido_names[1:]
print(sido_names)['서울특별시', '부산광역시', '대구광역시', '인천광역시', '광주광역시', '대전광역시', '울산광역시', '세종특별자치시', '경기도', '강원도', '충청북도', '충청남도', '전라북도', '전라남도', '경상북도', '경상남도', '제주특별자치도']
# 서울특별시 값 검색창에 보내기
sido_list_raw.send_keys(sido_names[0])
# 구 이름 긁어오기
gu_list_raw = driver.find_element_by_id("SIGUNGU_NM0") #부모태그
gu_list= gu_list_raw.find_elements_by_tag_name("option") # 자식태그
gu_names = [option.get_attribute("value") for option in gu_list]
gu_names = gu_names[1:]
gu_names[:5], len(gu_names)(['강남구', '강동구', '강북구', '강서구', '관악구'], 25)
# 강남구 값 검색창에 보내기
gu_list_raw.send_keys(gu_names[0])
#엑셀저장
from tqdm import tqdm_notebook
for gu in tqdm_notebook(gu_names):
element = driver.find_element_by_id("SIGUNGU_NM0")
element.send_keys(gu)
time.sleep(3)
element_get_excel = driver.find_element_by_css_selector("#glopopd_excel").click()
time.sleep(3)데이터 정리하기
import pandas as pd
from glob import glob
# 파일 목록 한 번에 가져오기
glob("../data/oil_station_price/지역_*.xls")
# 파일명 저장
stations_files = glob("../data/oil_station_price/지역_*.xls")
# 데이터프레임을 item으로 하는 리스트 만들기
tmp_raw =[]
for file_name in stations_files:
tmp = pd.read_excel(file_name, header = 2)
tmp_raw.append(tmp)
# 각 item을 연결해서 하나의 데이터프레임 만들기
stations_raw = pd.concat(tmp_raw)
stations_raw
stations_raw.info()
# 콜룸명 바꾼 새로운 데이터프레임 만들기
stations = pd.DataFrame({
"상호": stations_raw["상호"],
"주소": stations_raw["주소"],
"가격": stations_raw["휘발유"],
"셀프": stations_raw["셀프여부"],
"상표": stations_raw["상표"],
})
# 구 콜룸 생성
stations["구"] = [eachAddress.split()[1] for eachAddress in stations["주소"]]
# 주가 분석을 위해 가격 데이터타입을 object에서 float으로 변경
stations["가격"] = stations["가격"].astype("float")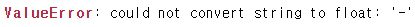
- '-'가 채워져 있는 데이터가 있어 데이터타입 변환이 안된다.
- 제대로 된 정보를 채워줄 수도 있다.
- 금번 포스팅에서는 이 데이터를 쓰지 않는 방향으로 정제한다.
stations = stations[stations["가격"] != '-']
stations["가격"]= stations["가격"].astype("float")
stations.info()
stations.reset_index(inplace= True)
del stations["index"]
stations.head()
주유 가격 정보 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
get_ipython().run_line_magic("matplotlib","inline")
path = "C:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname = path).get_name()
rc("font", family = font_name)
stations.boxplot(column = "가격", by = "셀프", figsize = (8, 6));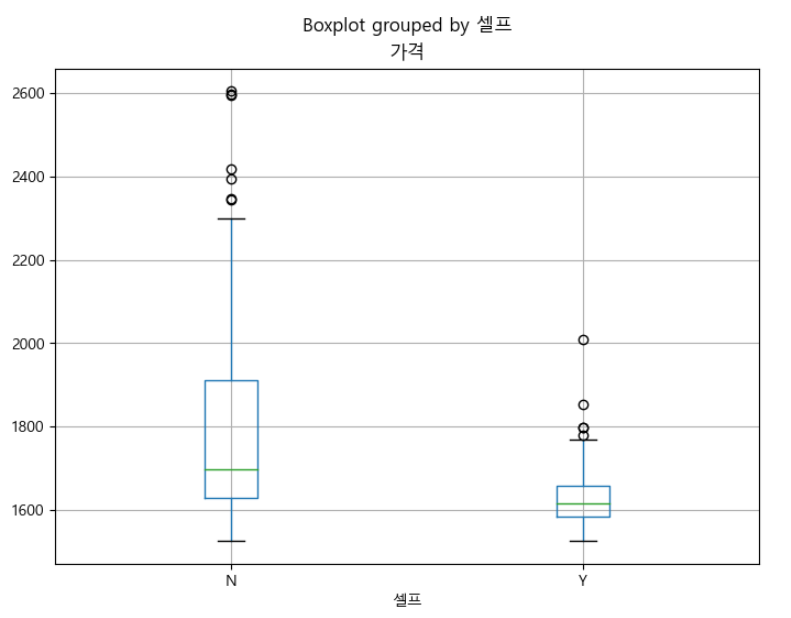
plt.figure(figsize = (8, 6))
sns.boxplot(x="셀프", y = "가격", data= stations, palette ="Set3")
plt.grid(True)
plt.show()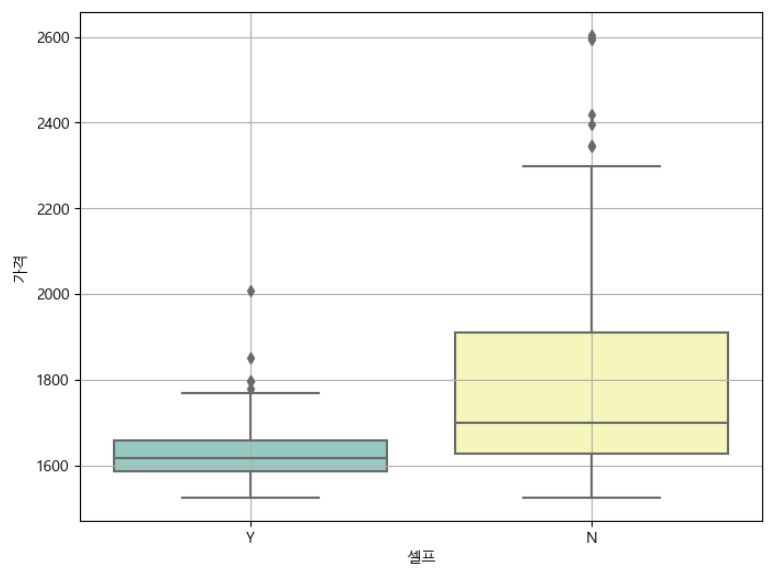

쉽고 유익하게 널리널리