데이터, 라이브러리 로드
reuters.load_data() 에서 num_words 매개변수는 데이터에서 등장 빈도 순서로 상위 몇개 까지 사용할 거인지 지정
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import reuters
(X_train, y_train), (X_test, y_test)=reuters.load_data(num_words=None, test_split=0.2)
print('훈련용 뉴스 기사 : {}'.format(len(X_train)))
print('테스트용 뉴스 기사 : {}'.format(len(X_test)))
num_classes = len(set(y_train))
print('카테고리 : {}'.format(num_classes))
훈련용 뉴스 기사 : 8982
테스트용 뉴스 기사 : 2246
카테고리 : 46이렇게 불러온 로이터 뉴스 데이터는 토큰화와 정수 인코딩까지 끝난 상태
뉴스 기사의 최대 길이, 평균 길이 확인, 뉴스 길이 분포 확인
print('뉴스 기사의 최대 길이 :{}'.format(max(len(sample) for sample in X_train)))
print('뉴스 기사의 평균 길이 :{}'.format(sum(map(len, X_train))/len(X_train)))
plt.hist([len(sample) for sample in X_train], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()
뉴스 기사의 최대 길이 : 2376
뉴스 기사의 평균 길이 : 145.5398574927633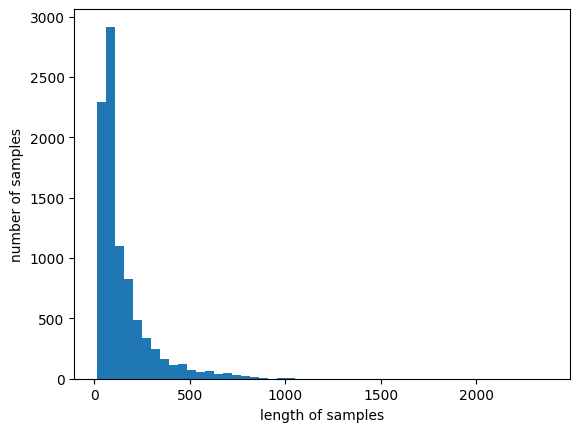
각 레이블에 대한 개수 확인
unique_elements, counts_elements=np.unique(y_train, return_counts=True)
print(np.asarray((unique_elements, counts_elements)))word_to_index에서 정수와 단어를 반대로 저장한 index_to_word 생성
데이터의 규칙에 의해 정수에 3을 더해야 제대로 일치한다
index_to_word = {}
for key, value in word_to_index.items():
index_to_word[value+3] = keyLSTM모델 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.models import load_model학습에서는 등장 빈도 상위 1000개 단어만 사용, 뉴스의 길이는 100으로 패딩
vocab_size = 1000
max_len = 100
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=vocab_size, test_split=0.2)
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)훈련, 테스트의 레이블에 원-핫 인코딩
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)임베딩 벡터 차원: 128, 은닉 상태 크기: 128
embedding_dim = 128
hidden_units = 128
num_classes = 46다 대 일 구조의 LSTM
마지막 시점에서 46개의 선택지 중 1개 선택(다중 분류) -> 출력층 소프트맥스
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(hidden_units))
model.add(Dense(num_classes, activation='softmax'))callback 정의
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('best_model.keras', monitor='val_acc', mode='max', verbose=1, save_best_only=True)모델 컴파일 및 학습
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
history = model.fit(X_train, y_train, batch_size=128, epochs=30, callbacks=[es, mc], validation_data=(X_test, y_test))저장된 모델 로드, 테스트 세트 성능 평가
loaded_model=load_model('best_model.keras')
print(loaded_model.evaluate(X_test, y_test))테스트 정확도: 0.7221
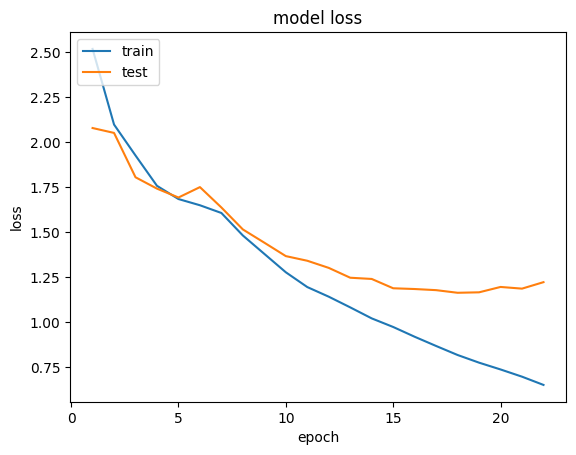
epoch에 따른 훈련, 테스트 데의터의 손실 확인
epochs = range(1, len(history.history['acc']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()