크롤링
네이버 페이 부동산을 크롤링하여
100페이지가 넘지 않으면 에러가 날 수 있기 때문에 try except 사용했다
article_list = []
for i in tqdm(range(1, 101)):
try:
url = f'https://m.land.naver.com/cluster/ajax/articleList?itemId=&mapKey=&lgeo=&showR0=&rletTpCd=OPST%3AVL%3AOR&tradTpCd=B2&z=12&lat=37.481021&lon=126.951601&btm=37.3398975&lft=126.6762562&top=37.6218785&rgt=127.2269458&totCnt=8360&cortarNo=1162000000&sort=rank&page={i}'
user_agent = generate_user_agent()
headers = {'User-Agent':user_agent}
res = requests.get(url, headers=headers)
time.sleep(1) # 부하 방지를 위해 1초의 대기 시간 가진다
article_json = res.json()
article_body = article_json['body']
article_list.append(article_body)
except:
break
article_list1 = [j for i in article_list for j in i]
data = pd.DataFrame(article_list1)필요한 컬럼만 사용하고 컬럼명 지정 후 엑셀 파일로 저장
data = data[['atclNo', 'rletTpNm', 'flrInfo', 'rentPrc', 'hanPrc', 'spc1', 'spc2', 'direction', 'atclCfmYmd', 'repImgUrl', 'lat', 'lng', 'atclFetrDesc', 'tagList']]
data.columns = ['물건번호', '구분', '층수(물건층/전체층)', '월세', '보증금', '계약면적(m2)', '전용면적(m2)', '방향', '확인일자', '이미지', '위도', '경도', '설명', '태그']
data
data.to_excel('data.xlsx')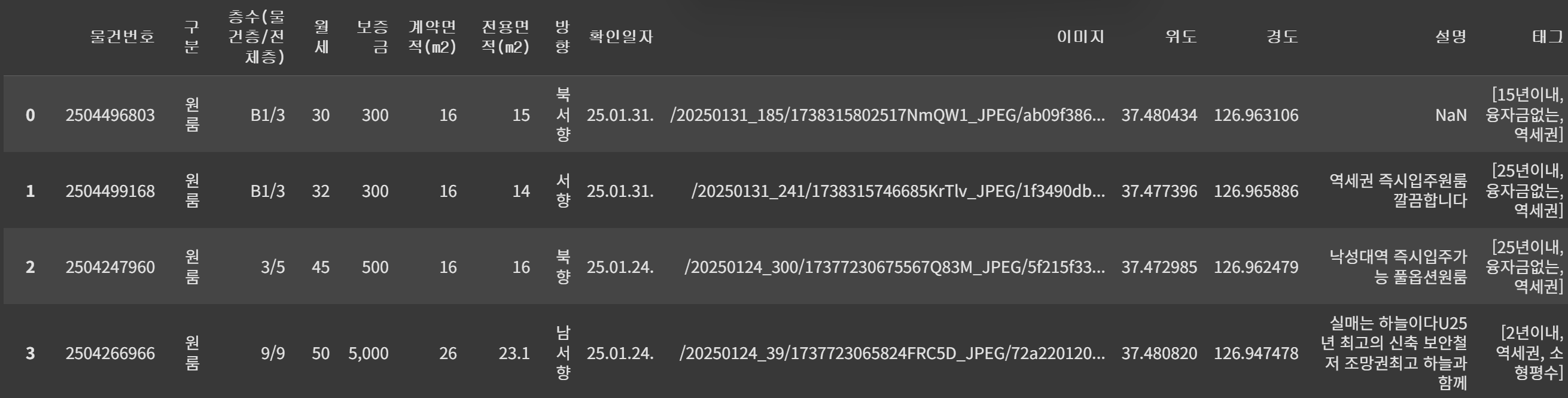
전처리
중복된 인덱스 컬럼 삭제
data.drop('Unnamed: 0', axis=1, inplace=True)월세가 0원인 경우 삭제
data = data.query('월세 > 0')보증금 숫자로 변환
data = data.query('~보증금.str.contains("억")')
data.보증금 = data.보증금.str.replace(',', '').astype(int)새로운 컬럼 생성
물건층, 전체층을 분리한 후 비선호층에 대한 유무 확인하는 컬럼 생성
# 물건층, 전체층 분리
data[['물건층', '전체층']] = data['층수(물건층/전체층)'].str.split('/', expand=True)
# 비선호층을 구분하는 함수
from re import T
def floor_info(target, total):
try:
if target in ['B1', 'B2']:
return 'y'
elif int(target) == 1 or int(target)/int(total) == 1:
return 'y'
else:
return 'n'
except ValueError:
return 'n'
# 비선호층여부 컬럼 생성
data['비선호층여부'] = data.apply(lambda x: floor_info(x['물건층'], x['전체층']), axis=1)
데이터 필터링
내가 원하는 조건
1. 보증금 3,000만원 이하
2. 지하, 반지하, 꼭대기층 x
3. 북향 x
data_filtered = data.query('300<= 보증금 <= 3000 and 비선호층여부 == "n" and 전체층 !="1" and ~방향.str.contains("북")')태그 분리
정규표현식을 이용해 태그 컬럼을 4개의 컬럼으로 분리
data_filtered[['tag1', 'tag2', 'tag3', 'tag4']] = data_filtered['태그'].str.replace(r"\'|\[|\]", "", regex=True).str.split(', ', expand=True)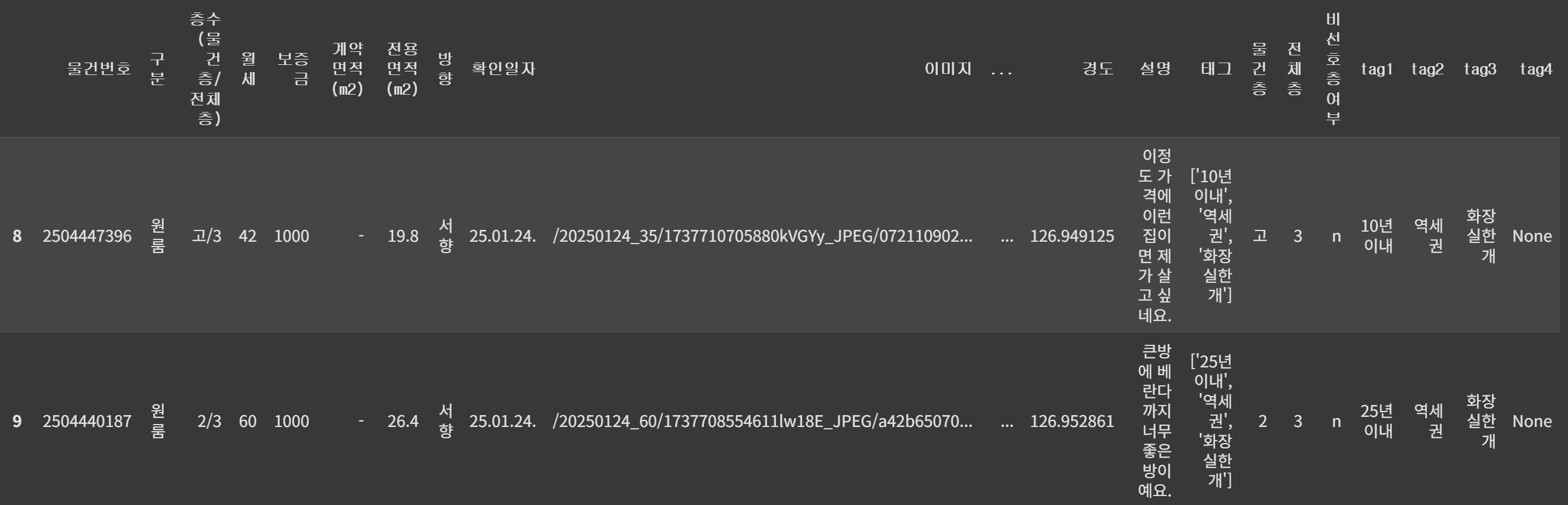
연식 컬럼 추가
# 연식 정보가 있는 데이터만 필터링
data_filtered = data_filtered.query('tag1.str.contains("년")')
data_filtered['연식'] = [int(i[0]) for i in data_filtered['tag1'].str.split('년')]필요한 컬럼만
data_filtered = data_filtered[['물건번호','월세','보증금','전용면적(m2)','방향','위도','경도','물건층','전체층','연식']]
data_filtered.head()역까지의 거리 추가
coordinate = pd.read_csv('서울시 역사마스터 정보.csv', encoding='cp949')
coordinate = coordinate.query('호선 == "2호선"')
station_list = ['신대방', '신림', '봉천', '서울대입구(관악구청)', '낙성대', '사당']
coordinate.query('역사명 in @station_list')역까지의 거리를 구하는 함수(haversine을 이용해 거리를 구했다)
def distance(station_name, lat, long):
station_lat = coordinate.query(f'역사명 == "{station_name}"')['위도'].values[0]
station_long = coordinate.query(f'역사명 == "{station_name}"')['경도'].values[0]
distance = haversine((station_lat, station_long), (lat, long), unit='m')
return distance각 지하철 역별로 자취방과의 직선거리를 구해 지하철역 이름의 컬럼에 저장
for s in station_list:
data_filtered[s] = data_filtered.apply(lambda x: distance(s, x['위도'], x['경도']), axis=1) 모든 지하철역에 대한 거리를 구하는 것은 비효율적이다
그래서 역까지 거리가 가장 가까운 거리만 데이터에 추가
data_filtered['역까지최소거리'] = data_filtered.apply(lambda x:min([x['신대방'], x['신림'], x['봉천'], x['서울대입구(관악구청)'], x['낙성대'], x['사당']]), axis=1)
data_filtered.head()
역까지 최소거리를 구했으니 지하철역 컬럼은 삭제해도 된다
data_filtered.drop(station_list, axis=1, inplace=True)EDA
각 항목의 박스플롯 확인
for x in ['월세', '보증금', '전용면적(m2)', '연식', '역까지최소거리']:
fig = px.box(data_frame = data_filtered, x=x, width=700, height=400)
fig.show()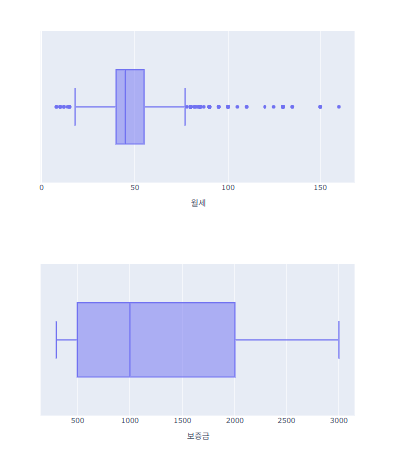
원하는 조건
1. 월세는 저렴할수록 good
2. 전용면적이 클수록 good
3. 연식이 오래되지 않으면
4. 지하철 역에 가까울 수록pandas의 qcut을 이용해 등급을 매긴다
data_filtered['월세_등급'] = pd.qcut(data_filtered['월세'], 5, labels=[1, 2, 3, 4, 5])
data_filtered['전용면적_등급'] = pd.qcut(data_filtered['전용면적(m2)'], 5, labels=[1, 2, 3, 4, 5])
data_filtered['연식_등급'] = pd.qcut(data_filtered['연식'].rank(method='first'), 5, labels=[1, 2, 3, 4, 5]) # rank(method='first') 한 이유는 중복이 많기 때문에 임의로 정해라라고 설정한 것
data_filtered['역까지최소거리_등급'] = pd.qcut(data_filtered['역까지최소거리'], 5, labels=[1, 2, 3, 4, 5])
원하는 조건을 입력해 데이터 필터링
data_filtered_choice = data_filtered.query('월세_등급 < 3 and 전용면적_등급 < 3 and 연식_등급 <= 3 and 역까지최소거리_등급 <= 3')최종 시각화
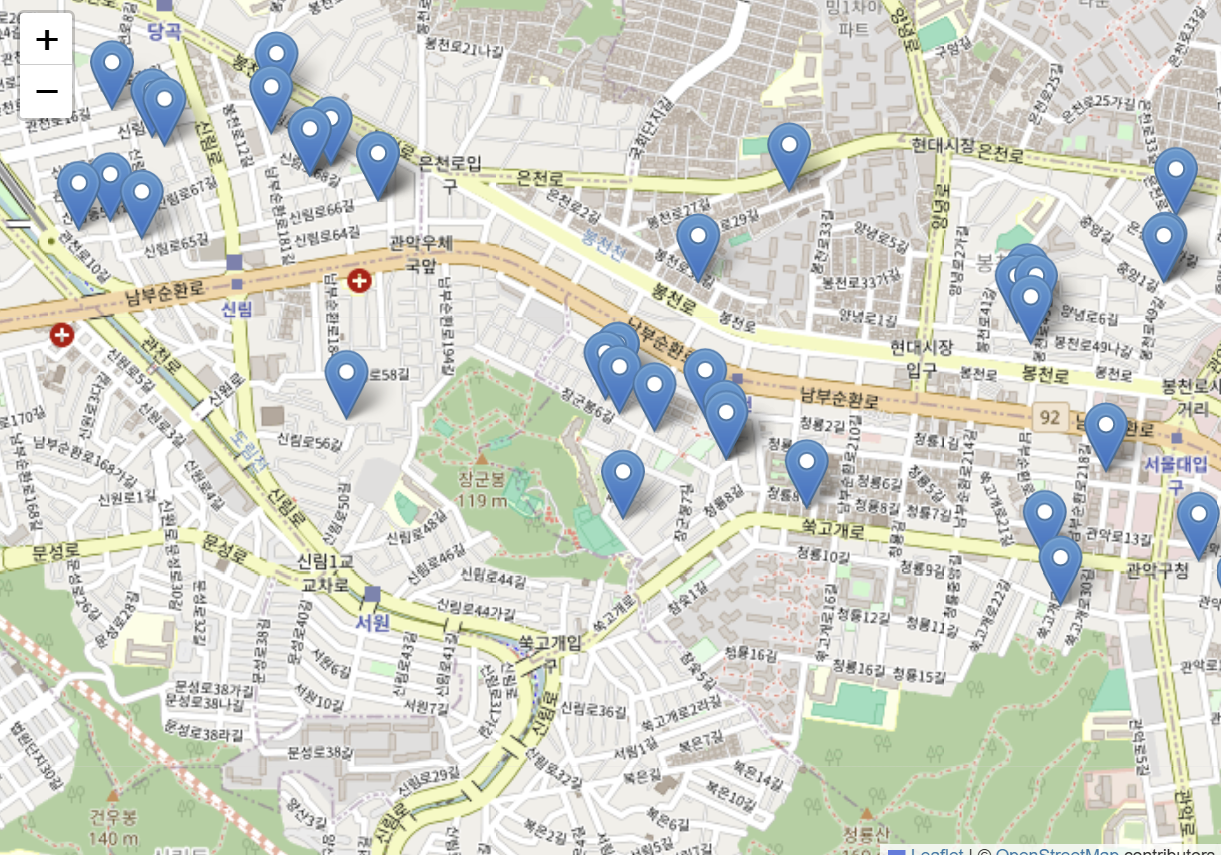
folium을 이용해 지도에 시각화
마커를 클릭하면 링크를 확인할 수 있다
f = folium.Figure(width=700, height=500)
m = folium.Map(location=[37.486313, 126.935378], zoom_start=14).add_to(f)
for idx in data_filtered_choice.index:
lat = data_filtered_choice.loc[idx, '위도']
long = data_filtered_choice.loc[idx, '경도']
num = data_filtered_choice.loc[idx, '물건번호']
folium.Marker([lat, long]
, popup=f"<a href=https://m.land.naver.com/article/info/{num}>링크</a>"
).add_to(m)
m