교통 데이터를 활용해 folium으로 데이터 시각화 수행
데이터 구조
2018년 이후 데이터, 2호선, 승차 인원에 관해 분석을 진행하기 위해 전처리 필요
전처리
연도, 월 컬럼 추가
data['연도'] = pd.to_datetime(data['사용월'], format='%Y%m').dt.year
data['월'] = pd.to_datetime(data['사용월'], format='%Y%m').dt.month2018년 이후, 2호선만 추출
data = data[(data.연도 >= 2018) & (data.호선명 == '2호선')]
data = data.query('호선명 == "2호선" and 연도 >= 2018')둘 다 같은 의미의 코드 지만 query를 이용해 이렇게 전처리 할 수도 있다
지하철역 이름 전처리
['강남', '강변(동서울터미널)', '건대입구', '교대(법원.검찰청)', '구로디지털단지', '구의(광진구청)', '낙성대', '낙성대(강감찬)', '당산', '대림(구로구청)', '도림천', '동대문역사문화공원', '동대문역사문화공원(DDP)', '뚝섬', '문래', '방배', '봉천', '사당', '삼성(무역센터)', '상왕십리', '서울대입구(관악구청)', '서초', '선릉', '성수', '시청', '신답', '신당', '신대방', '신도림', '신림', '신설동', '신정네거리', '신촌', '아현', '양천구청', '역삼', '영등포구청', '왕십리(성동구청)', '용답', '용두(동대문구청)', '을지로3가', '을지로4가', '을지로입구', '이대', '잠실(송파구청)', '잠실나루', '잠실새내', '종합운동장', '충정로(경기대입구)', '한양대', '합정', '홍대입구']지하철역 이름이 바뀐 경우가 있기 때문에 "()" 부분을 제거 해야한다
# 지하철역 컬럼을 "("를 기준을 split하여 리스트에 넣고 그 중 첫번째 값을 꺼낸다 -> 그러면 "(" 앞에 있는 것들만 추출된다
data['지하철역'] = [i[0] for i in data['지하철역'].str.split('(')]승차 인원 추출
사실 여기서 나는 개인적으로 isin으로 승차가 들어간 컬럼만 가져오는게 더 효율적이지 않을까 생각했는데 그렇게 되면 내가 원하는 컬럼 순서나 나중에 승차 컬럼만 필요할때 사용함에 있어서 불편함이 있기 때문에 이렇게 리스트 컴프리헨션을 사용하는게 더 적합하다.
on_col = [i for i in data.columns if '승차' in i]
data = data[['사용월','연도','월','지하철역']+on_col]합계
axis=1을 이용해 지하철역별 해당월의 승차 인원의 합을 구한다
data['합계'] = data[on_col].sum(axis=1)EDA
지하철역별 월평균 승차 인원
data_mean = data.groupby('지하철역')[['합계']].mean().reset_index().rename({'합계':'월평균'}, axis=1).sort_values('월평균', ascending=False)
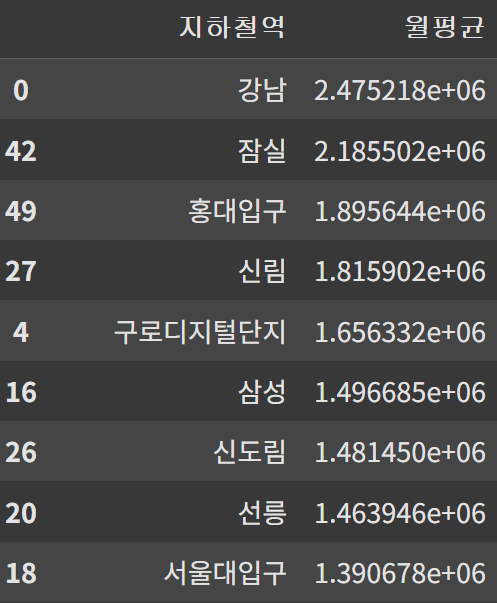
fig = px.bar(data_frame = data_mean, x='지하철역', y='월평균', title='지하철역별 월평균 승차인원')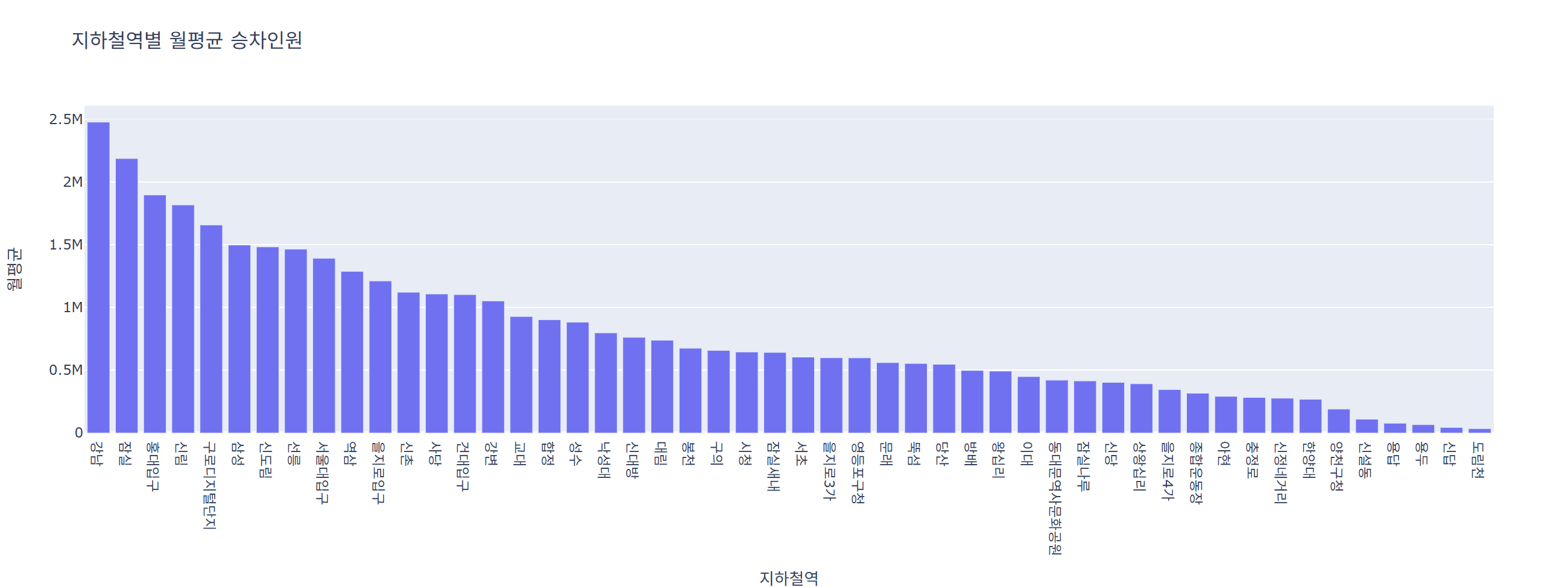
연도/월별 승차 인원 추세 파악
연도
year_sum = data.query('연도 <= 2022').groupby(['연도'])[['합계']].sum().reset_index()
year_sum['연도'] = year_sum['연도'].astype(str)
fig = px.line(data_frame=year_sum, x='연도', y='합계')
fig.show()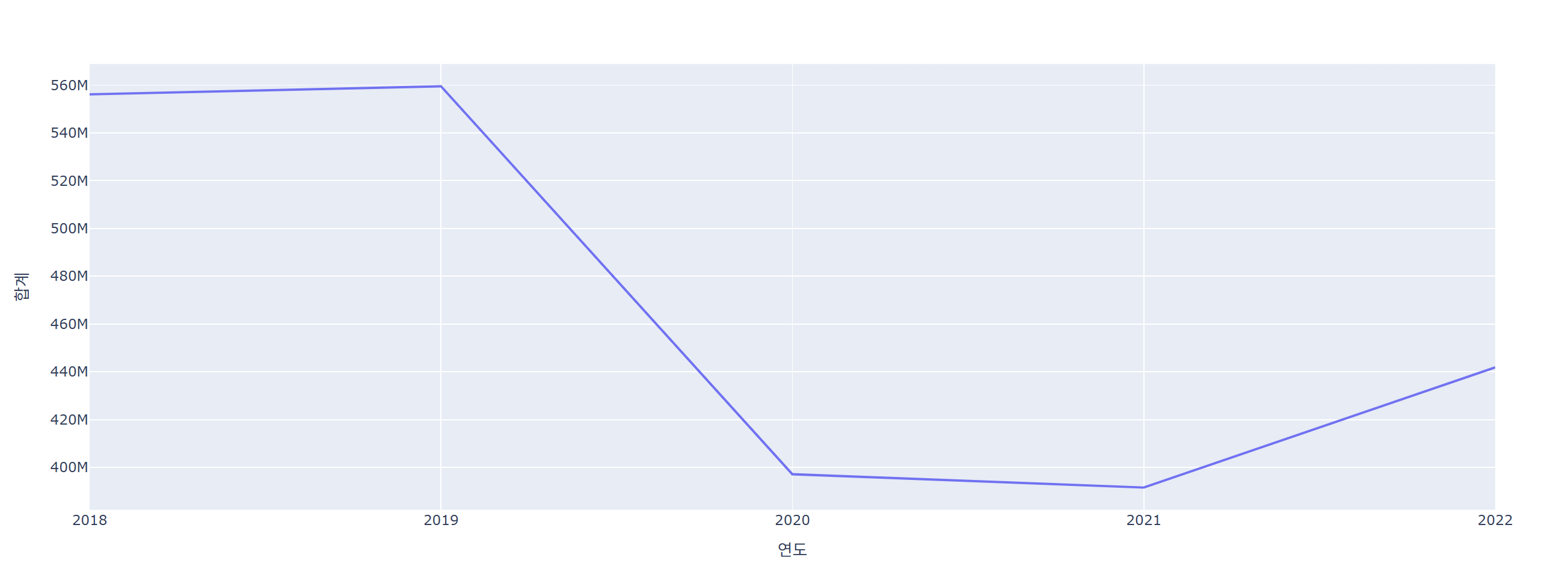
월
month_sum = data.query('연도 <= 2022').groupby(['월'])[['합계']].sum().reset_index()
month_sum['월'] = month_sum['월'].astype(str)
fig = px.line(data_frame=month_sum, x='월', y='합계')
fig.show()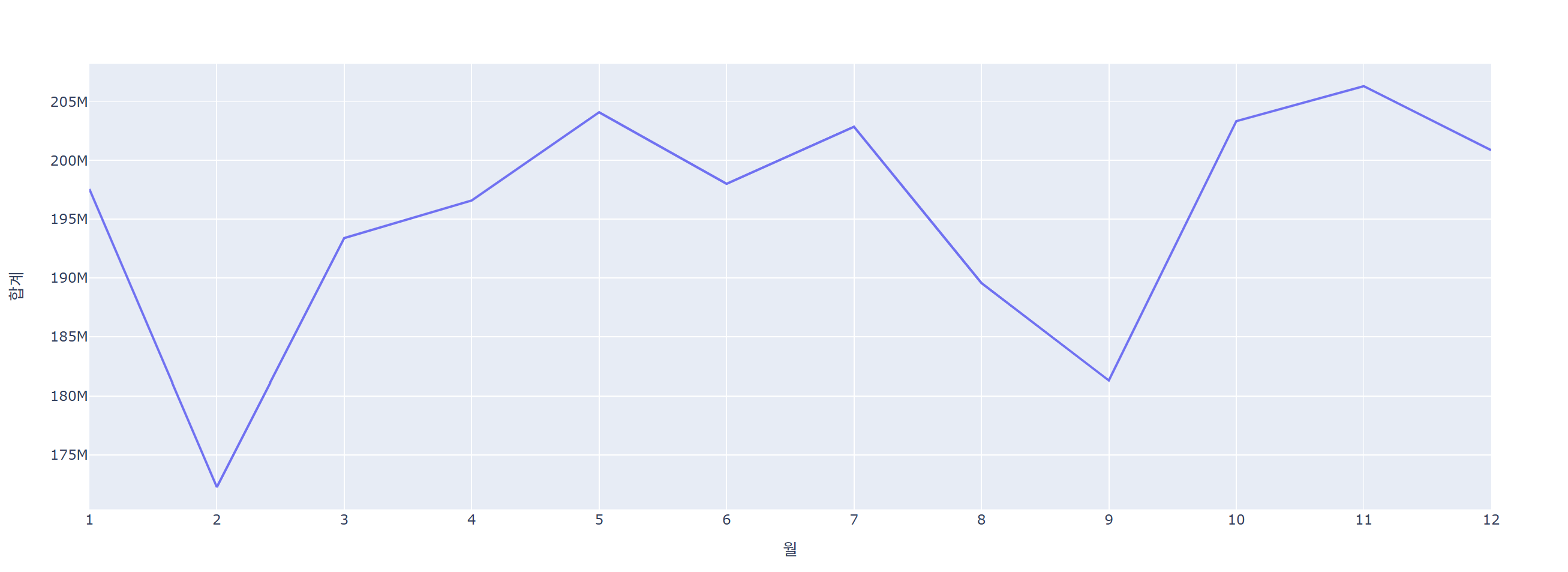
코로나가 시작된 2020년, 2021년에 인원이 많이 줄고(재택근무 영향) 2022년 부터 회복
시간대별 가장 승차인원이 많은 역
top10 = data_mean.sort_values('월평균', ascending=False).head(10)['지하철역'] top10
승하차 인원이 가장 많은 역: 강남, 잠실, 홍대입구 ...
월평균 인원수가 많은 순서로 10개만 필터링해 시간당 월평균 인원수 구하기
top10 = data_mean.sort_values('월평균', ascending=False).head(10)['지하철역']
top10_mean_hour = data.query('지하철역 in @top10').groupby('지하철역')[on_col].mean()
top10_mean_hour.columns = [i[:3] for i in top10_mean_hour.columns]히트맵 시각화
top10_mean_hour.style.background_gradient(cmap='pink_r', axis=None).format('{:.0f}')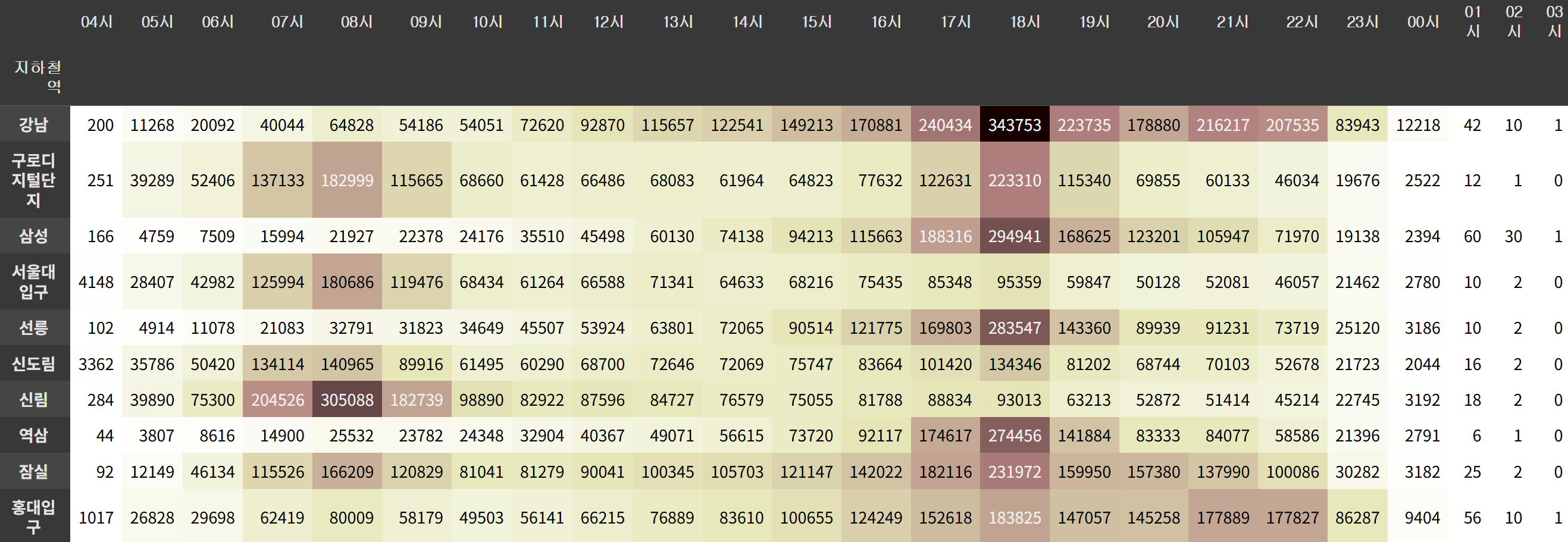
시간대별 인원 클러스터링
hour_mean = data.groupby('지하철역')[on_col].mean()
hour_mean.columns = [i[:3] for i in hour_mean.columns]
hour_mean_pct = hour_mean.div(hour_mean.sum(axis=1), axis=0)KMeans 알고리즘을 이용해 군집화
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
model = KMeans()
visualizer = KElbowVisualizer(model, k=(1,10))
visualizer.fit(hour_mean_pct)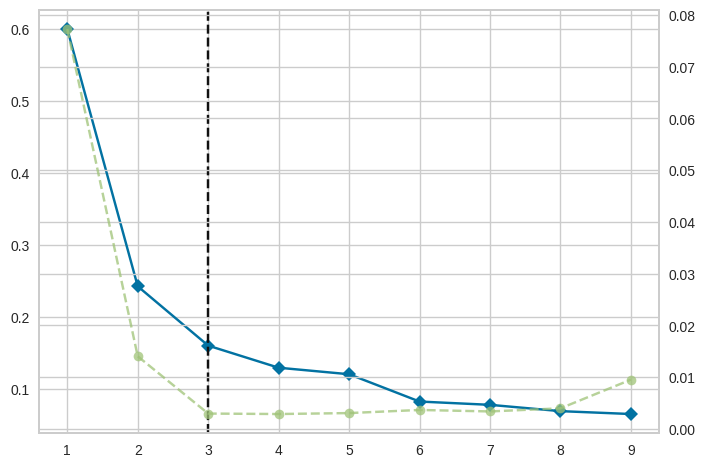
주요 출근 시간대인 06시/18시를 확인
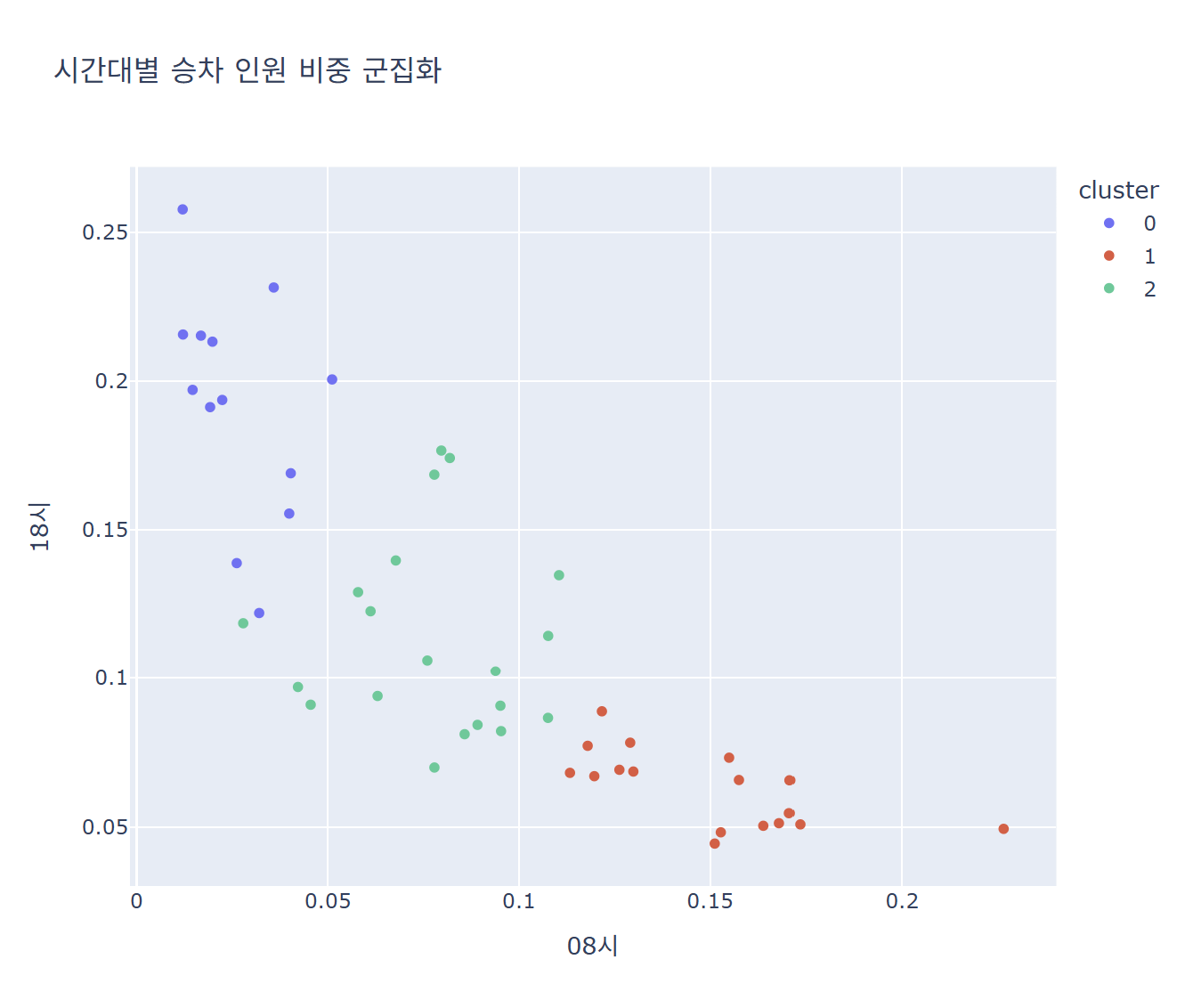
군집별 해당하는 역명 확인
for i in range(k):
print(f'cluster {i}')
print(list(hour_mean_pct.query(f'cluster == "{i}"').index))
cluster 0
['강남', '교대', '뚝섬', '삼성', '서초', '선릉', '성수', '시청', '역삼', '을지로3가', '을지로4가', '을지로입구', '한양대']
cluster 1
['강변', '구의', '낙성대', '대림', '봉천', '상왕십리', '서울대입구', '신답', '신대방', '신림', '신정네거리', '아현', '양천구청', '용답', '용두', '잠실나루', '잠실새내']
cluster 2
['건대입구', '구로디지털단지', '당산', '도림천', '동대문역사문화공원', '문래', '방배', '사당', '신당', '신도림', '신설동', '신촌', '영등포구청', '왕십리', '이대', '잠실', '종합운동장', '충정로', '합정', '홍대입구'] 시각화
위도 경도가 있는 데이터
coordinate = pd.read_csv('서울시 역사마스터 정보.csv', encoding='cp949')
coordinate.head()
앞에서 진행한 전처리 방식과 동일하게 진행 다른점은 "역사명" 컬럼명을 "지하철역"으로 컬렴명 변경
coordinate = coordinate.query('호선 == "2호선"')
coordinate['역사명'] = [i[0] for i in coordinate['역사명'].str.split('(')]
coordinate.rename({'역사명':'지하철역'}, axis=1, inplace=True)
coordinate
앞에서 구한 시간별 평균 데이터에서 '지하철역', '08시', '18시' 컬럼만 가져와서 위도/경도 데이터를 합친다
hour_mean_merge = hour_mean.reset_index()[['지하철역','08시','18시']]
coordinate_merge = coordinate[['지하철역','위도','경도']]
hour_mean_coor = pd.merge(hour_mean_merge, coordinate_merge, on='지하철역')KMeans를 활용해 군집화하여 cluster이라는 컬럼으로 추가한다
hour_mean_coor['cluster'] = model.fit_predict(hour_mean_pct).astype(str)
hour_mean_coor.head()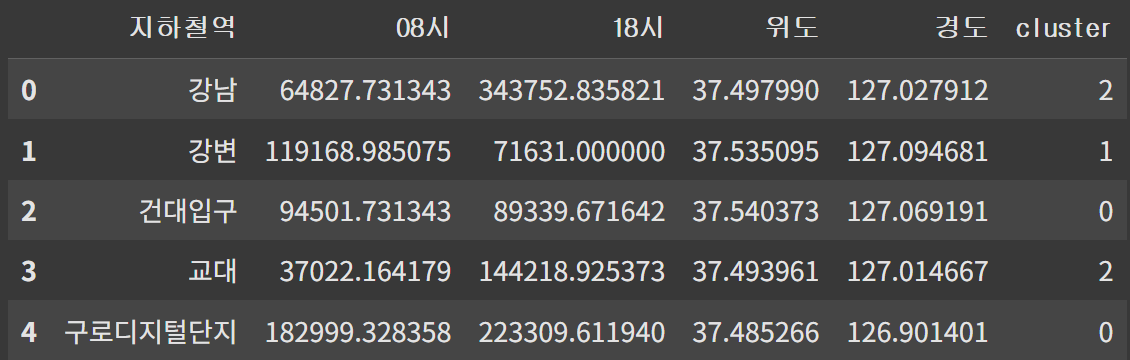
folium
승차 유형별로 지도에 시각화
m = folium.Map(location=center, zoom_start=12)
for idx in hour_mean_coor.index:
lat = hour_mean_coor.loc[idx, '위도']
long = hour_mean_coor.loc[idx, '경도']
title = hour_mean_coor.loc[idx, '지하철역']
if hour_mean_coor.loc[idx, 'cluster'] == "0":
color = '#000000'
elif hour_mean_coor.loc[idx, 'cluster'] == "1":
color = '#3A01DF'
else:
color = '#DF0101'
folium.CircleMarker([lat, long]
, radius=18
, color = color
, fill = color
, tooltip = title).add_to(m)
m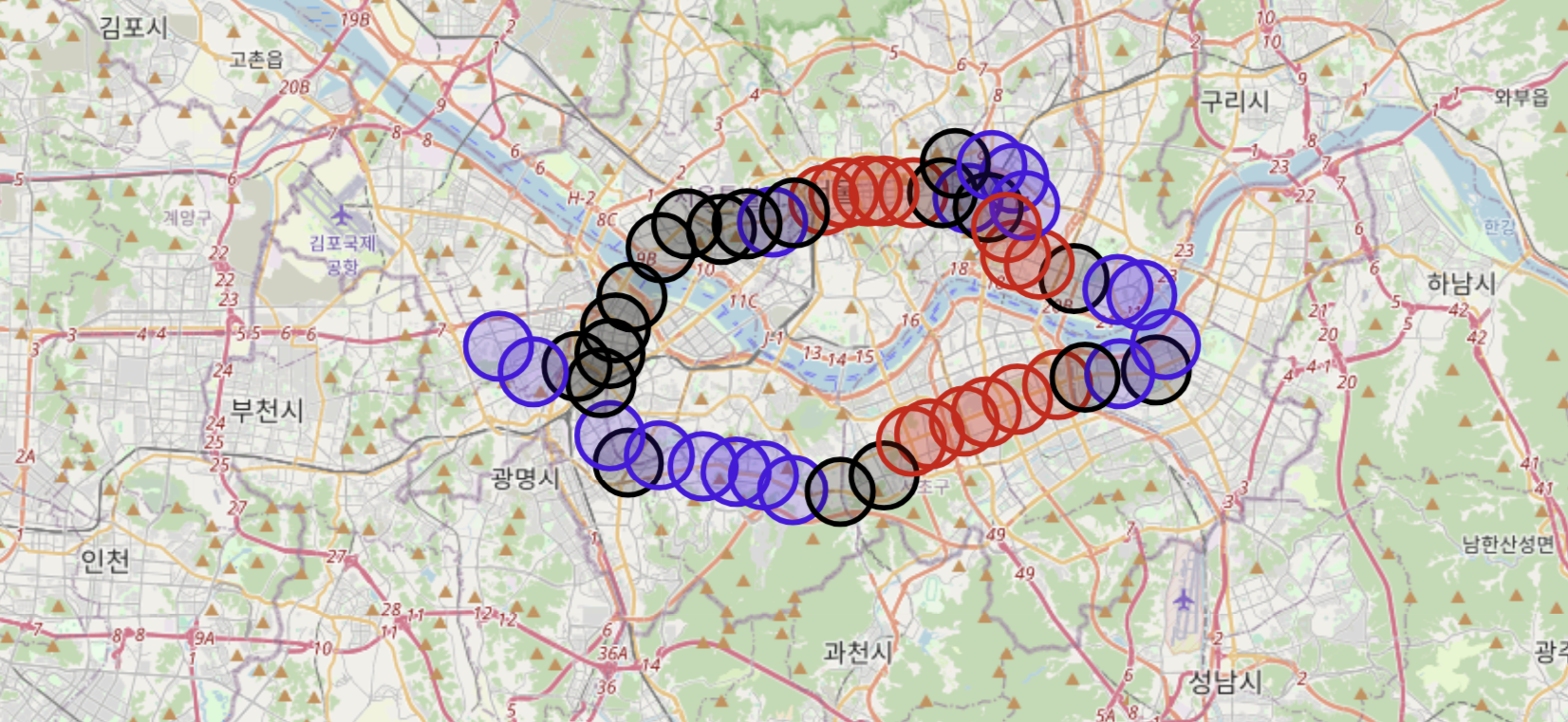
0번 cluster: 주거 지역이 많이 분포
1번 cluster: 주거/상업 시설/회사가 비슷하게 분포
2번 cluster: 회사가 많이 분포
