
데이터 탐색
movies 데이터
- budget: 영화 예산 (단위: 달러)
- genres: 모든 장르
- homepage: 공식 홈페이지
- id: 각 영화당 unique id
- original_language: 원 언어
- original_title: 원 제목
- overview: 간략한 설명
- popularity: TMDB에서 제공하는 인기도
- production_companies: 모든 제작사
- production_countries: 모든 제각국가
- release_date: 개봉일
- revenue: 흥행 수익 (단위: 달러)
- runtime: 상영 시간
- spoken_language: 사용된 모든 언어
- status: 개봉 여부
- title: 영문 제목
- vote_avearage: TMDB에서 받은 평점 평균
- vote_count: TMDB에서 받은 투표수
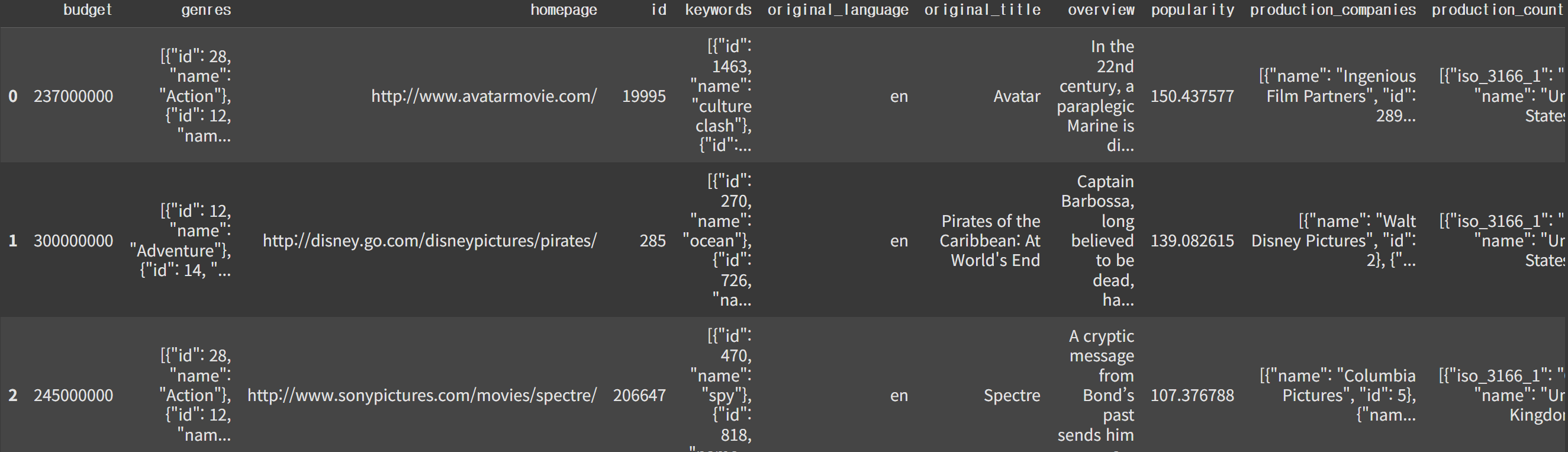
credits 데이터
- movie_id: 각 영화당 unique id
- title: 영문 제목
- cast: 모든 출연진
- crew: 모든 제작진

데이터 전처리
필요 없는 컬럼 제외
movies_df = movies[['id','budget','genres','title','release_date','revenue','vote_average','vote_count']]
credits_df = credits[['movie_id','crew','castmovies, credits 데이터 결합
data = pd.merge(movies_df, credits_df, left_on = 'id', right_on = 'movie_id').drop('movie_id', axis=1)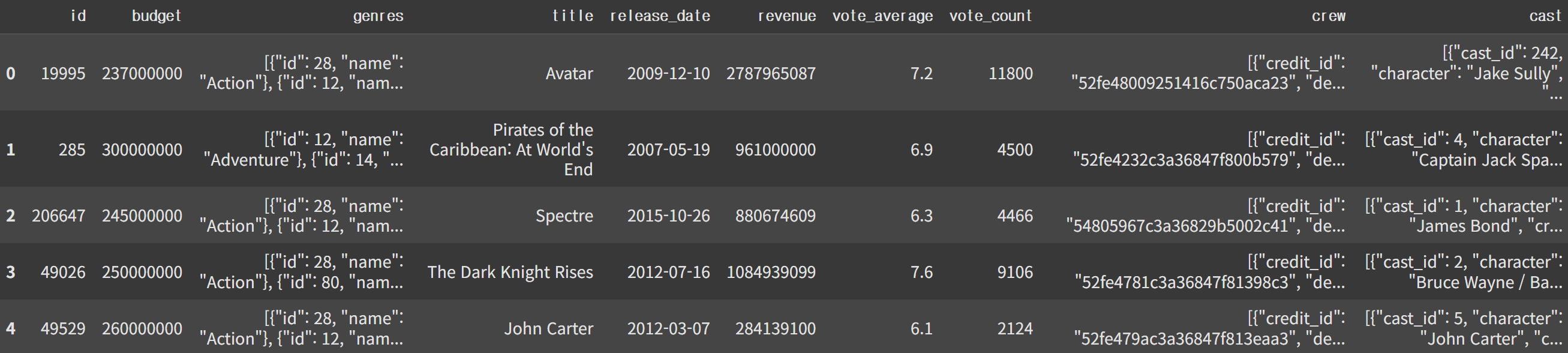
새로운 컬럼 만들기
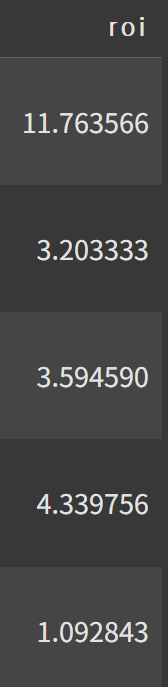
roi 컬럼
data['roi'] = data['revenue'] / data['budget']
data.head()
감독 컬럼
crew 컬럼은 문자열 타입의 딕셔너리로 구성되있다
data['crew'][0]
'[{"credit_id": "52fe48009251416c750aca23", "department": "Editing", "gender": 0, "id": 1721, "job": "Editor", "name": "Stephen E. Rivkin"}, {"credit_id": "539c47ecc3a36810e3001f87", "department": "Art", "gender": 2, "id": 496, "job": "Production Design", "name": "Rick Carter"}, {"credit_id": "54491c89c3a3680fb4001cf7", "department": "Sound", "gender": 0, "id": 900, "job": "Sound Designer", "name": "Christopher Boyes"}ast 라이브러리를 이용해 문자열 -> 리스트로 변경
import ast
print(ast.literal_eval(data['crew'][0]))
data['crew'] = data['crew'].apply(ast.literal_eval) # 리스트 형태로 바꾼다감독의 이름을 리턴하는 함수
def get_director(x):
for i in x:
if i['job'] == 'Director':
return i['name']apply 메서드를 이용해 감독의 이름을 리턴해 'director' 컬럼에 저장
data['director'] = data['crew'].apply(get_director)

배우 컬럼
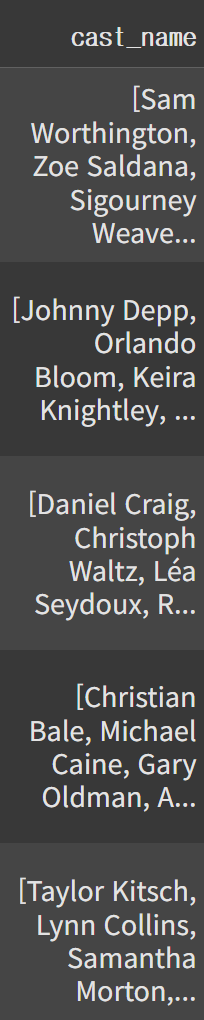
배우 컬럼도 cast 컬럼을 ast 라이브러리를 이용해 문자열을 리스트로 저장
data['cast_name'] = data['cast'].apply(lambda x: [i['name'] for i in ast.literal_eval(x)])
# 문자열 -> 리스트 -> 'name' key 만 가져와서 리스트로 저장
data.head()
장르 컬럼
장르도 앞에서 했던 것 처럼 새로운 'main_genre' 컬럼 생성

데이터 타입 변경
data['release_date'] = pd.to_datetime(data['release_date'], format='%Y-%m-%d')
data['id'] = data['id'].astype(str)
# 연도, 월 컬럼 만들기
data['year'] = data['release_date'].dt.year
data['month'] = data['release_date'].dt.month결측치 제거
data.dropna(inplace=True)EDA
연도별 흥행 수익
revenue_by_year = data.groupby('year')[['revenue']].sum().reset_index() # plotly의 x로 year가 들어가기 위해 reset_index 사용
fig = px.line(data_frame=revenue_by_year, x="year", y="revenue")
fig.show()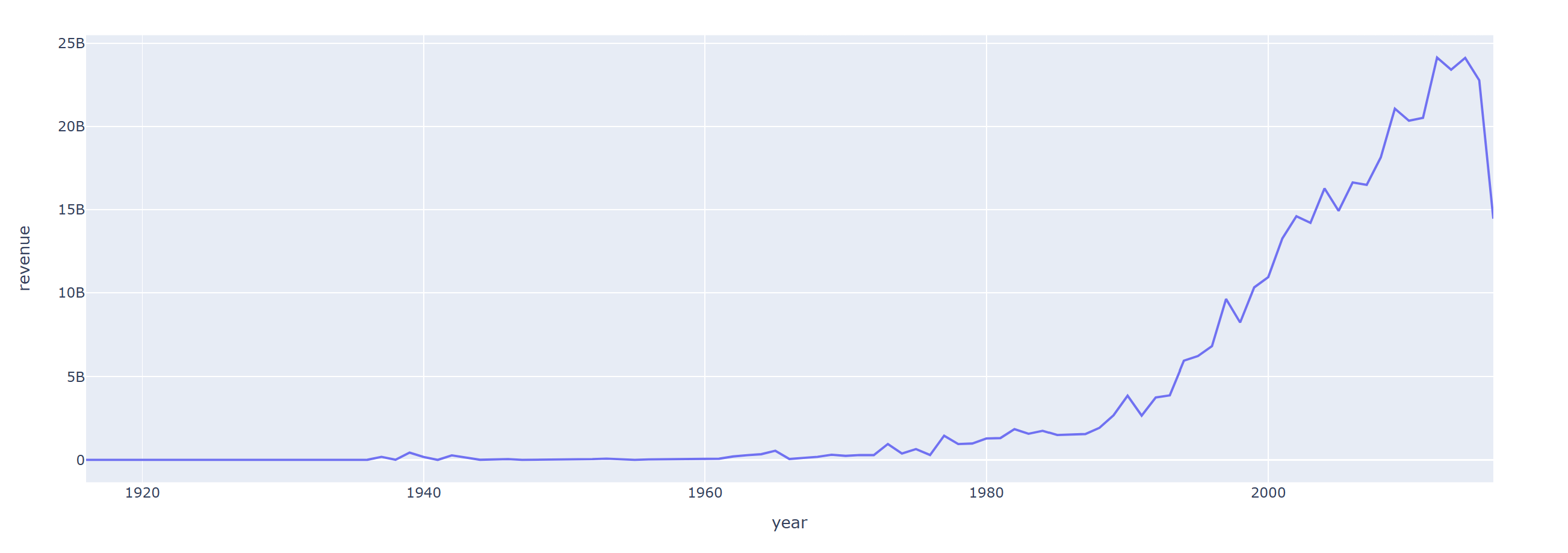
2000년대 이후로 흥행 수익이 급격히 높아짐
가장 흥행한 영화 10개
top = data.groupby('title')['revenue'].sum().reset_index().sort_values('revenue', ascending=False).head(10)
fig = px.bar(data_frame=top, x='title', y='revenue', title=f"흥행 수익 TOP 10 영화")
fig.show()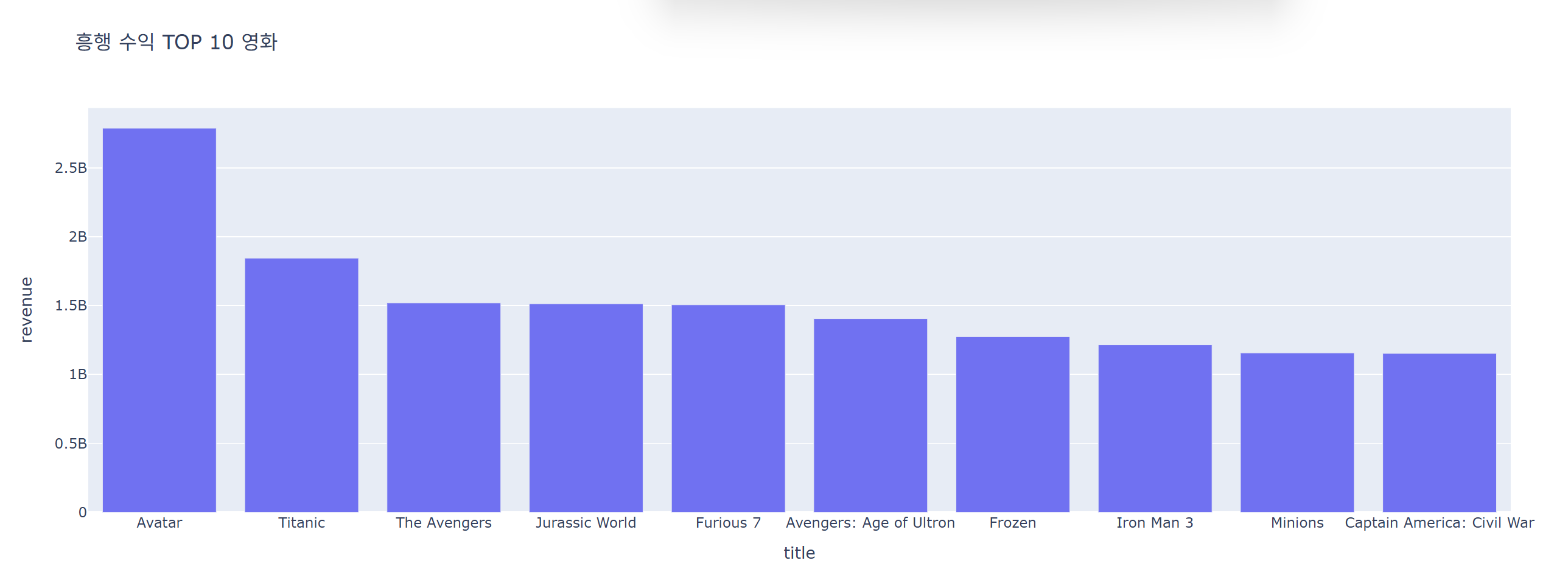
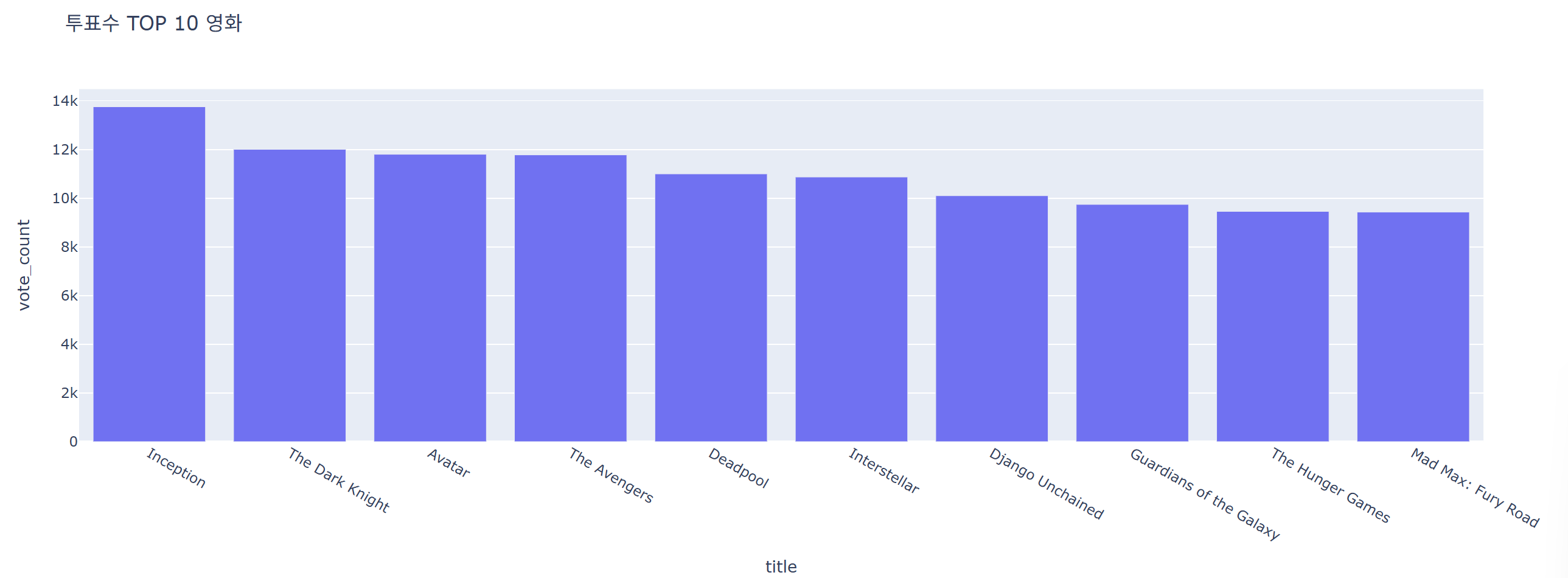
예산, 투표수 상위 10개 영화
title_dic = {'budget':'예산', 'vote_count':'투표수'}
for y in ['budget','vote_count']:
top = data.groupby('title')[[y]].sum().reset_index().sort_values(y, ascending=False).head(10)
fig = px.bar(data_frame=top, x='title', y=y, title=f"{title_dic[y]} TOP 10 영화")
fig.show()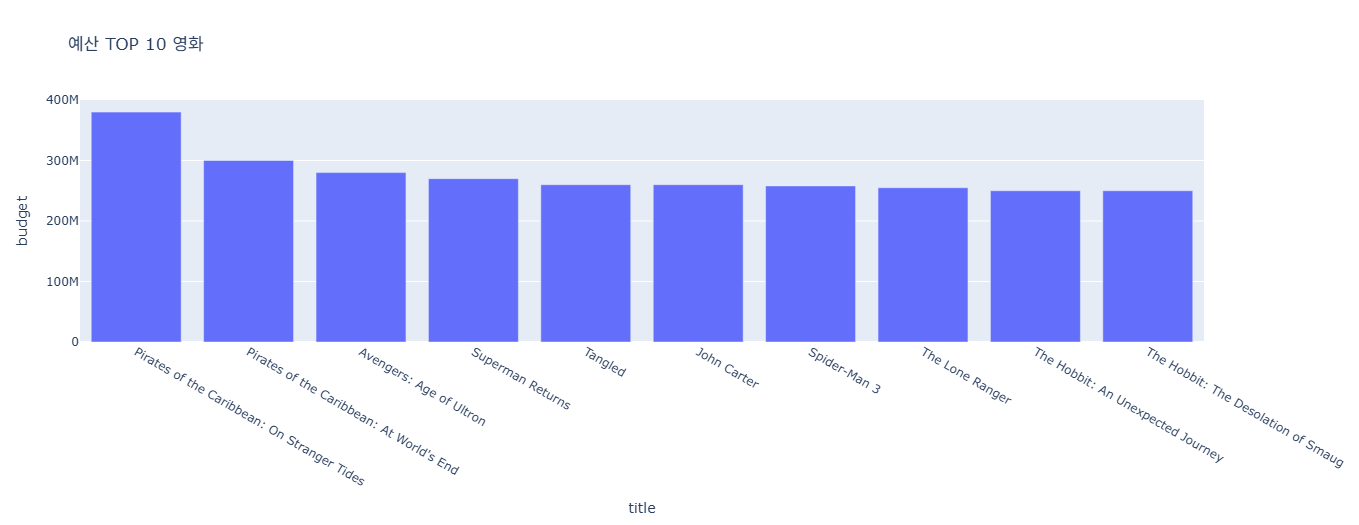
가장 흥행에 성공한 감독, 배우
top_director = data.groupby(['director'])['revenue'].sum().reset_index().sort_values('revenue', ascending=False).head(10)
fig = px.bar(data_frame=top_director, x='director', y='revenue', title=f"흥행 수익 TOP 10 감독")
fig.show()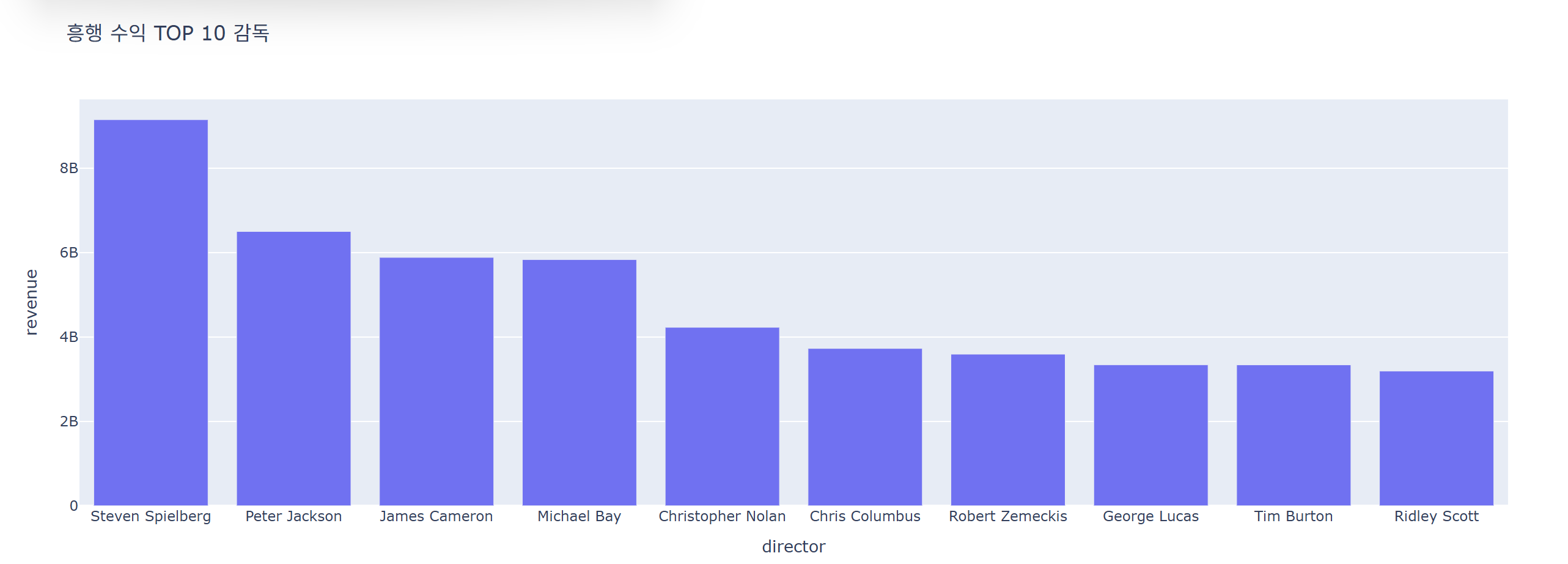
흥행 수익이 높은 배우들의 목록을 확인하기 위해 explode 메서드를 활용해 확인
revenue_cast = data[['revenue', 'cast_name']].explode('cast_name') # explode: 리스트 형태의 값을 여러행으로 전개top_cast = revenue_cast.groupby('cast_name')[['revenue']].sum().reset_index().sort_values('revenue', ascending=False).head(10)
fig = px.bar(data_frame=top_cast, x='cast_name', y='revenue', title=f"흥행 수익 TOP 10 배우")
fig.show()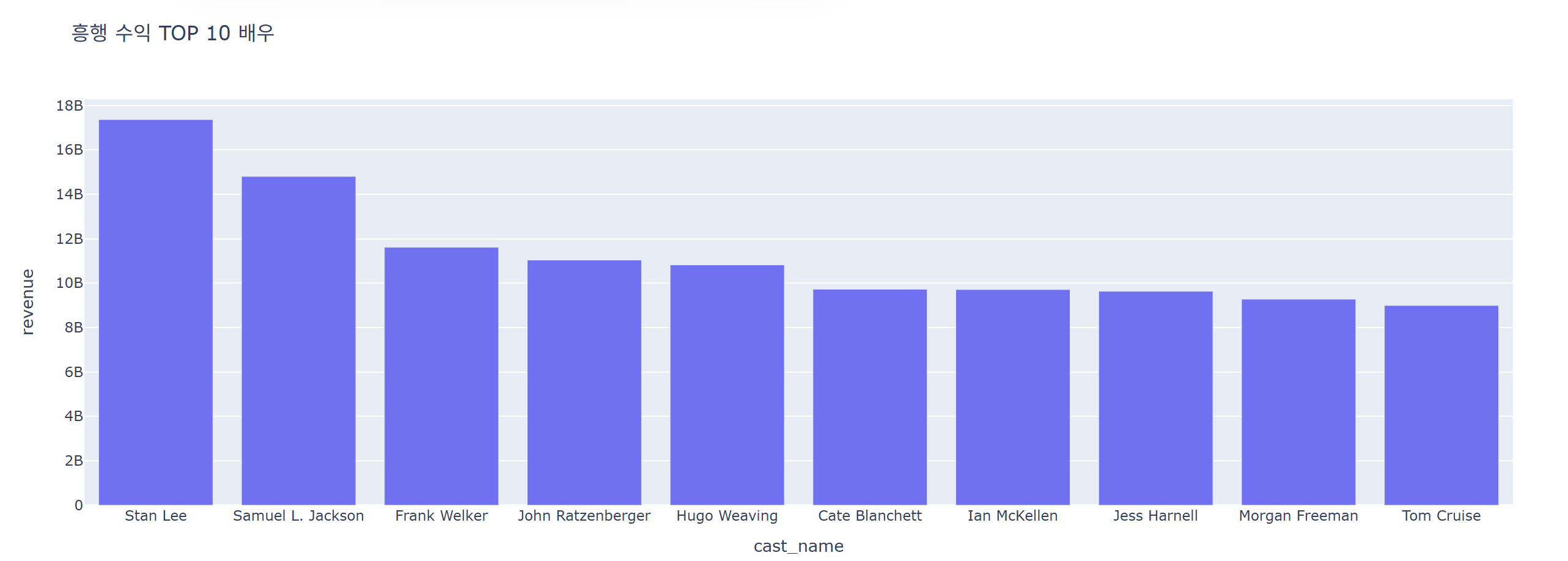
장르별 흥행 수익의 분포
fig = px.box(data_frame = data, y = 'main_genre', x = 'revenue', hover_name = 'title')
fig.show()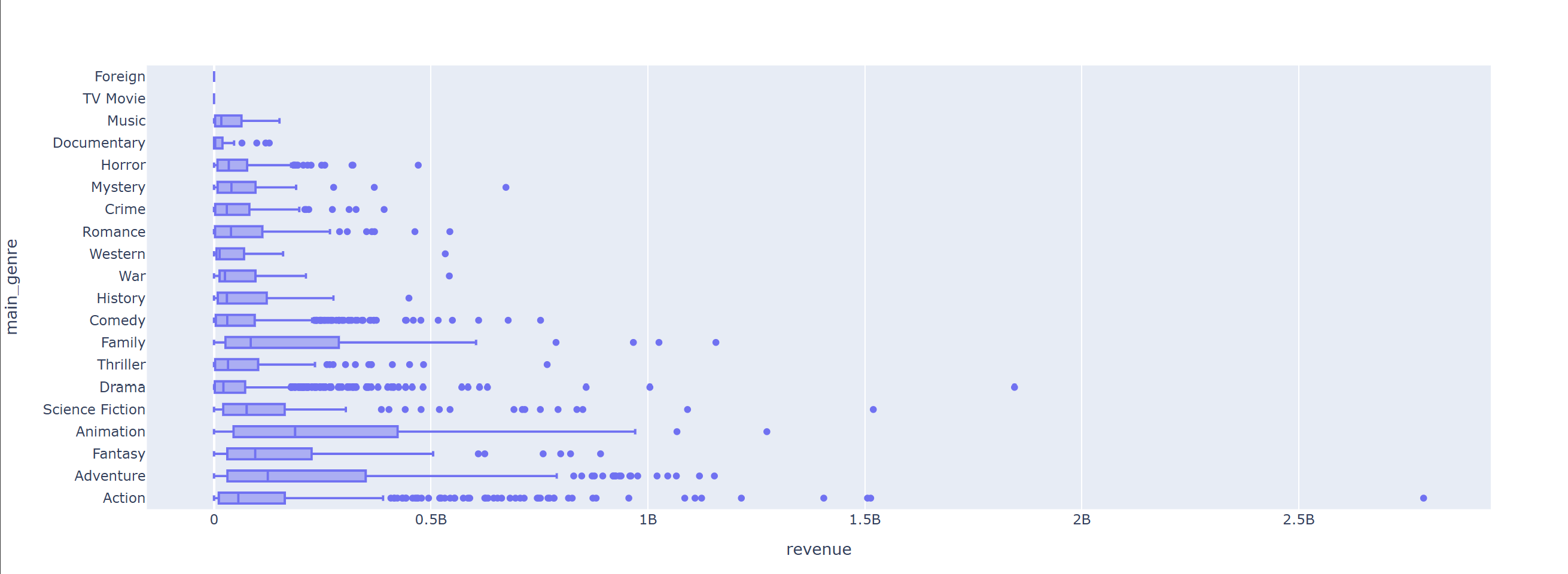
액션과 드라마 장르에 수익이 매우 높은 영화들이 많이 있지만, 중앙값을 비교했을 때, 다른 장르에 비해 높지 않다
genre_avg_revenue = data.groupby('main_genre')[['revenue']].mean().reset_index()
fig = px.bar(data_frame = genre_avg_revenue, x = 'main_genre', y = 'revenue', title = '장르별 흥행 수익 평균')
fig.show()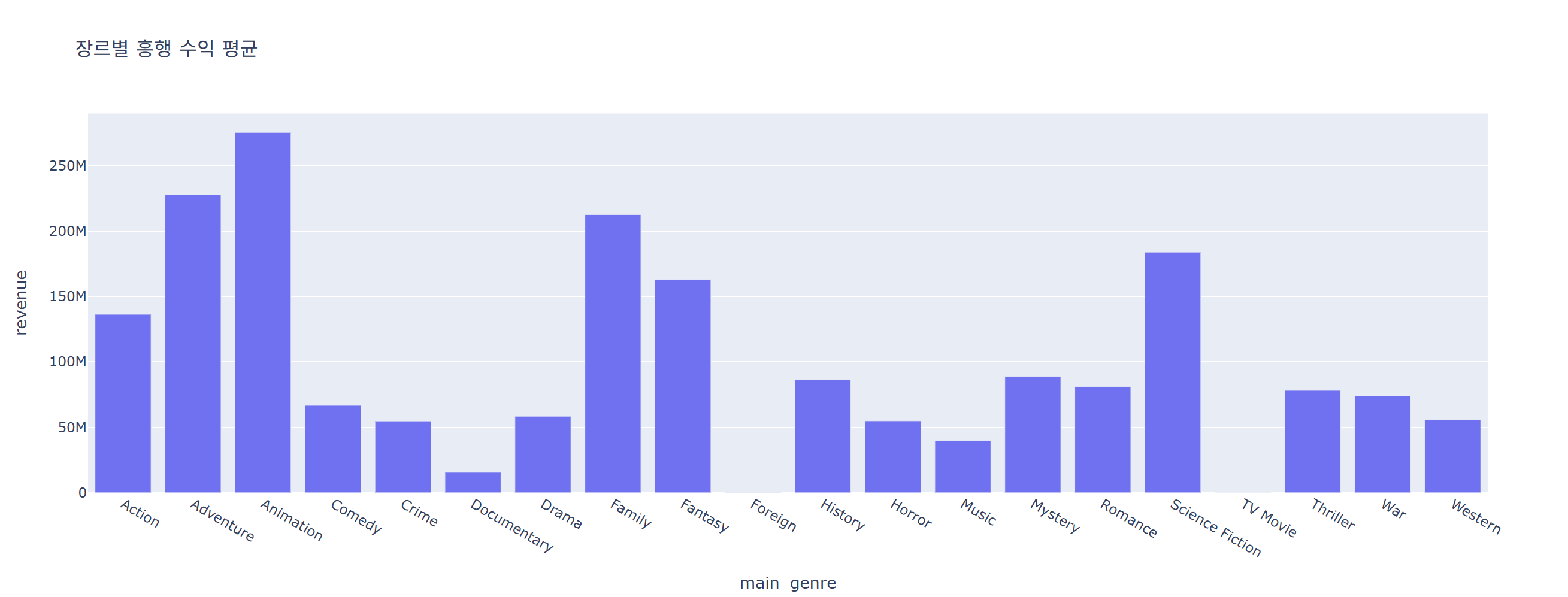
장르별 영화 수익의 평균은 애니메이션>어드벤쳐>가족>SF>판타지>액션 순서
genre_sum_revenue = data.groupby('main_genre')[['revenue']].sum().reset_index()
fig = px.bar(data_frame = genre_sum_revenue, x = 'main_genre', y = 'revenue', title = '장르별 흥행 수익 합계')
fig.show()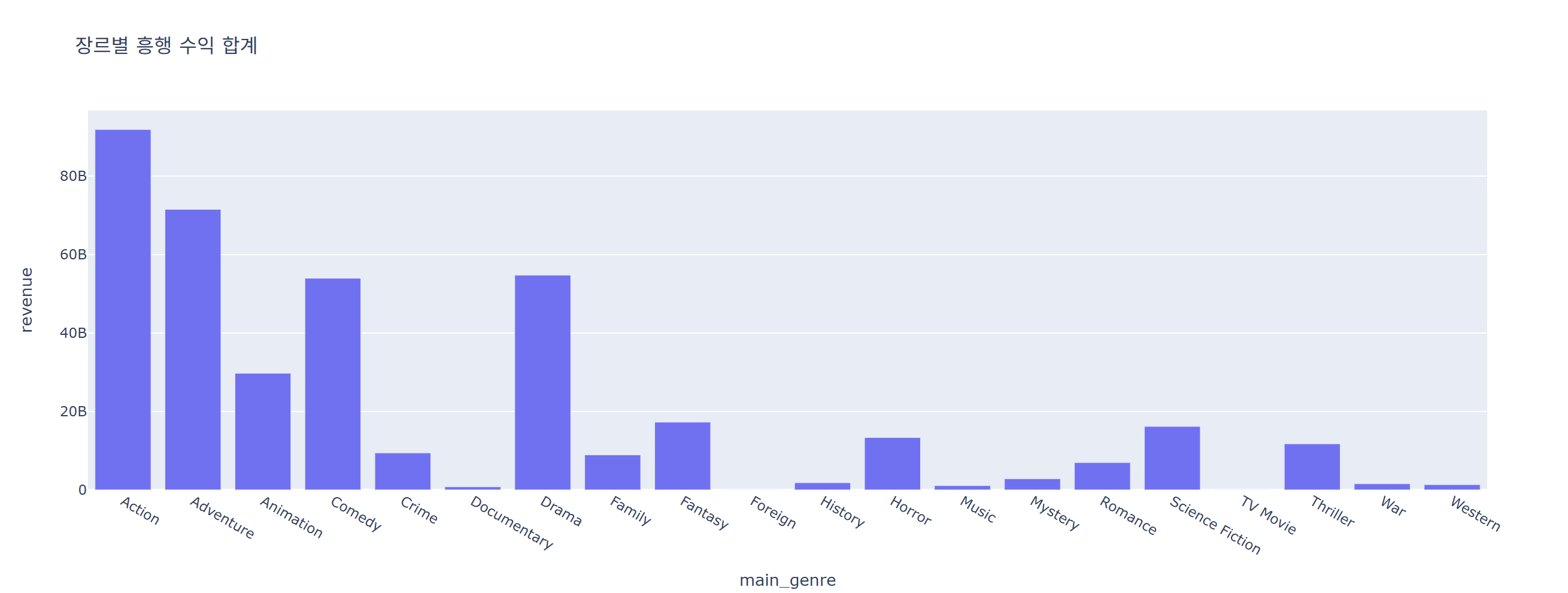
흥행 수익 합계는 액션>어드벤쳐>드라마>코미디>애니메이션 순서
연도별 장르별 수익
revenue_by_year_genre = data.query('year >= 1990').groupby(['year','main_genre'])[['revenue']].sum().reset_index()
fig = px.bar(data_frame=revenue_by_year_genre, x="year", y="revenue", color='main_genre', color_discrete_sequence=px.colors.qualitative.Light24_r)
fig.show()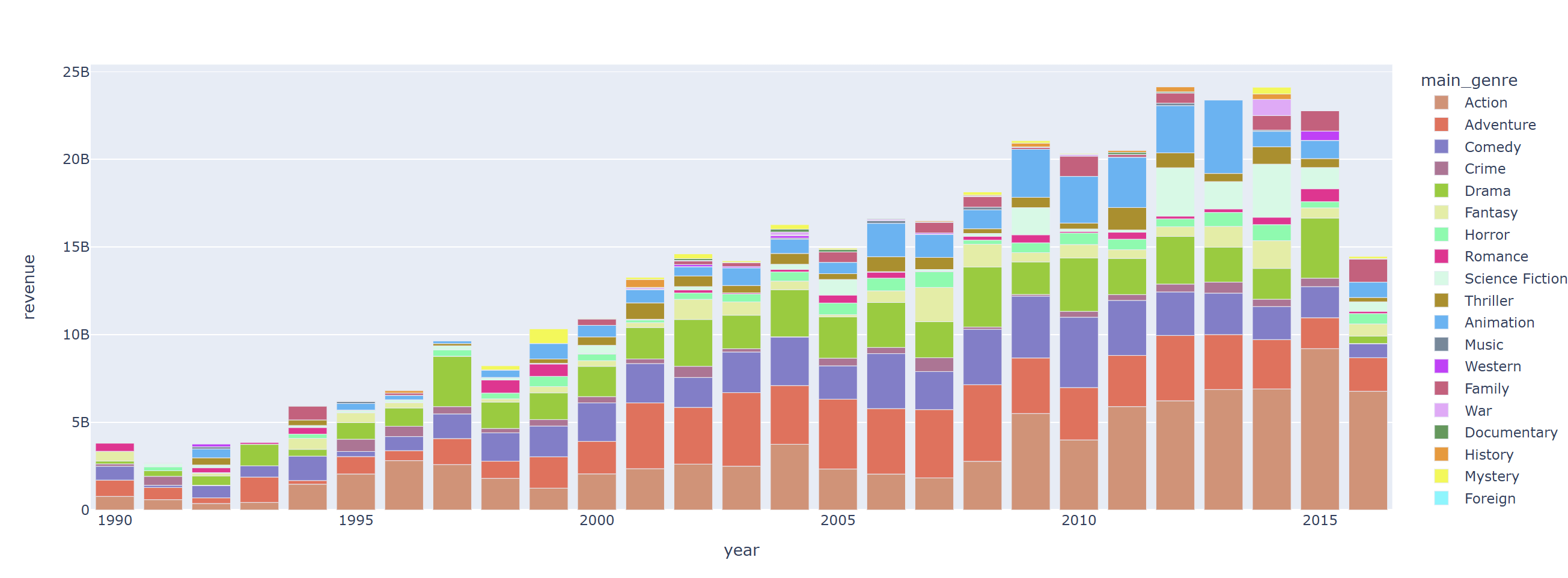
revenue_by_year_genre_pct = pd.pivot_table(data=data.query('year >= 1990'), index='year', columns='main_genre', values='revenue', aggfunc=sum, fill_value=0, margins=True)
revenue_by_year_genre_pct = 100 * revenue_by_year_genre_pct.div(revenue_by_year_genre_pct.iloc[:,-1], axis=0).drop('All').drop('All', axis=1)
revenue_by_year_genre_pct = pd.melt(revenue_by_year_genre_pct.reset_index(), id_vars='year', value_name='pct')
fig = px.bar(data_frame=revenue_by_year_genre_pct, x="year", y="pct", color='main_genre', color_discrete_sequence=px.colors.qualitative.Light24_r)
fig.show()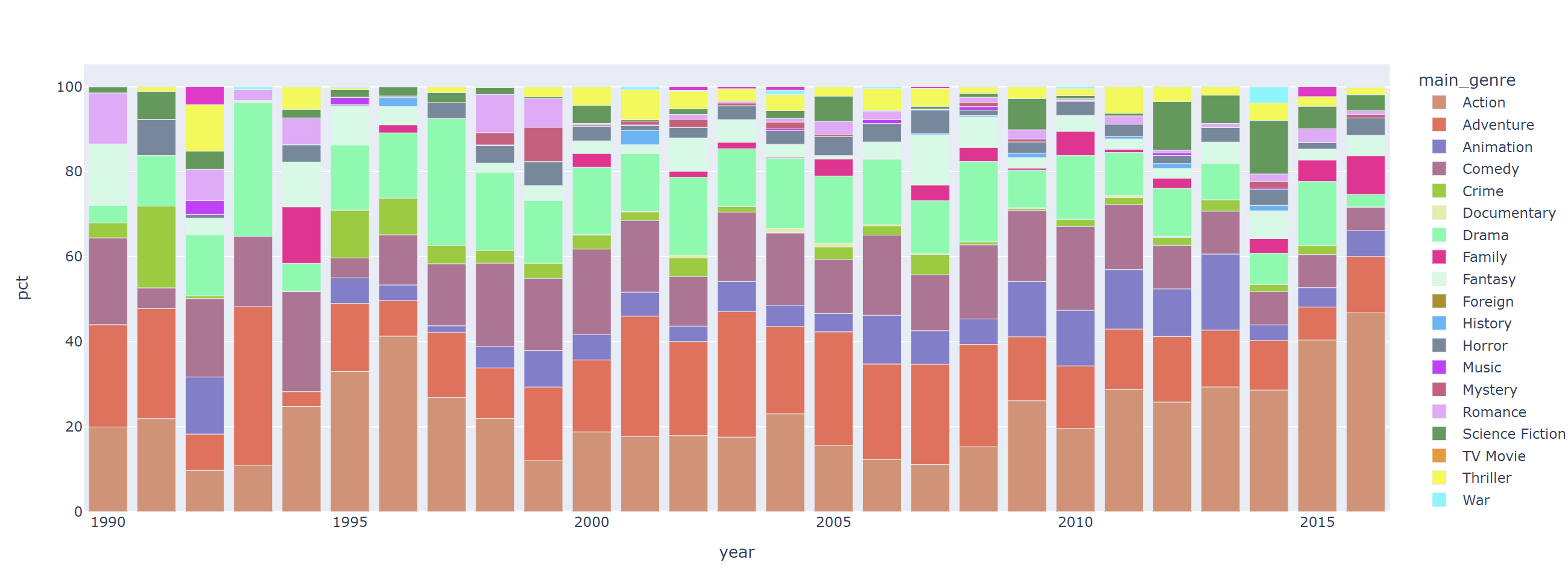
2010년도부터 액션 영화의 흥행 수익 비중이 높아지기 시작
1990년 후반 ~ 2000년대 초반에는 드라마 장르의 흥행 수익이 높았다
revenue_by_month_genre = data.query('year >= 1990').groupby(['month','main_genre'])[['revenue']].sum().reset_index()
fig = px.bar(data_frame=revenue_by_month_genre, x="month", y="revenue", color='main_genre', color_discrete_sequence=px.colors.qualitative.Light24_r)
fig.show()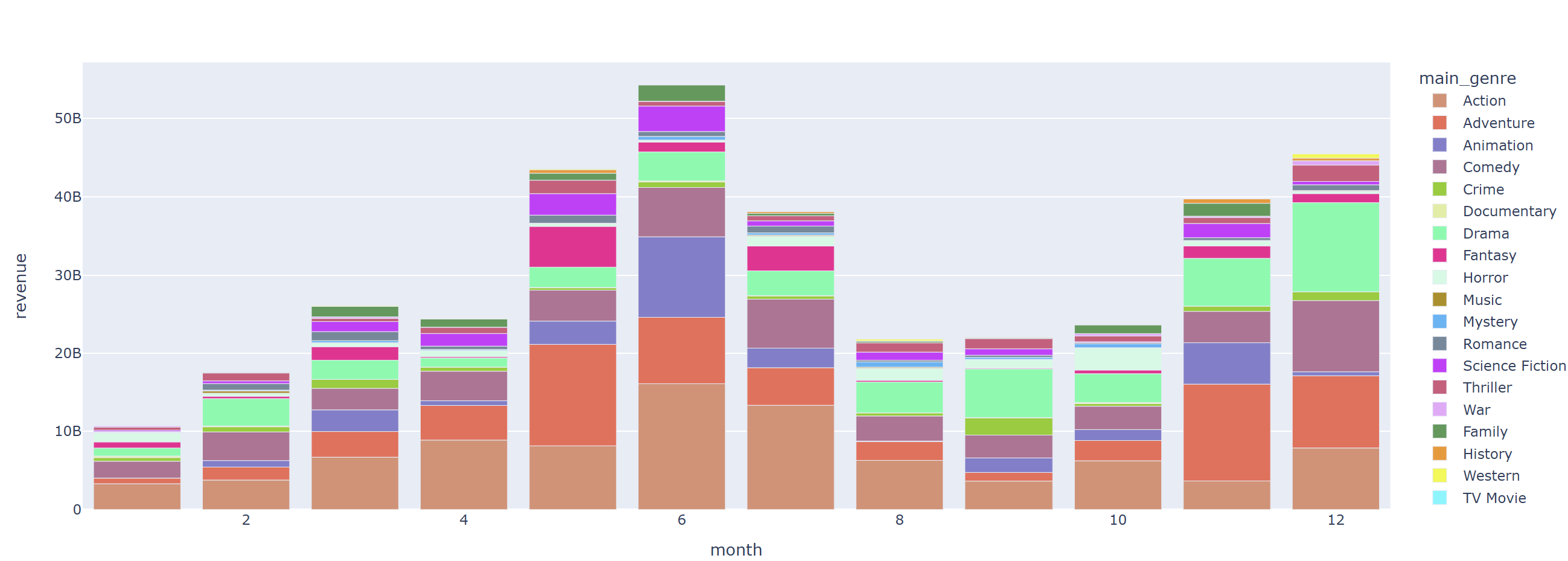
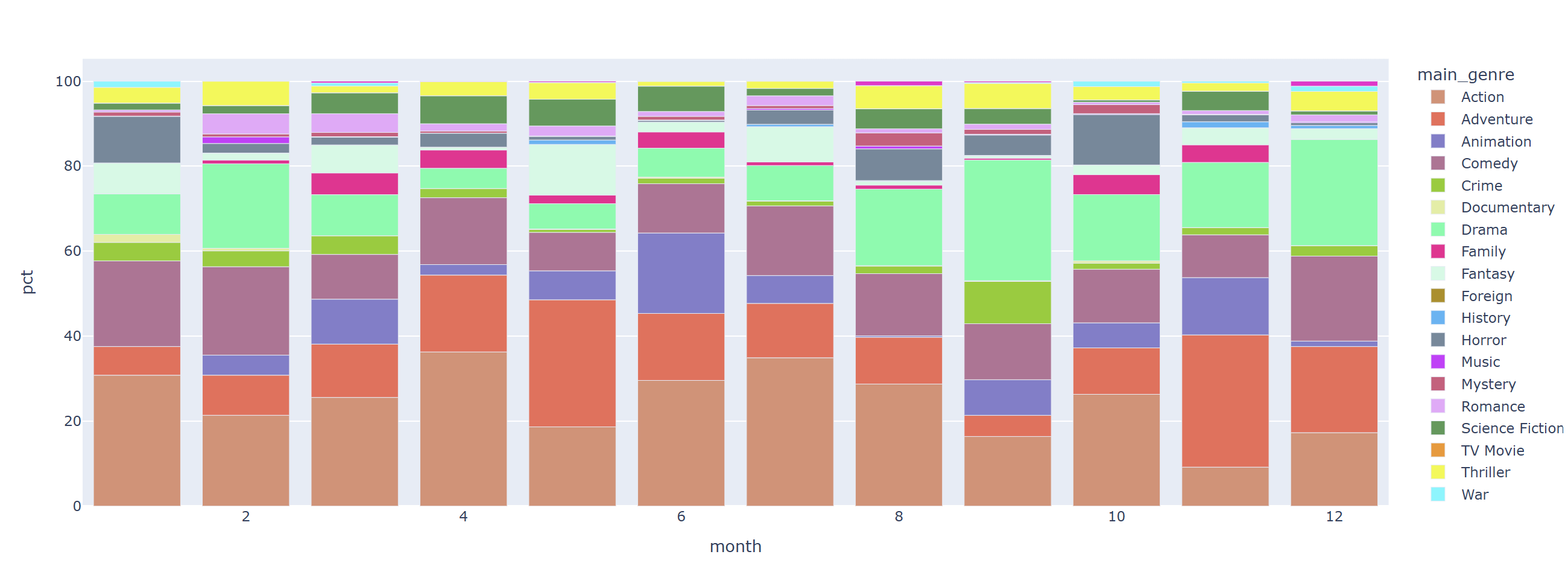
액션, 어드벤처 장르는 비교적 봄, 여름에 개봉 수익이 높았다
드라마 장르는 비교적 가을, 겨울에 개봉 수익이 높았다.
코미디 장르는 비교적 겨울에 개봉 수익이 높았다.
수익, 예산, 투표수, 평점의 상관관계
fig = px.imshow(data[['budget','revenue','vote_average','vote_count']].corr(), text_auto='.2f', color_continuous_scale='Purp')
fig.show()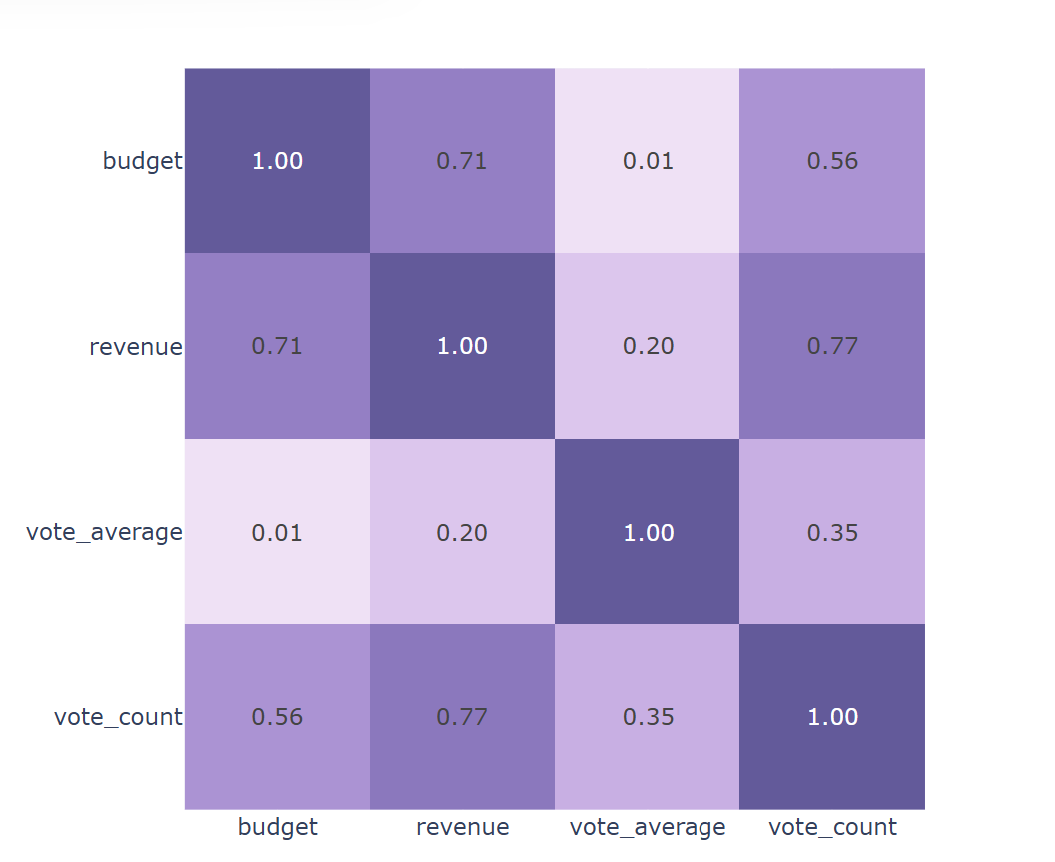
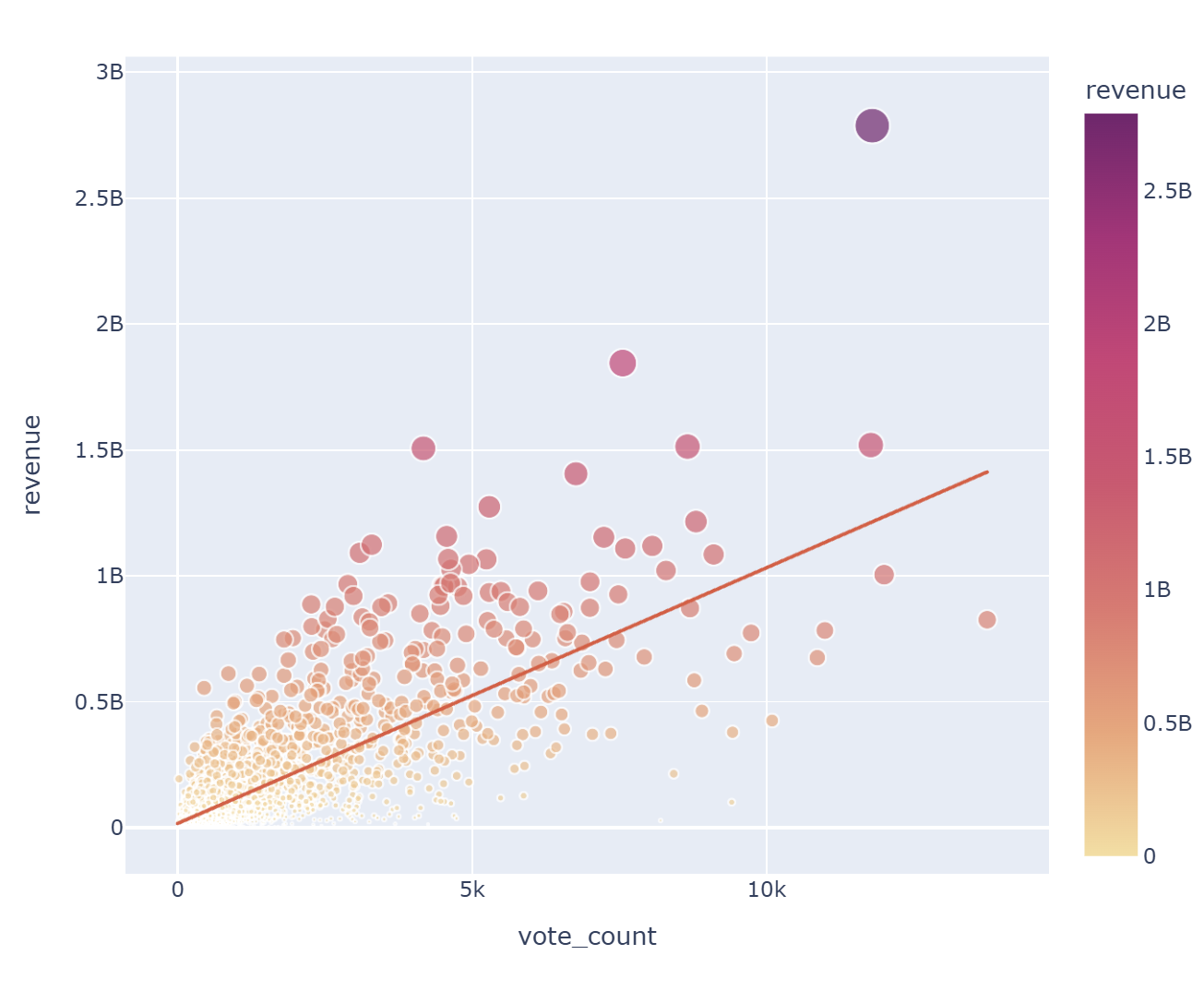
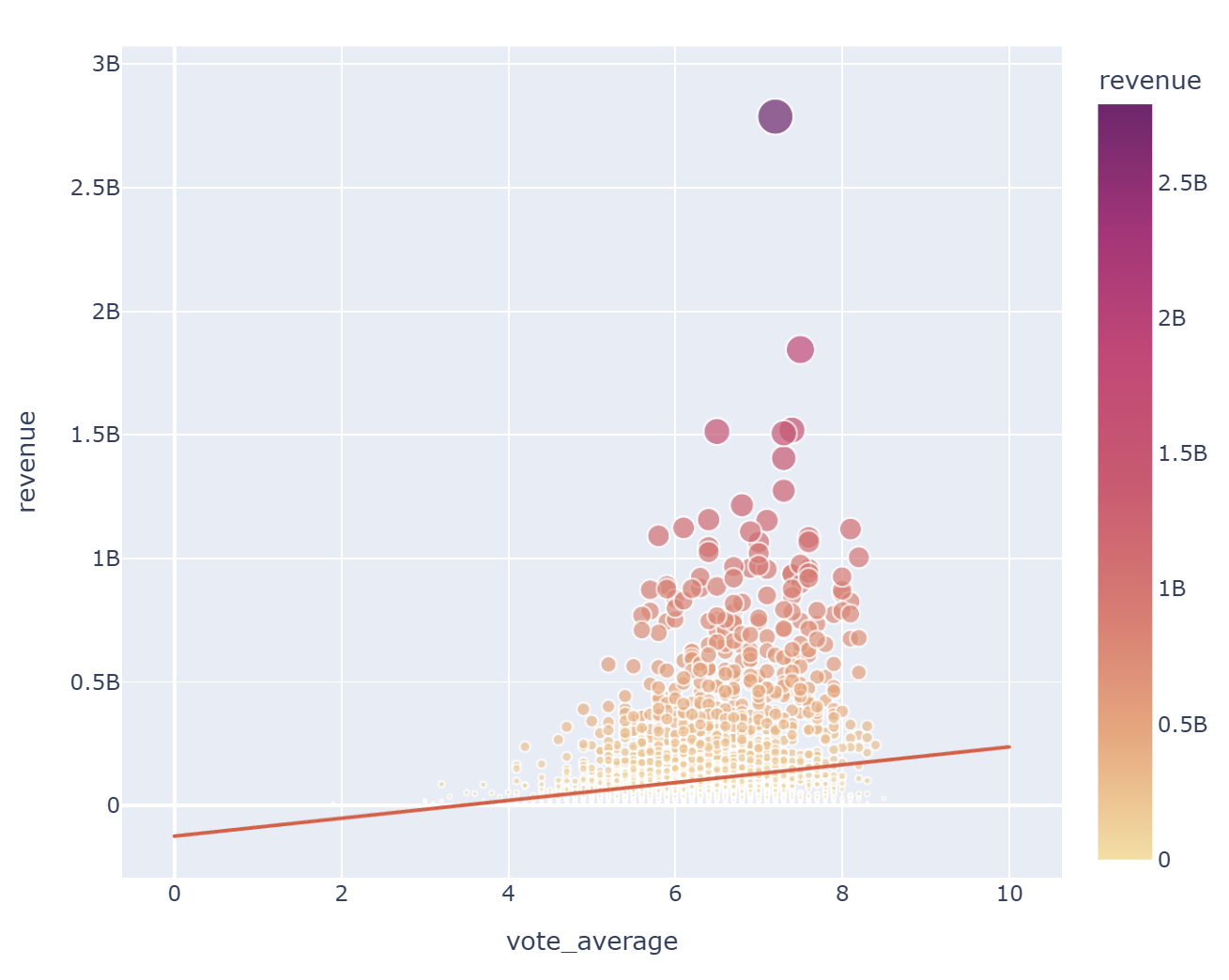
for x in ['budget', 'vote_count', 'vote_average']:
fig = px.scatter(data_frame = data, x = x, y = 'revenue', hover_name = 'title', size = 'revenue', color = 'revenue'
, color_continuous_scale = px.colors.sequential.Sunsetdark, width = 700, height = 600, trendline = 'ols')
fig.show()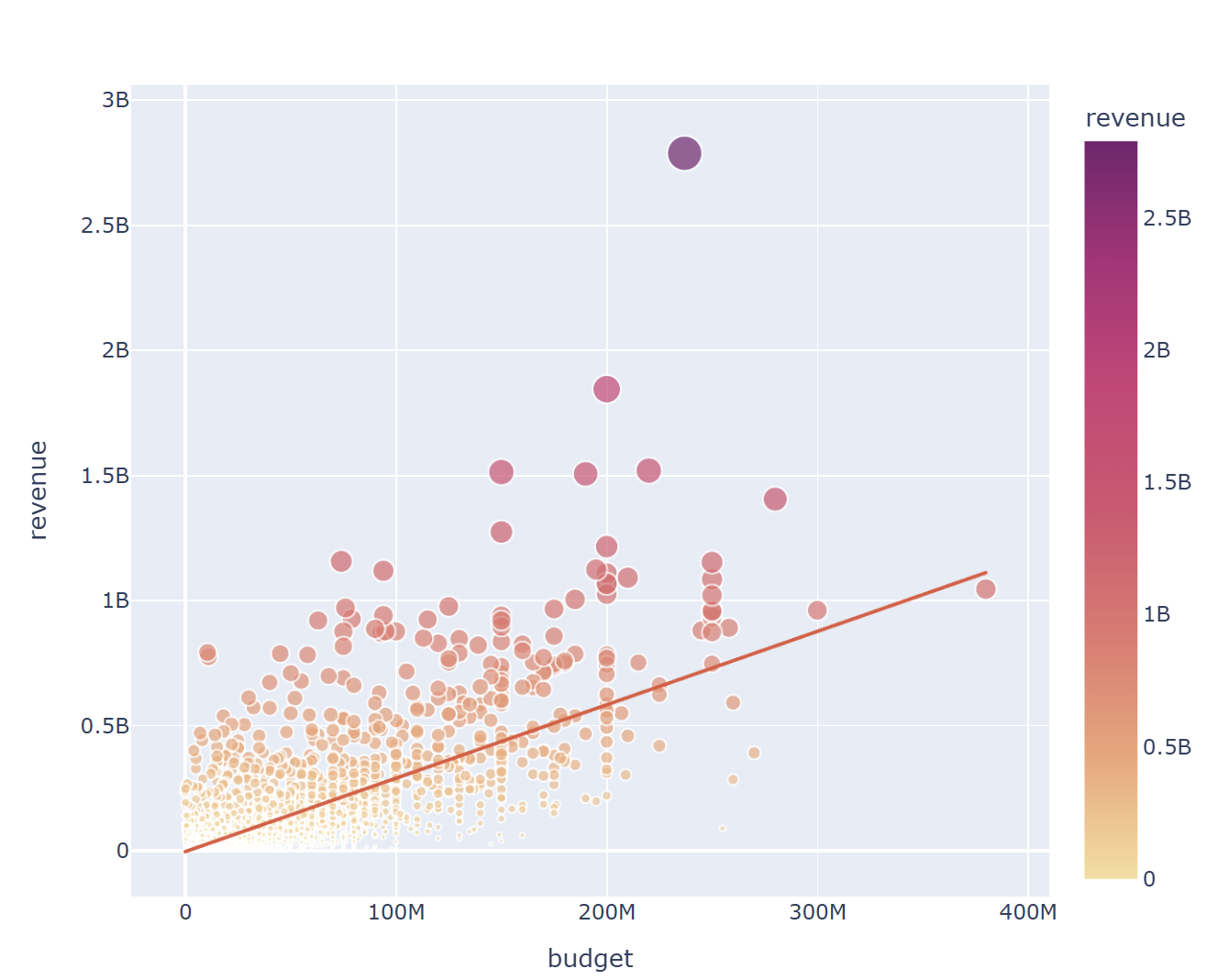
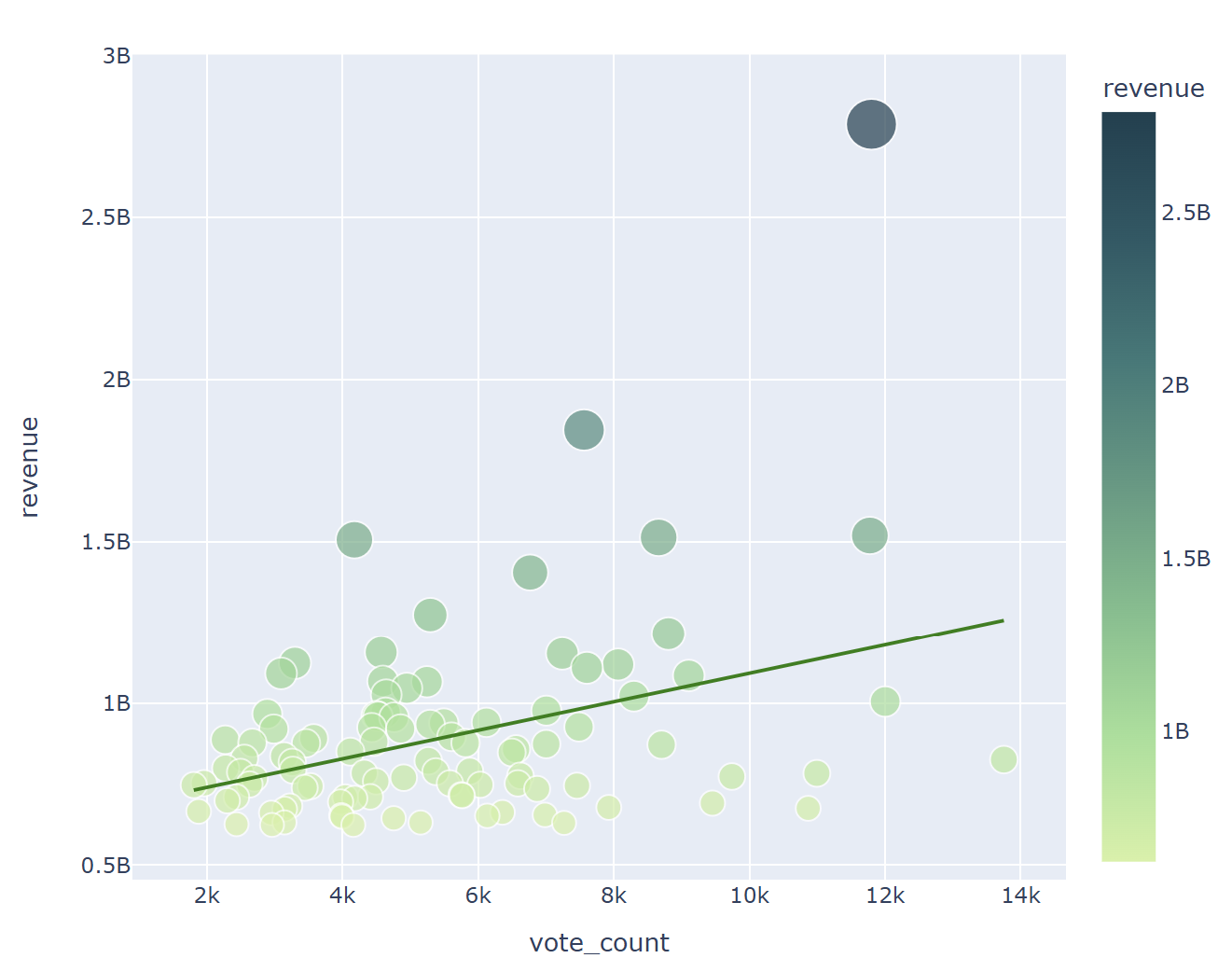
- 흥행 수익 상위 100개의 영화들에 대해서만 상관관계 확인
for x in ['budget', 'vote_count', 'vote_average']:
fig = px.scatter(data_frame = top100, x = x, y = 'revenue', hover_name = 'title', size = 'revenue', color = 'revenue'
, color_continuous_scale = px.colors.sequential.Emrld, width = 700, height = 600, trendline = 'ols', trendline_color_override='green')
fig.show()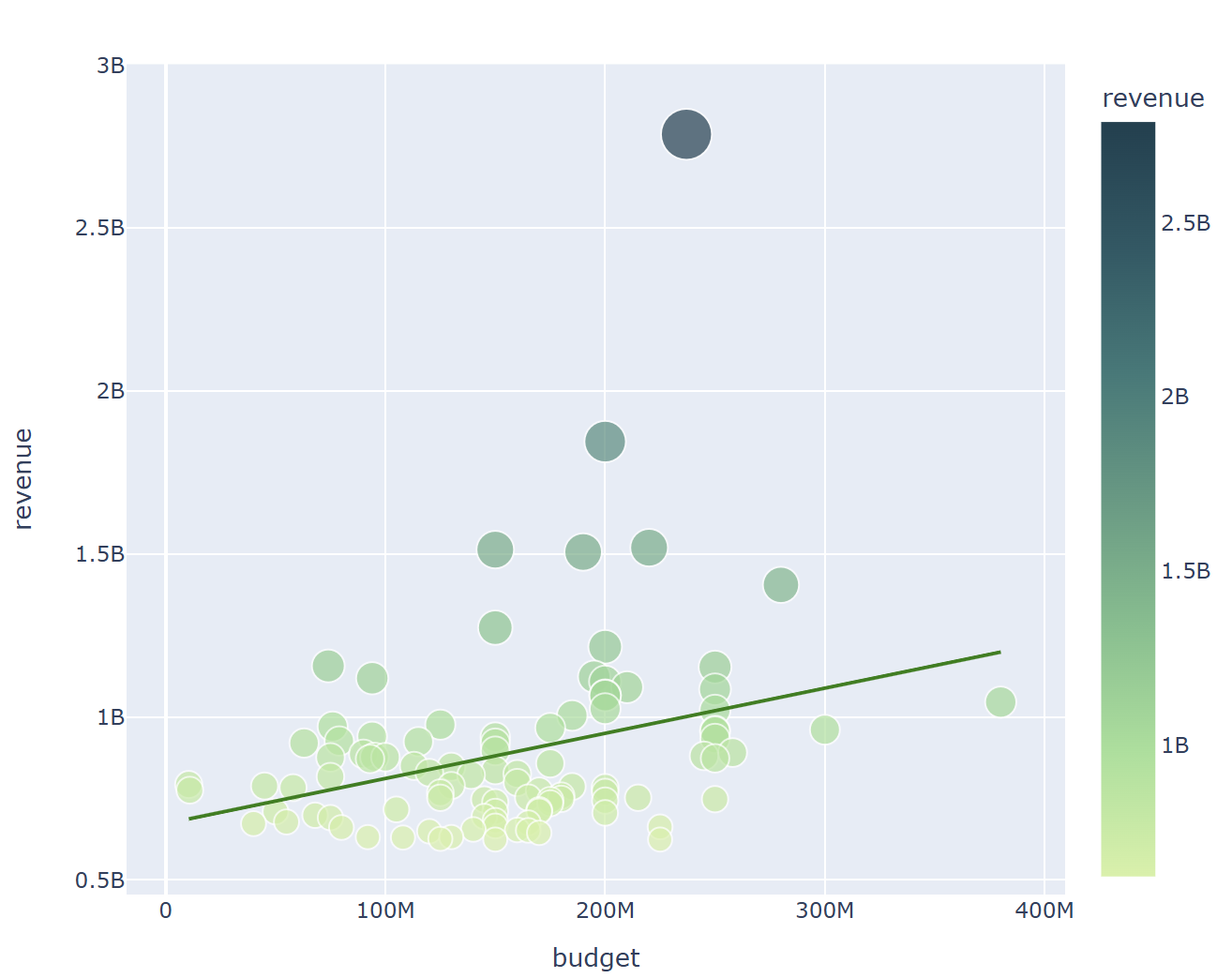
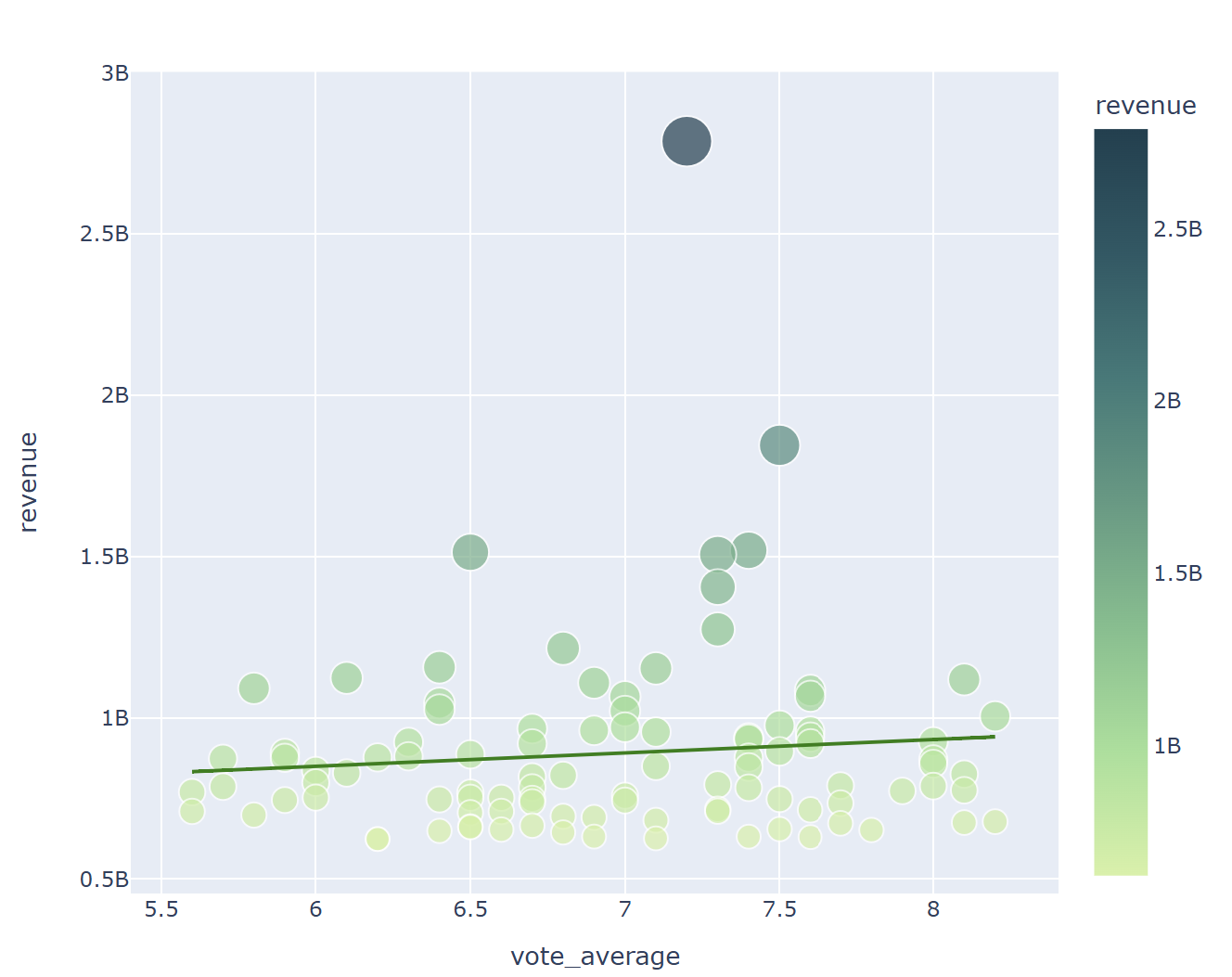
예산과 투표수는 흥행 수익과 높은 양의 상관관계를 보이나, 평점 평균은 비교적 낮은 양의 상관관계를 볼 수 있다
흥행에 성공한 상위 100개로만 확인 했을때는, 그 상관관계가 더 낮아진다
ROI가 높으면서 흥행에 성공한 영화의 특징
top300 = data.sort_values('revenue', ascending=False).head(300)
fig = px.box(data_frame = top300, y = 'main_genre', x = 'roi', hover_name = 'title')
fig.show()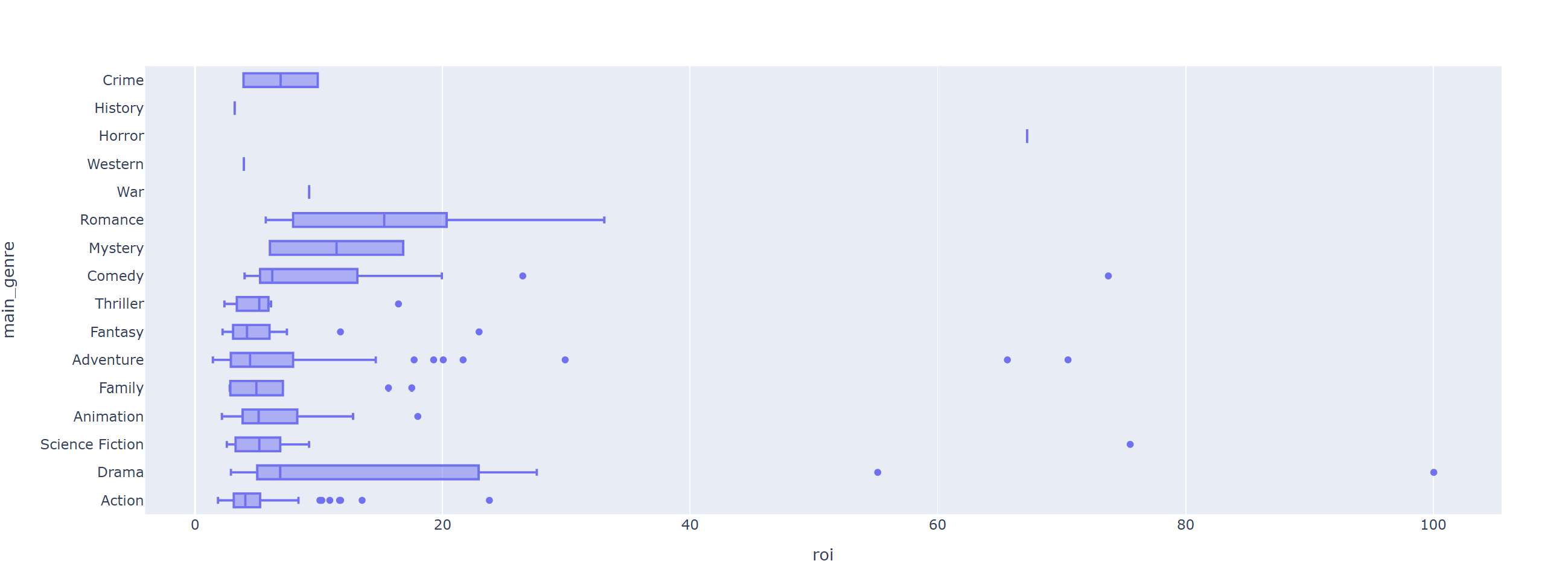
액션의 경우 예산이 큰 영화가 많아 ROI가 높은 편은 아니고, 드라마/코미디/로맨스 영화가 ROI가 큰 영화들이 많다
