.png)
Deep-learning 신경망 모델에서 각 Layer 간 중요 특성들을 반영하여 다음 레이어에 전달한다. 뉴럴 네트워크에서 층을 쌓는다는 의미는 비선형 함수를 활성화 함수(Activation Function)로 사용함으로써, 딥러닝 네트워크의 레이어 층(hidden layer)을 깊게 가져갈 수 있다.
선형함수인 h(x)=cx를 활성화함수로 사용한 3층 네트워크를 떠올려 보세요.
이를 식으로 나타내면 y(x)=h(h(h(x)))가 됩니다. 이는 실은 y(x)=ax와 똑같은 식입니다. a=c3이라고만 하면 끝이죠. 즉, 은닉층이 없는 네트워크로 표현할 수 있습니다. 뉴럴네트워크에서 층을 쌓는 혜택을 얻고 싶다면 활성화함수로는 반드시 비선형 함수를 사용해야 합니다. - '밑바닥부터 시작하는 딥러닝'
쉽게 생각해서, 모든 데이터들이 선형적으로 분포하여 XOR 문제를 모두 풀 수 있다면 비선형함수를 떠올릴 필요가 없다. Activation Function 개념도 필요 없다고 볼 수 있다. 그러나 비정형 데이터들의 특성들을 축출해서 활용하려면 비선형 함수가 필요하고 Sigmoid, tanh, ReLU, LeakyReLU, Maxout, ELU 등등이 활성화함수로 많이 사용된다.
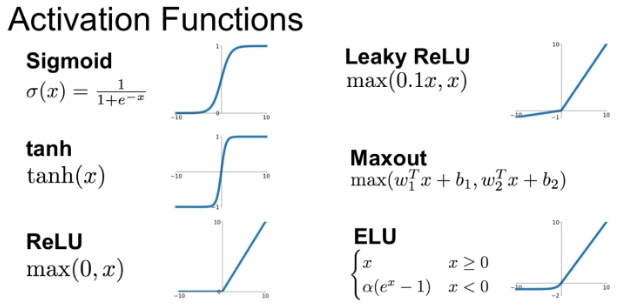
그런데 그 중에서도 GELU(Gaussian Error Linear Unit) 활성화함수에 대해 알아보자.
GELU는 NLP 분야에서의 BERT, ROBERTa, ALBERT 등 최신 딥러닝 모델에서 굉장히 많이 사용되고 있고, 특히 Computer Vision 분야에서 CNN 모델은 지금껏 de-facto standard 였으나 최근 self-attention 기반의 Vision Transformer(ViT)가 SOTA 퍼포먼스를 달성하면서 BERT, GPT-3에서 활용되고, 특히 2021년 5월초에 Google Research에서 발표한 MLP-Mixer 모델에서는 ViT의 self-attention 이 아닌 MLP(Multilayer Perceptron)만 사용해서 SOTA 까지는 아니지만 비교 해볼만한 성능이 나왔다.
(필자는 이번 MLP-Mixer 모델이 computer vision 분야에서 시사하는 바가 크다고 생각한다. 물론 JFT-300M pretrained 해야 성능이 높아진다만 매우 흥미로웠다. 곧 MLP-Mixer와 관련된 내용을 velog 에 올리려야겠다.)
이 모든 최신 모델에서 모두 활성화함수로 GELU가 사용되고 있고, 해당 활성화 함수는 무엇일까?
## Google Bert
def gelu(x):
"""Gaussian Error Linear Unit.
This is a smoother version of the RELU.
Original paper: https://arxiv.org/abs/1606.08415
Args:
x: float Tensor to perform activation.
Returns:
`x` with the GELU activation applied.
"""
cdf = 0.5 * (1.0 + tf.tanh(
(np.sqrt(2 / np.pi) * (x + 0.044715 * tf.pow(x, 3)))))
return x * cdf
## OpenAI GPT-2
def gelu(x):
return 0.5*x*(1+tf.tanh(np.sqrt(2/np.pi)*(x+0.044715*tf.pow(x, 3))))이런 형태이다.
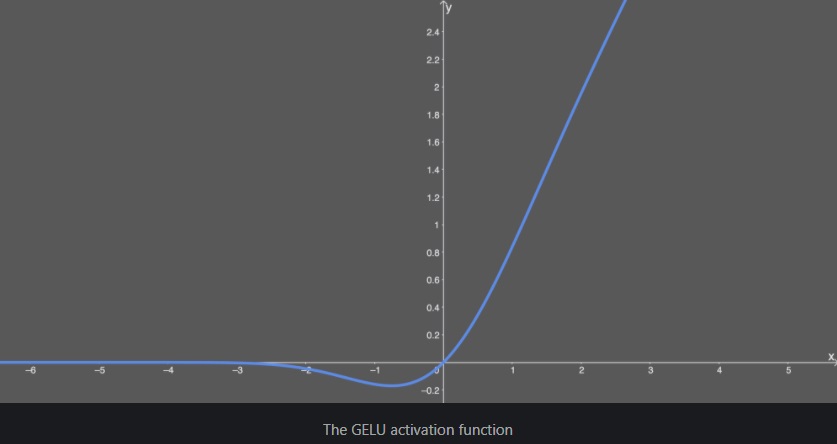
초기 신경망에서는 이진법 단위를 활용해서 Sigmoid 함수에 의해 평준화 되었으나, 네트워크가 깊어짐에 따라 입력 부호에 기초한 게이트를 결정되는 특징 때문에 RELU가 인기 있는 활성화함수가 되었다.
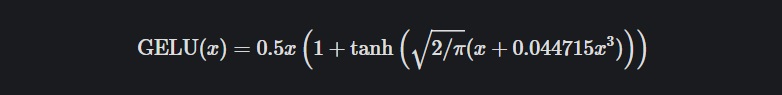
이후 Hendrycks and Gimpel에 의해 GELU가 제안되었는데, 네트워크가 깊어질수록 adaptive dropout 형태로, 입력치에 가중치를 부여하여 zoneout 되는 형태로 보여진다.
마치 더 깔끔한 RELU가 GELU랄까..?
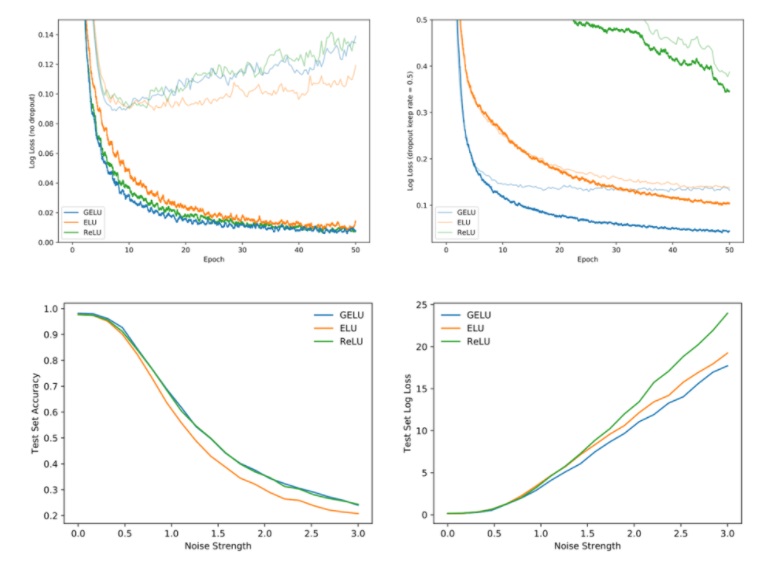
여러 결과들을 보면 GELU가 RELU, ELU 등의 타 활성화 함수들보다 빠르게 수렴, 낮은 오차를 보여준다.
최신 논문에서도 GELU를 사용하는 것 보면, 당분간은 활성화함수로 GELU를 사용하겠다.
