2021.5.4일 Google Research 에서 MLP-Mixer: An all-MLP Architecture for Vision 이라는 이름으로 Paper 가 나왔다.
arXiv link : https://arxiv.org/abs/2105.01601
지금까지 Deep-learning 이라 하면 CNN의 convolutional network 가 기본이 되었고, 최근 ViT(Vision Transformer)의 self-attention 방식의 convolutional 한 부분이 제거가 되어도 충분한 성능이 나온다는 결과가 나오면서 인기가 많다. BERT, GPT-3 등 NLP 영역에서 ViT 가 적용된 최신 레포들이 쏟아져나오고 있는 시점에서 Image Processing 에서도 ViT 를 적용한 논문들이 나오고 있고 이번에 소개할 MLP-Mixer 모델에서 attention 필요 없이 다층 퍼셉트론 MLP(Multi Layer Perceptron) 만으로도 SOTA에 가까운 성능이 나온다는 결과가 나왔다.
Paper 리뷰에 들어가기 전 한 가지 짚고 가면,
CNN 모델을 보면 Convolution layer 를 형성하나, ViT와 본 MLP-Mixer 는 fully connected layer 를 형성하는데 이 차이는 layer 간 곱해지는 가중치 값이 공유되어지냐의 차이이다. 즉, Convolution layer 는 Weight가 공유되어 locally 한 특성을 보이고 fully- connected layer(Dense Layer) 는 독립적인 Weight 특성에 따라 Global한 특성을 보인다.
그럼 본 Paper를 요약하면,
두 가지 타입의 Layer
1. token-mixing MLP (across patches (i.e. "mixing" spatial information))
2. channel-mixing MLP (independently to image patches (i.e. "mixing" the per-location features))
의 두 가지 타입의 레이어 층들로 구현이 되어있다.
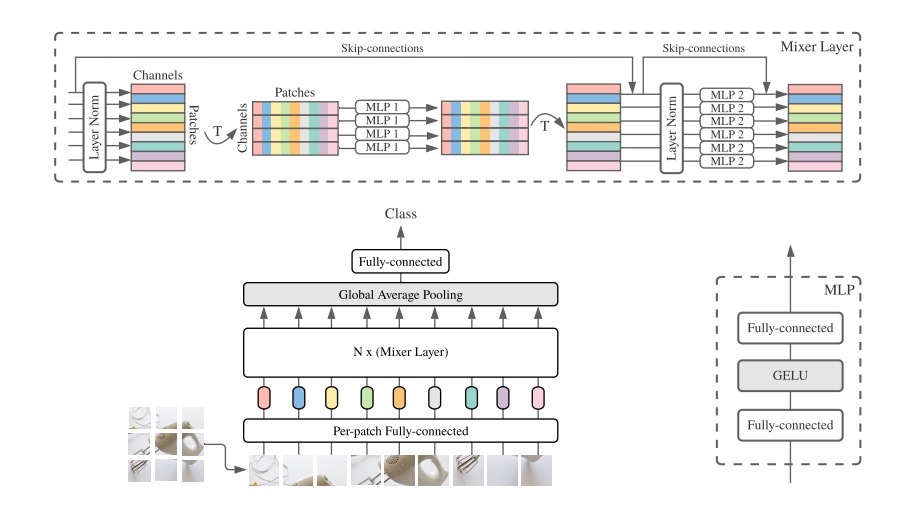
위의 아키텍쳐를 보면 MLP-Mixer 는 per-patch linear embeddings 과정을 거치고 각 patch 별로 Mixer Layer 에 들어간다.(여기서 Mixer Layer 는 2개의 동일 MLP 모델로 학습된다) 그리고 Classifier 가 존재하게 되는데, Mixer 레이어들은 위에 언급한 하나의 token-mixing MLP 와 하나의 channel-mixing MLP 로 구성되어있고 2개의 fully-conneted layers 들과 비선형 활성화함수인 GELU가 적용된다.
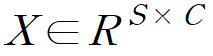

2차원 입력인 patch의 개수(S)와 해당 패치의 벡터 길이(C:hidden dimension)으로 input 이 설정되고 token-mixing MLP block 은 X의 행 특성끼리 공유되고, channel-mixing MLP block 은 X의 열 특성끼리 공유된다. 이는 위와 같은 식으로 연산이 이루어진다.
(시그마는 GELU 활성화함수이다)
NLP 에서 단어들별로, 토큰별로 임베딩해서 벡터화하는 작업을 하듯, 이미지도 패치별로 짤라서 작업할 수 있지 않을까 하는 발상에서 나왔고, 그러다 보니 position-embedding 이 필요하다고 생각할 수 있다. 그러나 ViT 모델에서는 postion-embedding 이 필요한 반면, MLP-Mixer 에서는 position-embedding 이 필요없다. 그 이유는 token mixing 을 할 때 이미지 패치별 특성 위치 그대로 layer 계층에 입력되기 때문에 위치 정보가 반영되기 때문이다.
전체적으로 보면, 복잡도 면에서도 ViT 모델은 quadratic 한 것에 비해 Mixer 모델은 input patch 수에 따라 계산 복잡도가 결정되기 때문에 linear 하다고 한다. 그 외 구체적인 내용들은 논문을 참고하면 좋을 것 같다.
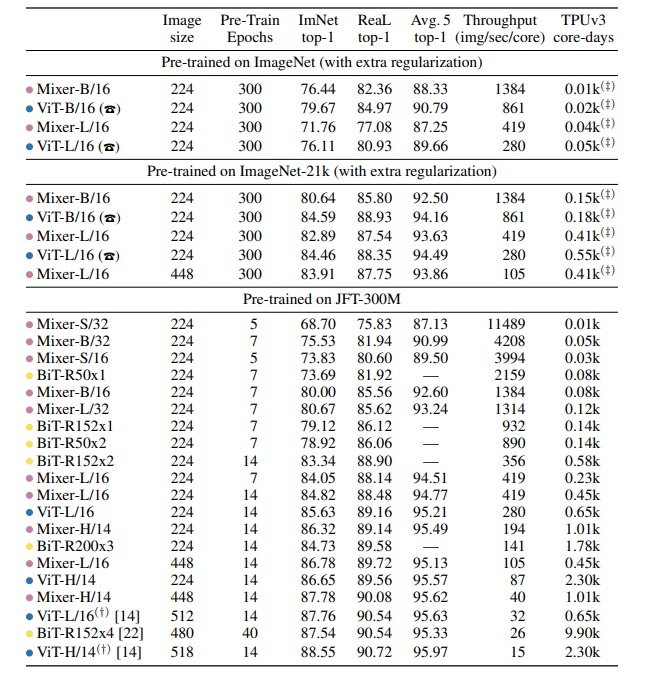
MLP-Mixer 모델의 퍼포먼스는 데이터셋 스케일별로 pre-trained 진행했으며 세 가지 부분에서 성능을 측정했다고 한다.
- 다운스트림 작업에 대한 정확도
- pre-trained 할 때 소요된 계산 비용
- 추론할 때의 처리량
여기에서 목표는 SOTA 결과를 증명하는 것이 아닌, 간단한 MLP 기반의 모델이 CNN, ViT 모델과 견줄만하다는 것을 보여주는 것이라고 한다.
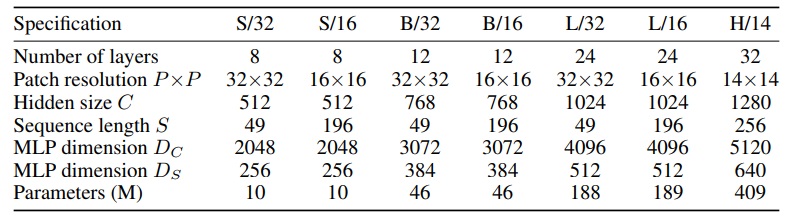
larger scale 에서 높은 퍼포먼스에 도달하기 위해 JFT-300M 데이터셋을 중복 학습시켰다고 한다. (JFT-300M 을 pre-trained 해야만 가능한건가 싶다는 생각이 들었다. ViT 모델도 inductive bias 가 적은 대신 거대한 양의 데이터셋이 필요하듯 MLP-Mixer 또한 그러한 맥락이 아닐까 하는 생각이 들었다.)
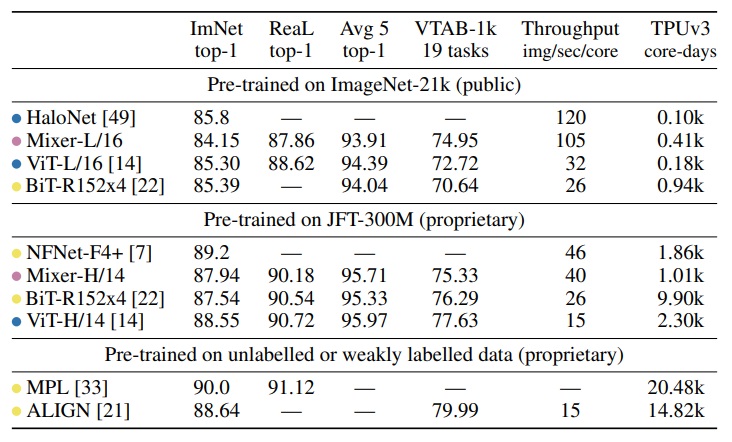
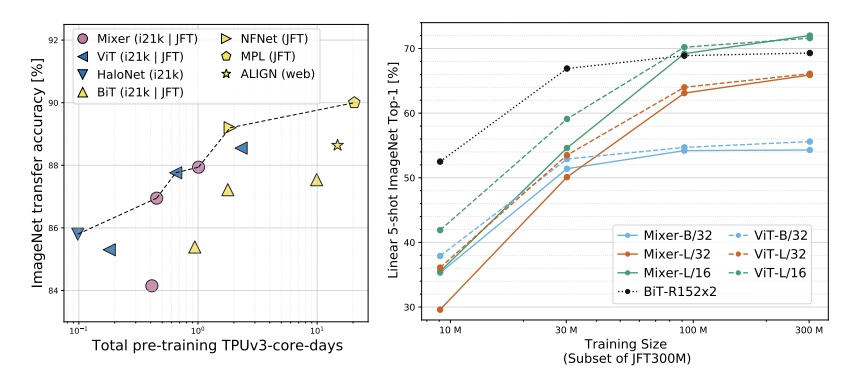
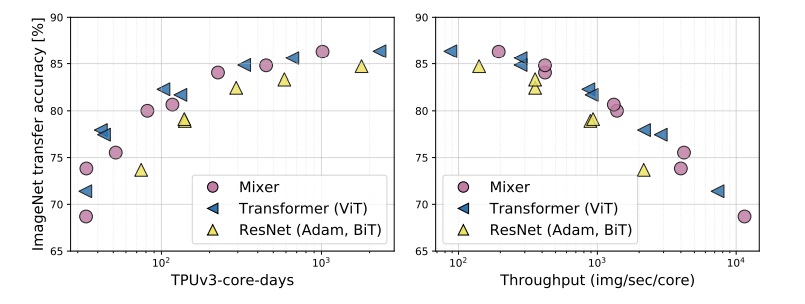
pink 점은 MLP-based Mixer model, yellow 점은 convolution-based model, blue 점은 attention-based model 이다.
보면 알겠지만, pre-trained JFT-300M 이 되어야 비교적 높은 퍼포먼스를 보인다.
밑의 그래프들은 SOTA 모델들 과의 비교 분석 결과이다.
이렇듯, MLP-Mixer 는 Convolutional layer 도 필요 없고, attention 도 필요 없고 오직 MLP 만으로 딥러닝 네트워크를 구성할 수 있다를 보여준, 흥미로운 Paper라 생각된다.
그런데 문득 이런 생각이 든다.
token-mixing 은 stride 를 갖는 Convolutional layer 아닌가?
이 부분에 대해 조금 더 공부해봐야겠다.

와 멋져요...!!!