
요점만 간단히.
- 3장 내용은 챕터 내내 어셈블리 코드를 읽는 연습을 한다는 생각을 해도 무방하겠다.
- 어셈블리 코드와 같은 저수준 언어의 수준에서 하드웨어에 대한 이해와 함께 코드를 읽는 연습을 해본다.
- 어셈블리 코드를 C언어로 역 엔지니어링 해보면서, 우리가 작성하는 고급 언어가 기계어 인스트럭션 수준에서는 어떤 식으로 움직이는지 이해해본다.
이번 글은 CS:APP 책의 3장 내용을 읽으며 필자가 원하는대로 내용을 뽑아 재구성 해 작성하였다.
I. 이번 3장에서는
-
1장에서는 hello.c 프로그램을 예시로 들어서, 고급 수준의 언어가 어떤 단계를 거쳐 기계어 인스트럭션으로 번역되는지 살펴보았다.
-
다음은 hello.c를 어셈블리언어 수준으로 번역한 코드이다.
hello.s
1 main:
2 subq $8, %rsp
3 movl $.LCO, %edi
4 call puts
5 movl $0, %eax
6 addq $8, %rsp
7 ret- 이전의 1장에서는 위의 코드를 보고 어떤 내용인지 제대로 이해할 수 없었을 것이다. 이번 3장에서는 어셈블리 코드에 대해 이해하면서, 위와 같은 코드를 읽고 이해할 수 있게 된다.
II. 먼저 알아야 할 것
- 책에서 다루는 어셈블리 코드는 ATT 형식 (GMU Assembler에서 사용하는/ 리눅스 환경에서 주로 이용)기준이며, 어셈블리 코드는 컴파일러마다 다를 수 있다.
어셈블리 코드에 대한 문법을 외운다는 느낌 보다는, 저수준의 어셈블리 코드에서는 이런 식으로 데이터가 돌아가고, 하드웨어가 작동한다는 개념을 이해하자.
- 레지스터의 구성
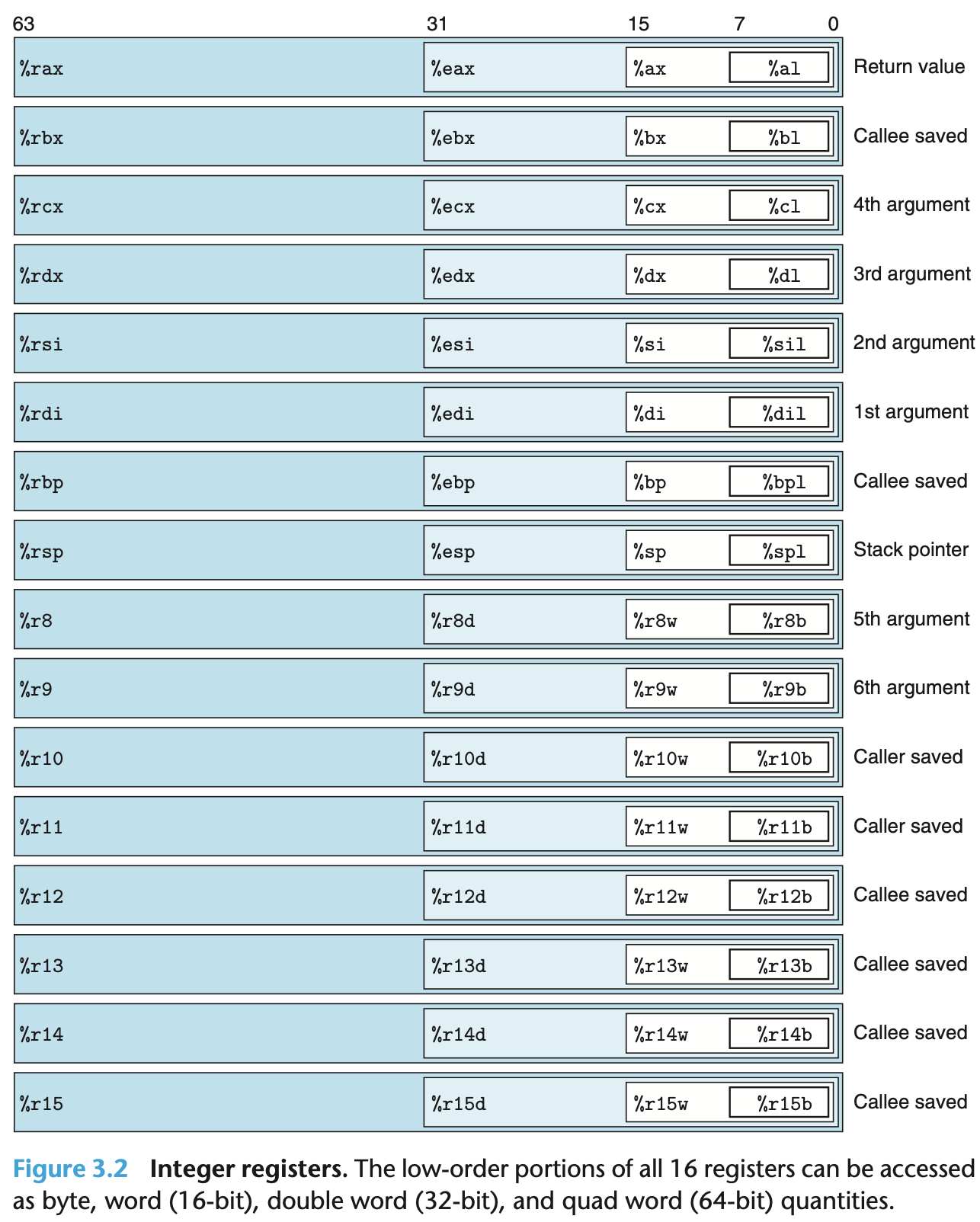
-
처음에는 16-bit 크기였던 레지스터가 기술적으로 진화하면서, 32-bit, 64-bit 크기를 가지며 위와 같이 확장되었다.
-
인스트럭션들은 16개 레지스터의 하위 바이트들에 저장된 다양한 크기의 데이터에 대해 연산할 수 있다.
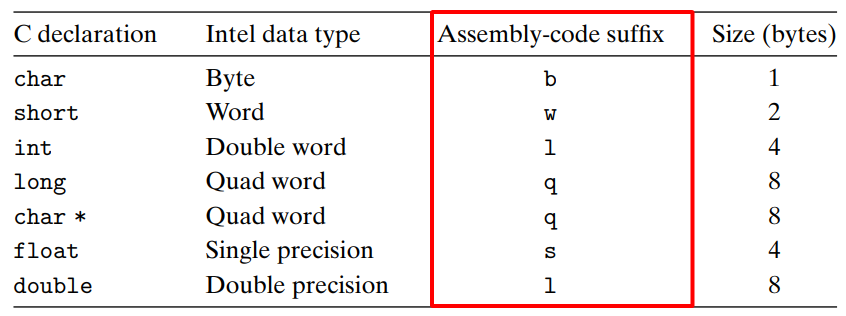
- 각 자료형에 대한 크기와 어셈블리 접미사 명명법
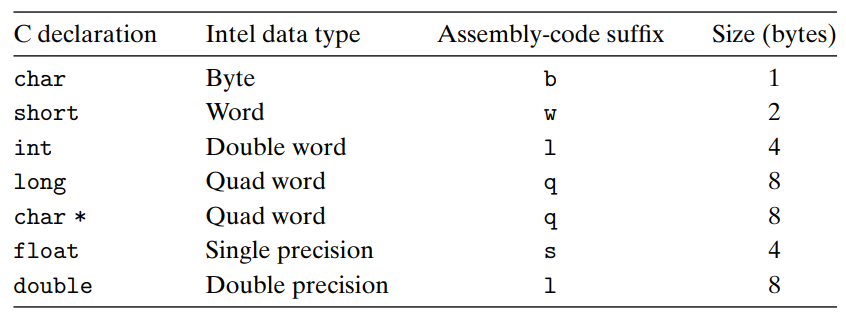
-
고급언어에서는 사이즈에 대한 부분을 어느 정도 생각 않고 작성할 수 있었다. 책에서 설명하는 저수준의 어셈블리 코드에서는 자료형마다 사이즈의 개념을 명시한다.
-
인텔 프로세서들은 근본적으로 16비트를 사용하다 32비트로 확장했기 때문에, '워드'라는 단어를 16비트 (=2바이트) 데이터 타입을 말할 때 사용한다고 한다.
워드 = 16비트 (=2바이트),
더블워드 = 32비트 (=4바이트),
쿼드워드 = 64비트 (=8바이트)
- 결국 연산은 CPU에서 한다.
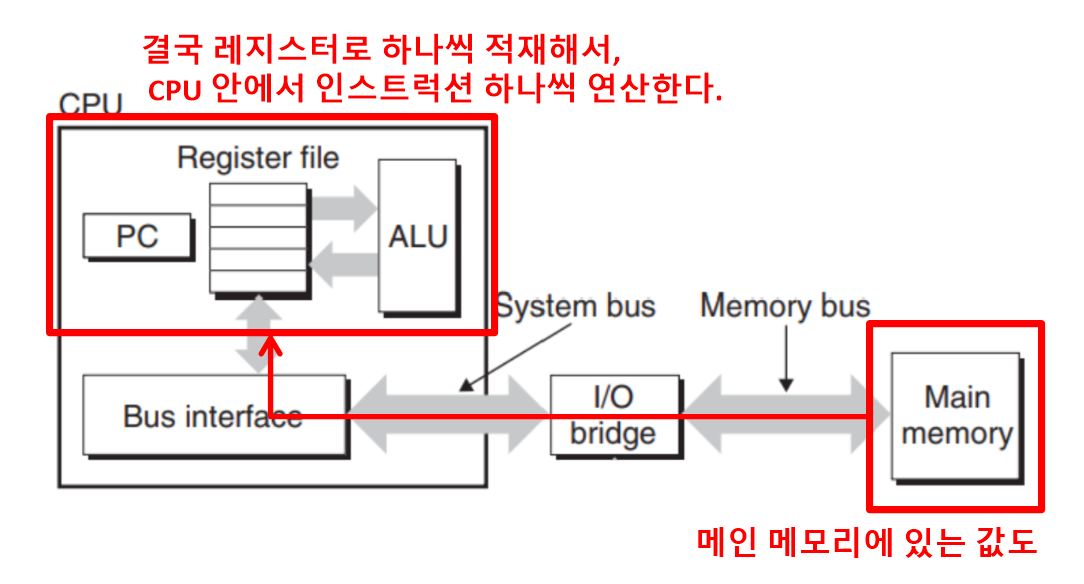
- 고급 언어 수준에서 코드를 작성하다보면 변수든 뭐든 자꾸 메인 메모리에서 생각하는 습관이 생긴다.
결국 어떤 값이든 레지스터에 가장 작은 단위로 적재가 되어야 CPU 안에서 ALU를 거치면서 인스트럭션 하나, 하나를 연산할 수 있다. 이에 대한 이해가 중요하다.
III. 오퍼랜드 (Operand)
I의 hello.s를 다시 살펴보자.
2 subq $8, %rsp
3 movl $.LCO, %edi아직 정확한 뜻까지는 몰라도, subq 연산, movl 연산을 하는데 오른쪽에 쉼표로 구분되어 적혀있는 부분들이 있다.
$8, %rsp
$.LCO, %edi이 부분들이 바로 오퍼랜드다.
오퍼랜드는 어떤 연산이 수행될 때 출발점(source)과 목적지(destination)를 명시해주는 역할을 한다.
-
오퍼랜드에는 크게 Immediate (상수), Register (레지스터 값), Memory(메모리 참조)의 세 가지 종류가 있다.
-
이해를 돕기 위한 연습문제 3.1 일부
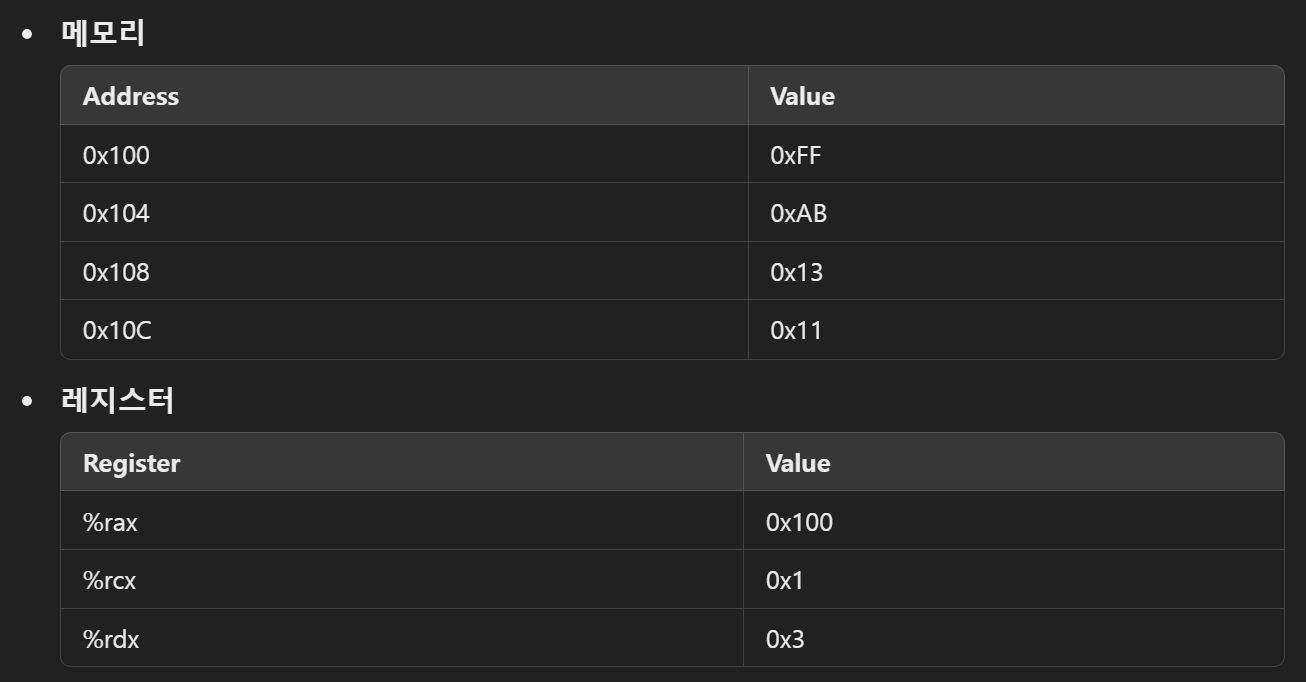
-
위와 같은 테이블이 주어졌다고 하자. 우선 다음 그림과 같은 상황으로 이해할 수 있다.
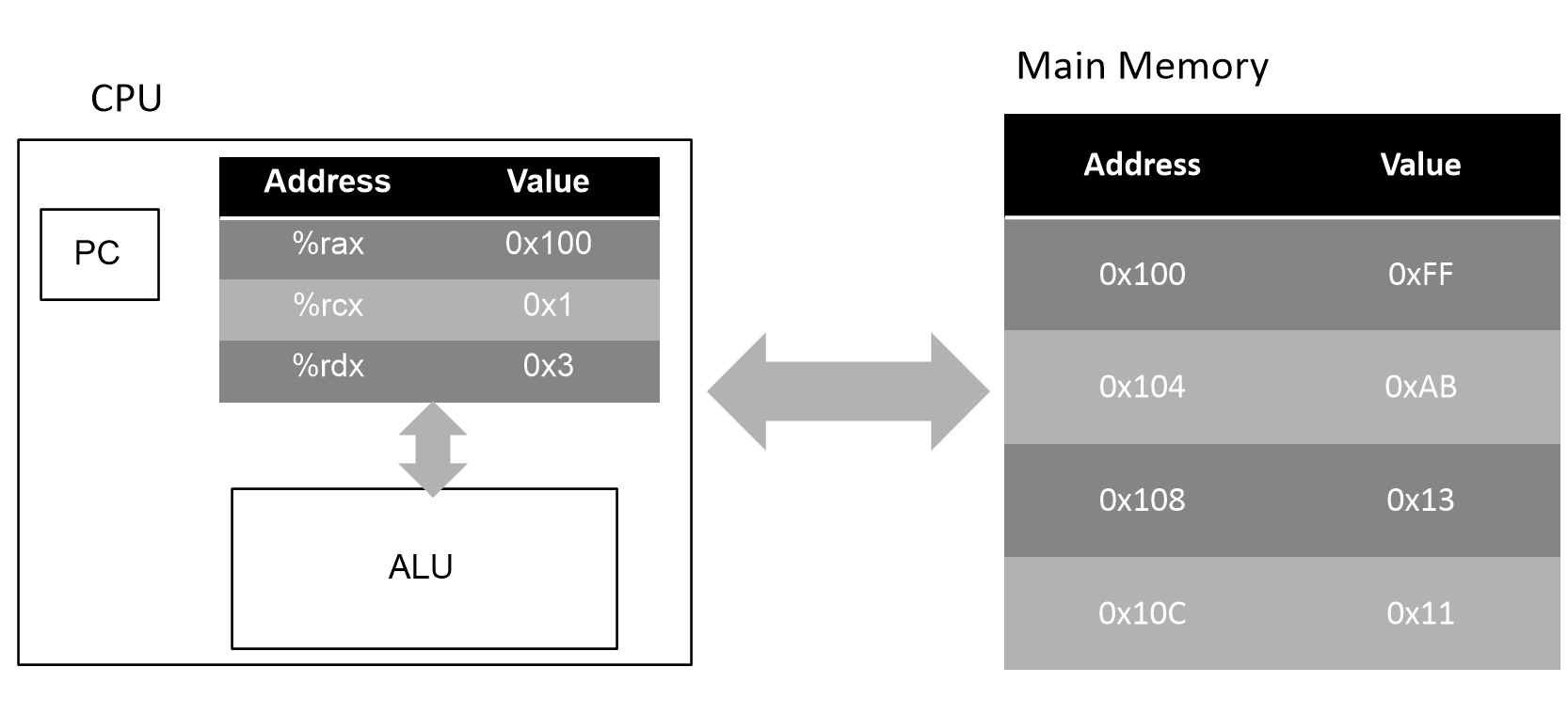
-
%rax = 0x100
- %rax는 레지스터 rax에 있는 Value를 참조한다는 뜻으로, 표에서 0x100을 직관적으로 확인할 수 있다.
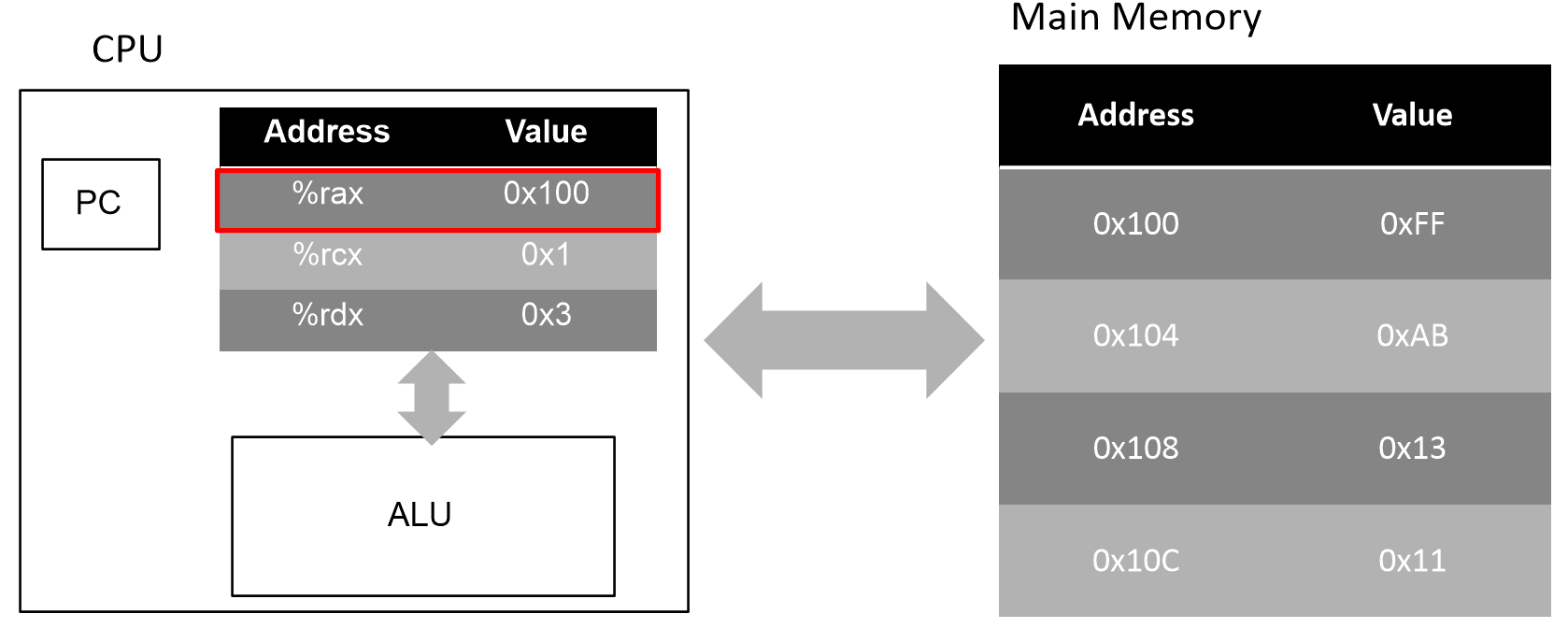
- %rax는 레지스터 rax에 있는 Value를 참조한다는 뜻으로, 표에서 0x100을 직관적으로 확인할 수 있다.
-
$0x108 = 0x108
- $를 앞에 붙여 상수(immediate)를 표시한다. 따라서, $0x108은 0x108 과 같다.
-
(%rax) = 0xFF
- ( )를 붙여 메모리 참조를 표시한다. %rax 안에는 0x100이라는 value가 있고, 이 값을 가지고 메인 메모리의 0x100번지를 참조한다. 메인 메모리의 0x100번지에는 0xFF라는 value가 있다.
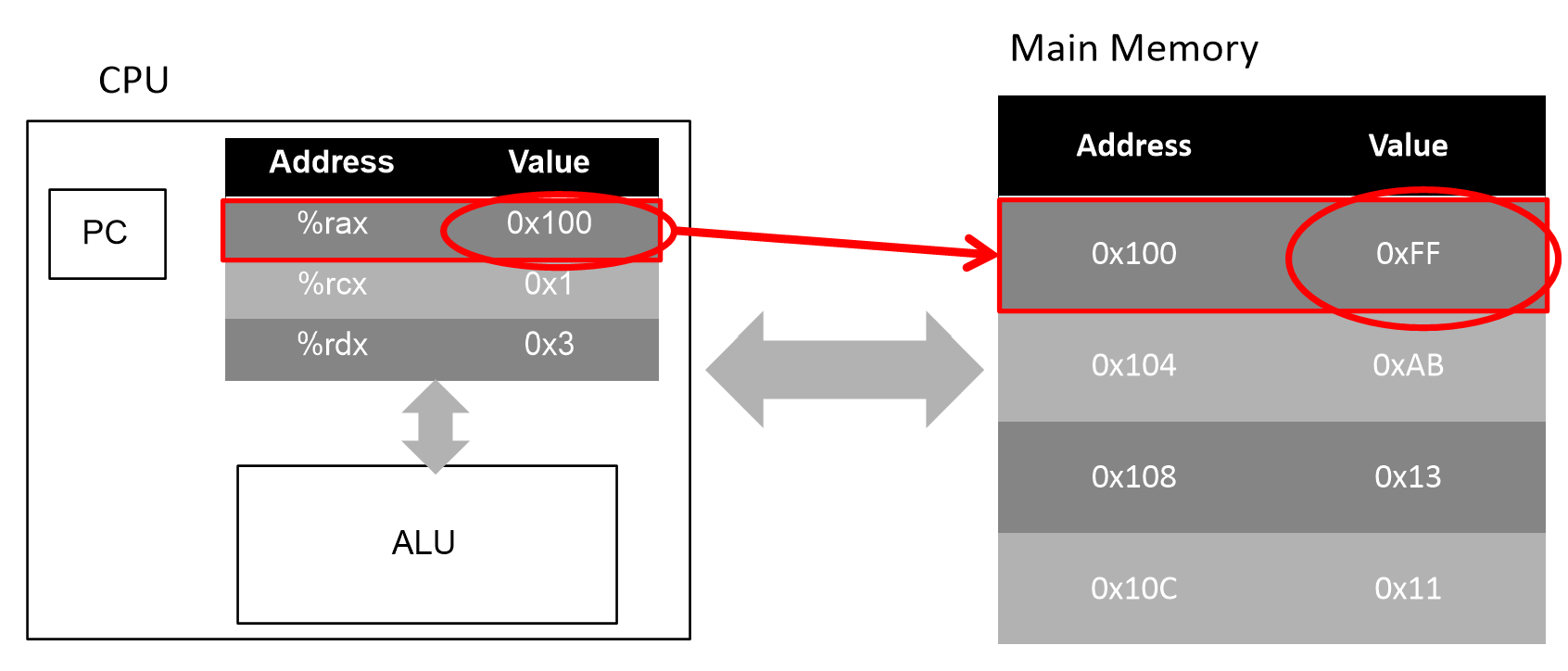
- ( )를 붙여 메모리 참조를 표시한다. %rax 안에는 0x100이라는 value가 있고, 이 값을 가지고 메인 메모리의 0x100번지를 참조한다. 메인 메모리의 0x100번지에는 0xFF라는 value가 있다.
-
(%rax, %rdx, 4)
-
오퍼랜드를 통해 메모리를 참조할 때, 위와 같이 ( ) 안에 세 가지의 값이 전달 될 수 있다. 이런 경우 다음과 같이 연산한다.
( %rax + (%rdx * 4) )
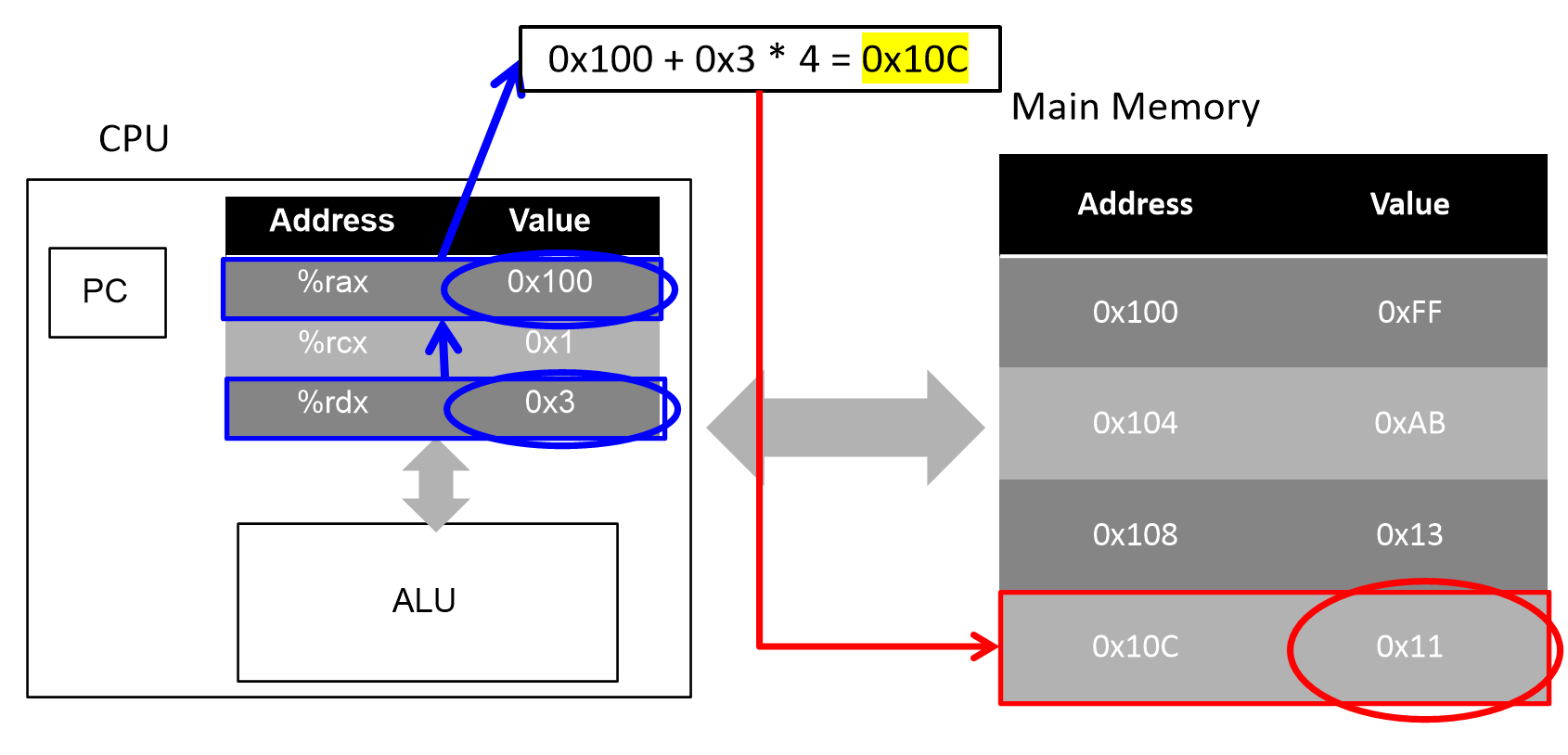
-
%rax = 0x100, %rdx = 0x3 이므로
0x100 + (0x3 * 4) = 0x10C (16진수 연산이므로)
이다. 메인 메모리 0x10C번지에는 0x11이 있으므로, 참조값은 0x11이 된다. -
메모리를 참조할 때는 이런 식으로 연산을 해서 참조하는 경우가 일반적이다.
(보통, 배열을 이용해 값을 참조할 때를 생각하면 쉽겠다.
배열의 이름 + 인덱스 * 데이터 타입의 크기로 연관지어 생각하면 머리에 금방 들어올 것이다.)
-
위와 같은 방식으로 어셈블리 언어에서는 어떤 연산을 수행할 때 오퍼랜드를 통해 연산의 출발지, 도착지를 명시한다는 것을 이해하고 넘어가면 된다.
-
혹시나 16진수 계산이 익숙치않거나 이해가 잘 되지 않는 분들을 위한 16진수에 대한 설명은 아래 포스팅으로 대체하겠다.
-
한 가지 주의 할 점은, 출발지와 도착지에 모두 메모리 참조 ( ) 형식으로 올 수는 없다. ex) movl (%rax),(%rdx)
-
위에서 설명했듯, 결국 연산은 CPU에서 인스트럭션 단위로 수행 되기 때문에, 컴퓨터는 메모리 → 메모리로 데이터를 바로 넘길 수 없다.
-
메모리 → 레지스터 → 메모리와 같은 순서로 데이터를 이동할 수 있겠다.
IV. mov 연산에 대해
IV - 1. MOV 연산
-
책이 어렵게 적어두었다고 해서 어렵게 이해할 필요는 없다.
아래와 같은 어셈블리 코드 구문이 있다고 하자.movl $0x4050, %eax
-
우리는 오퍼랜드의 개념을 배웠으니, 이제 이해할 수 있다.
위의 연산은 $0x4050 이라는 상수를 %eax 레지스터에 옮겨달라는 뜻일 것이다. -
그렇다면, mov 뒤의 'l'이 의미하는 것은 무엇일까?
이것은 '옮겨지는 데이터의 크기'를 나타낸다. II-2에서 봤던 표를 다시 보자.
-
오퍼랜드를 확인하고, 출발지와 도착지의 레지스터 사이즈를 확인하고, 옮겨지는 데이터의 크기에 따라 위의 어셈블리 코드 접미사를 알맞게 작성해주면 된다.
위의 코드에서 %eax는 32-bit (=4bytes) 레지스터이므로, 접미사 l을 붙여 movl이 된다.
IV - 2. MOVZ와 MOVS 연산
- 앞에서 레지스터의 구조와 오퍼랜드, mov 연산까지 훑어보았으니, 우리는 다음과 같은 의문점을 가질 수 있다.
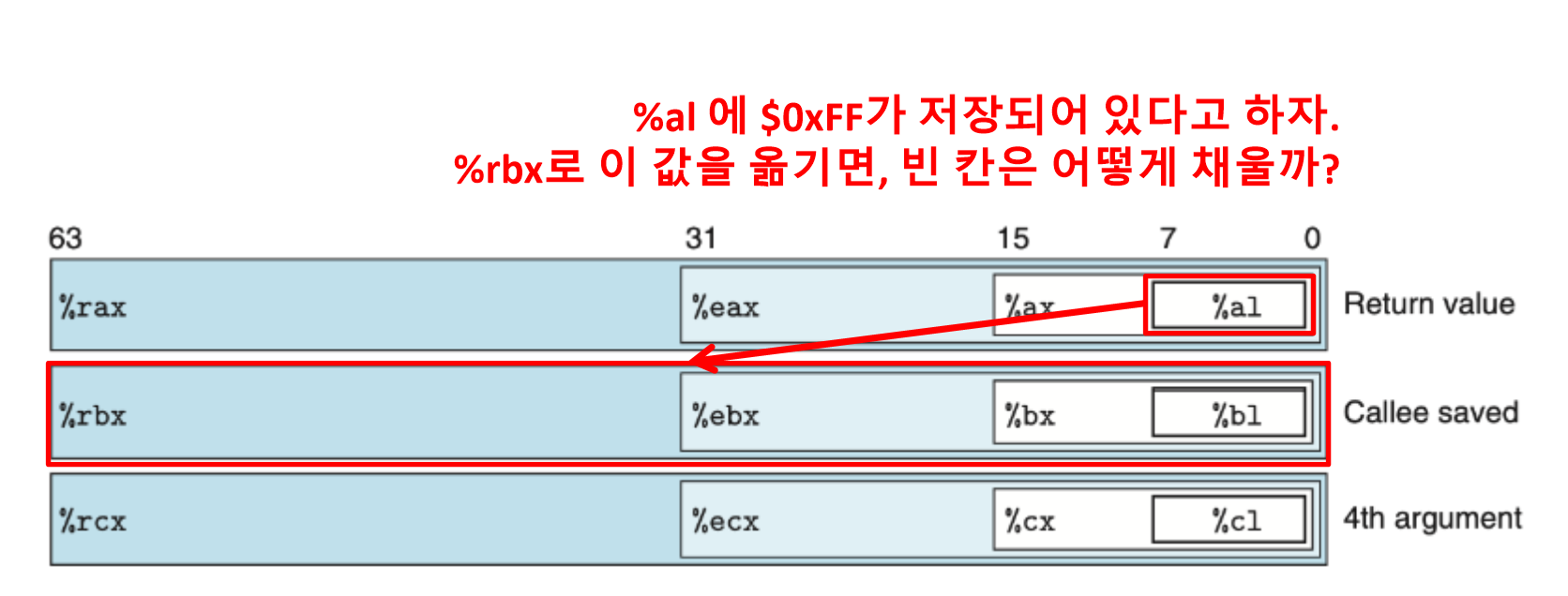
"더 작은 레지스터에 있는 값을 더 큰 레지스터에 옮기면, 빈 칸을 어떻게 채울까?"
- 예를 들어, %rbx에 $0x0011223344556677 이라는 값이 할당되어 있다고 하자.
- %al에 들어있는 $0xFF를 %rbx로 mov 할 것이다.
이 때 사용할 수 있는 mov 연산이 두 가지가 있다.
IV - 2 - 1. MOVZ 연산
- MOVZ에서 Z는 Zero-extension을 나타낸다.
movzbq %al, %rbx
- 위와 같이 movz 뒤에 b = 출발지 데이터의 크기, q = 도착지의 데이터 크기를 명시해주면, 도착지의 남은 바이트들을 0으로 채워준다.
%rbx의 값은 아래와 같이 될 것이다.%rbx = 0x00000000000000FF
IV - 2 - 2. MOVS 연산
- MOVS에서 S는 Sign-extension을 나타낸다.
movsbq %al, %rbx
- 위와 같이 movs 뒤에 b = 출발지의 데이터 크기, q = 도착지의 데이터 크기를 명시해주면, 도착지의 남은 바이트들을 출발지의 가장 중요한 비트를 반복해서 복사해 채운다.
%rbx의 값은 아래와 같이 될 것이다.%rbx = 0xFFFFFFFFFFFFFFFFFF
V. C 포인터에 대한 짤막한 이해
//포인터 이해를 위한 짤막한 예제
#include <stdio.h>
int main() {
long x = 100; //정수 x = 100으로 선언
long* xp = &x; //x의 주소를 포인터 xp에 할당
printf("정수 x 출력: %ld\n", x); // 정수 x 출력
printf("포인터 xp 출력: %p\n", xp); // 포인터 xp의 값(x의 주소) 출력
printf("포인터 xp 역참조: %ld\n", *xp); // xp를 통해 정수x를 역참조
return 0;
}
- 정수형 변수 x를 선언하고, 이에 100을 할당한다.
- 정수형 변수 포인터 xp를 선언하고, 이에 변수 x의 주소를 할당한다. (&x와 같이 &를 이용하면 변수 x의 주소를 가져오겠다는 뜻이 된다.)
- ' * ' 기호는 포인터를 선언할 때는 마치 자료형처럼 포인터를 명시하는 뜻이 되지만,
선언 후에 사용할 때는 이 주솟값을 통해 value를 역참조 하겠다는 뜻이 된다.
// xp를 통해 정수x를 역참조
printf("포인터 xp 역참조: %ld\n", *xp); - 실행 결과
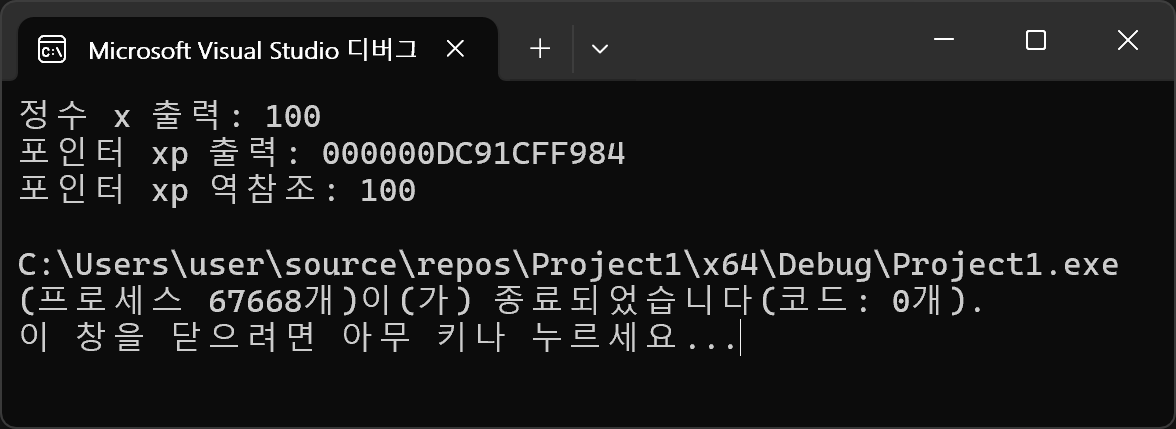
- 위의 실행결과를 보면 어느 정도 감을 잡을 수 있을 것이다.
이 정도의 개념만 알고있어도 책의 내용을 이해하는데 무리는 없다.
VI. 연습문제 3.5
- 연습문제 3.5까지 풀 수 있다면 우리는 이제 어느 정도의 어셈블리 코드를 읽고, 심지어는 역 엔지니어링을 할 수 있는 것이다. 함께 살펴보도록 하자.
다음과 같은 프로토 타입을 갖는 함수
void decode1 (long *xp, long *yp, long *zp);
가 어셈블리 코드로 컴파일되어 다음의 결과를 생성하였다.
*xp는 %rdi에, yp는 %rsi에, zp는 %rdx에 할당되어 있다.decode 1: movq (%rdi), %r8 movq (%rsi), %rcx movq (%rdx), %rax movq %r8, (%rsi) movq %rcx, (%rdx) movq %rax, (%rdi) ret위의 어셈블리 코드와 동일한 효과를 갖는 decode1을 C 코드로 작성하시오.
-
우선, %r8, %rcx, %rax로 각각 xp, yp, zp가 가리키는 주소의 값들을 옮기고 있다.
이는 C에서 포인터 xp, yp, zp를 역참조해서 어떤 변수에 할당하고 있다고 볼 수 있다. -
이후, 포인터 xp, yp, zp가 가리키고 있는 주소 공간에 위의 변수들을 재할당하고 있다.
이러한 움직임들을 C 코드로 작성하면 다음과 같이 나타낼 수 있다.
void decode1 (long *xp, long *yp, long *zp)
{
long x = *xp;
long y = *yp;
long z = *zp;
*yp = x;
*zp = y;
*xp = z;
}마치며.
-
3.5의 스택 데이터 부분은 다들 이해하고 있을 것 같아 생략한다.
-
3장의 뒷 부분에는 이제 여러 수식 연산과 조건 연산, 반복 연산 등이 나온다.
우리가 컴퓨터 언어를 배울 때도 앞의 기본적인 연산들을 이해했다면 뒤의 조건문이나 반복문은 응용이라고 생각한다.
글에서 다룬 어셈블리 코드의 앞 부분에 대한 이해가 앞으로 3장 뒷 부분의 공부에 도움이 되기를 소망한다.
참고 자료 / 이미지 출처::
2 Machine-Level Representation of Programs
https://notes.valderfield.com/CSAPP/2%20Machine-Level%20Representation%20of%20Programs/
CSAPP 독서 내용 정리 3-1 ~ 3-4
https://velog.io/@dlgudwns1207/CSAPP-독서-내용-정리-23.05.01
