Hello, World!
안녕하세요. 필자는 대덕소프트웨어마이스터고등학교에서 취준중인 3학년 이재하입니다.
제 소개를 간단히 하자면 인공지능 동아리 모딥의 전 부장으로 활동했고,
ML Research를 주로 공부했습니다.
현재는 ML Research, Backend, ML Ops까지 공부하고 있습니다.
8월 26일 면접 과제로 논문 리뷰를 진행하였고,
최신 논문이기에 참고할만한 글이 하나도 없었습니다.
다른분들께 조금이라도 도움이 되었으면 좋겠습니다.
논문과 다른점이 있다면 언제든 댓글로 알려주세요!
사전지식
VideoINR 논문을 이해하기 위해서는 먼저 STVSR과 INR에 대해서 알아야합니다.
저 또한 Classification, Object Detection, Segmentation 위주로 공부했기에,
생성 모델은 처음이라 사전지식을 이해하는데 시간을 많이 사용하였습니다.
STVSR
추가 이해 자료 : https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=qbxlvnf11&logNo=221529266739
- Space-Time Video Super-Resolution
- low resolution(LR) video에서 high-resolution(HR) slow-motion video를 생성
→ 즉, 저해상도 영상을 화질을 좋게 만드는 대신 속도를 낮춘다. - STVSR의 접근법 : video-frame interpolation(VFI) task와
video super-resolution(VSR) task 2가지로 나누어서 해결
→ 해상도 부분과 프레임 부분으로 나누는 것
1. Object Detection과 같이 One-Stage와 Two-Stage 방식으로 나눌 수 있음.
2. Two-Stage의 경우 해상도와 프레임의 상관관계를 활용할 수 없다.
3. 두 network 모두 파라미터 개수가 많기 때문에 계산 비용이 많이 든다.
필자의 경우 생성 모델은 처음이라 Two-Stage의 장점을 잘 모르겠다. 댓글로 알려주세요.
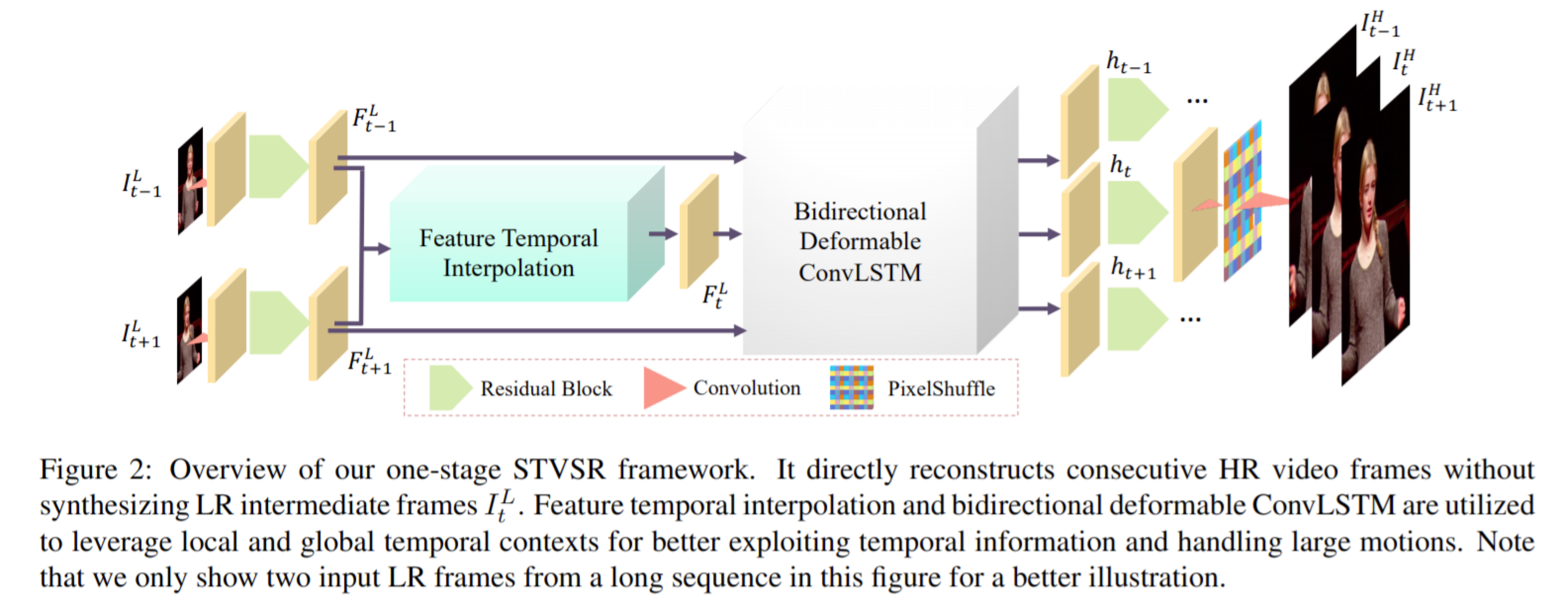
간단한 Flow
- it-1 it+1 두 프레임을 합쳐 하나의 convolution layer와 k1 residualblocks 지나 두 프레임 사이의 feature map을 만든다.
- 연속적인 feature map을 처리하기 위해 deformable ConvLSTM을 사용한다.
→ 영상의 경우 전 프레임이 현재 프레임과 미래 프레임까지 영향으르 미치므로 LSTM을 활용해 메모리에 잠깐 저장해야하기 때문에 LSTM을 사용해야 합니다. - 최종적으로, aggregate feature maps으로부터 HR slow-motion video sequence 복원
INR
추가 이해 자료
1. https://www.notion.so/Implicit-Representation-Using-Neural-Network-c6aac62e0bf044ebbe70abcdb9cc3dd1
2. https://eiric.or.kr/manpower/rising_view.php?Seq=21
- Implicit Neural Representation
- 과거에는 보통 픽셀 위치마다 RGB 값을 가지는 하나의 행렬로 표현하는게 일반적.
→ 이미지의 해상도에 따라 저장에 필요한 용량과 모델의 크기가 좌우 됨. - 이미지를 픽셀 위치인 (x, y) 좌표에서 (r, g, b) 값으로 변환해주는 하나의 함수로 표현.
- 이 함수를 신경망으로 표현해 학습하는 것이 Implicit Nerual Respresentation의 핵심.
- 이미지를 이렇게 함수로 표현하면 이미지를 해상도와 관계 없이 저장하고, 컴퓨터 비전 모델에 적용할 수 있게 됨.
- 이미지를 고화질로 변환해주는 super-resolution이 굉장히 단순해짐.
- INR은 3D 이미지일때 효율이 매우 올라감.
→ 여러가지 parameter 정보를 Neural Network에 저장할 수 있기 때문이다.
VideoINR
어떤 문제에 직면해 있는가?
- 고화질 영상을 DataBase에 저장할 경우 큰 비용적인 문제로 저화질로 저장하게 된다.
- discrete representations(범주형 데이터 방식)를 따르는 대신 STVSR 응용 프로그램과 VideoINR을 제안한다.
- VideoINR은 일반적인 up-sampling scales에서 최첨단 STVSR 방법에 비해 경쟁력 있는 모습을 보여주고, out of training distribution scales에서 이전 작업을 크게 능가하는 모습을 보인다.

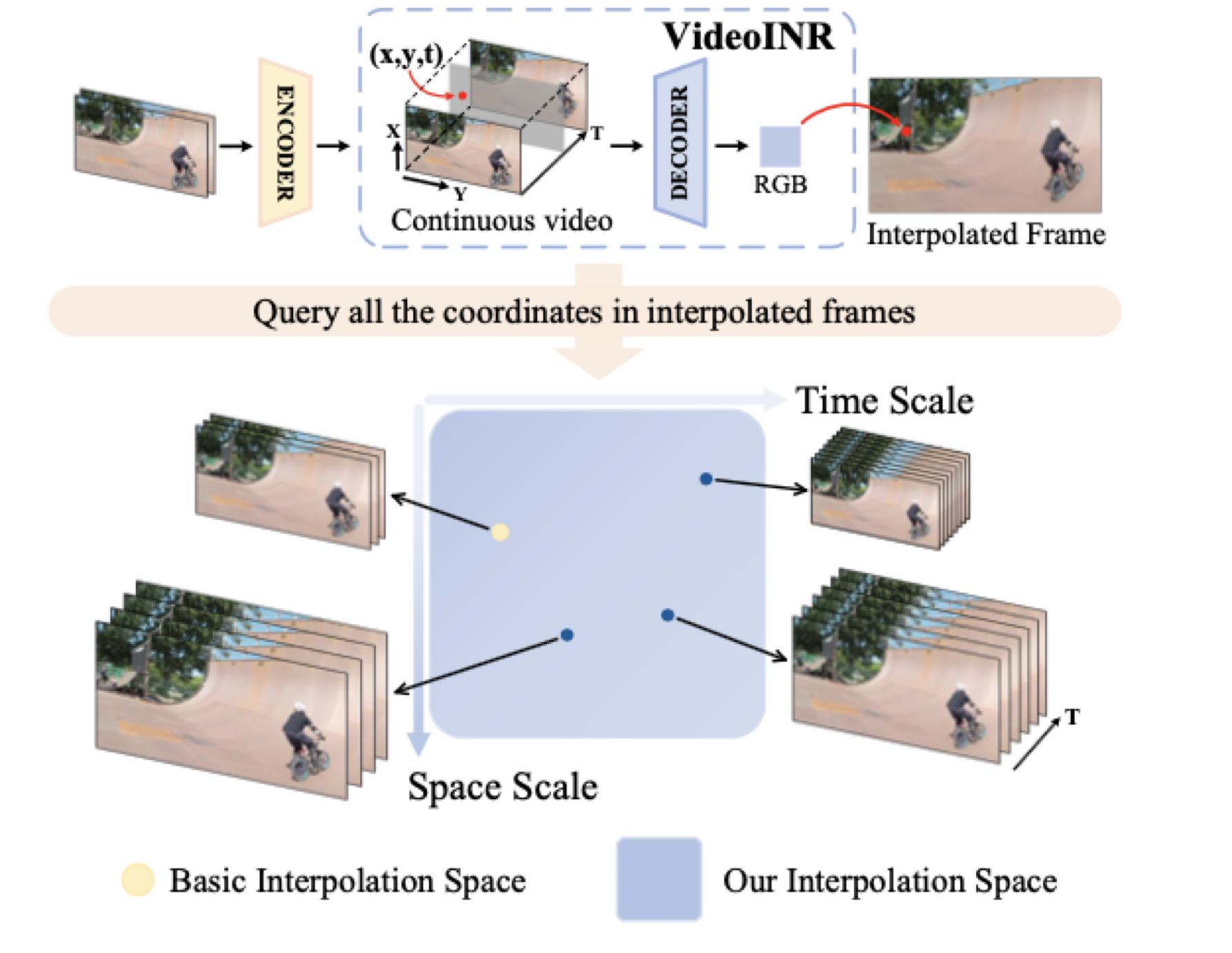
간단한 Flow
- STVSR 작업에서, 두 개의 저해상도 이미지 프레임은 결합되고 공간 차원을 가진 feature map을 생성하는 encoder로 전달된다.
- Continuous spatial feature domain에서 Space Scale을 정의.
→ 고해상도 이미지 특징이 모든 쿼리 좌표에 따라 샘플링된다.
1. Interpolation Space에서 해상도를 먼저 1차적으로 늘리게 학습한 뒤 프레임을 올리도록 학습한다.
2. 그 이후 해상도를 올리기 위해 다시 학습을 진행하게 된다.
3. 두 task를 공유하기 위해 One-Stage 방법을 채택한다. - Decoder를 거쳐 INR RGB 값이 매핑된다.
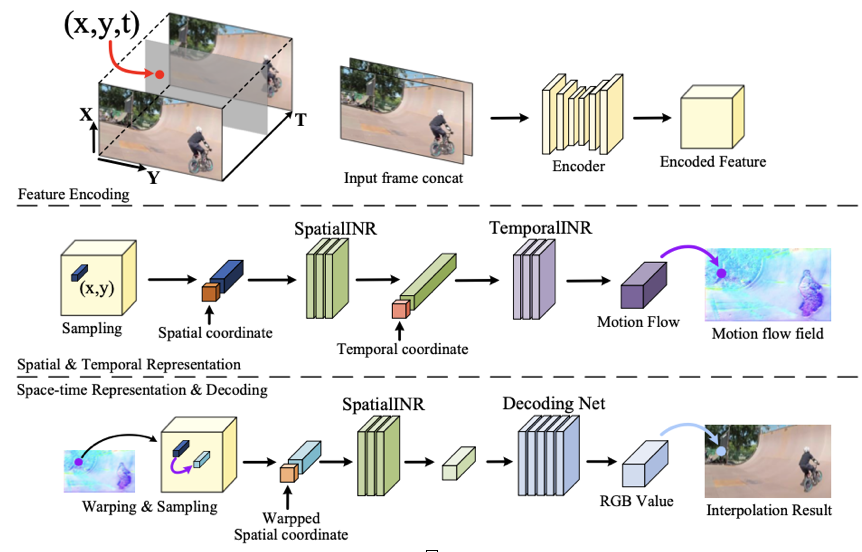
Model
- space-time coordinate (x_s, x_t) concat 2개를 합쳐서 input.
encoder에서 나온 feature map을 Sampling 한다. - sampling에서 나온 spatial 좌표를 SpatialINR에 넣어서 temporal 좌표를 TemporalINR에 다시 넣음.
- TemporaINR에서 나온 motion flow를 warping & sampling 하여 다시 SpatialINR과 Decoding Net을 거쳐 RGB 값을 mapping 시켜 Interpolation Result를 만듬.
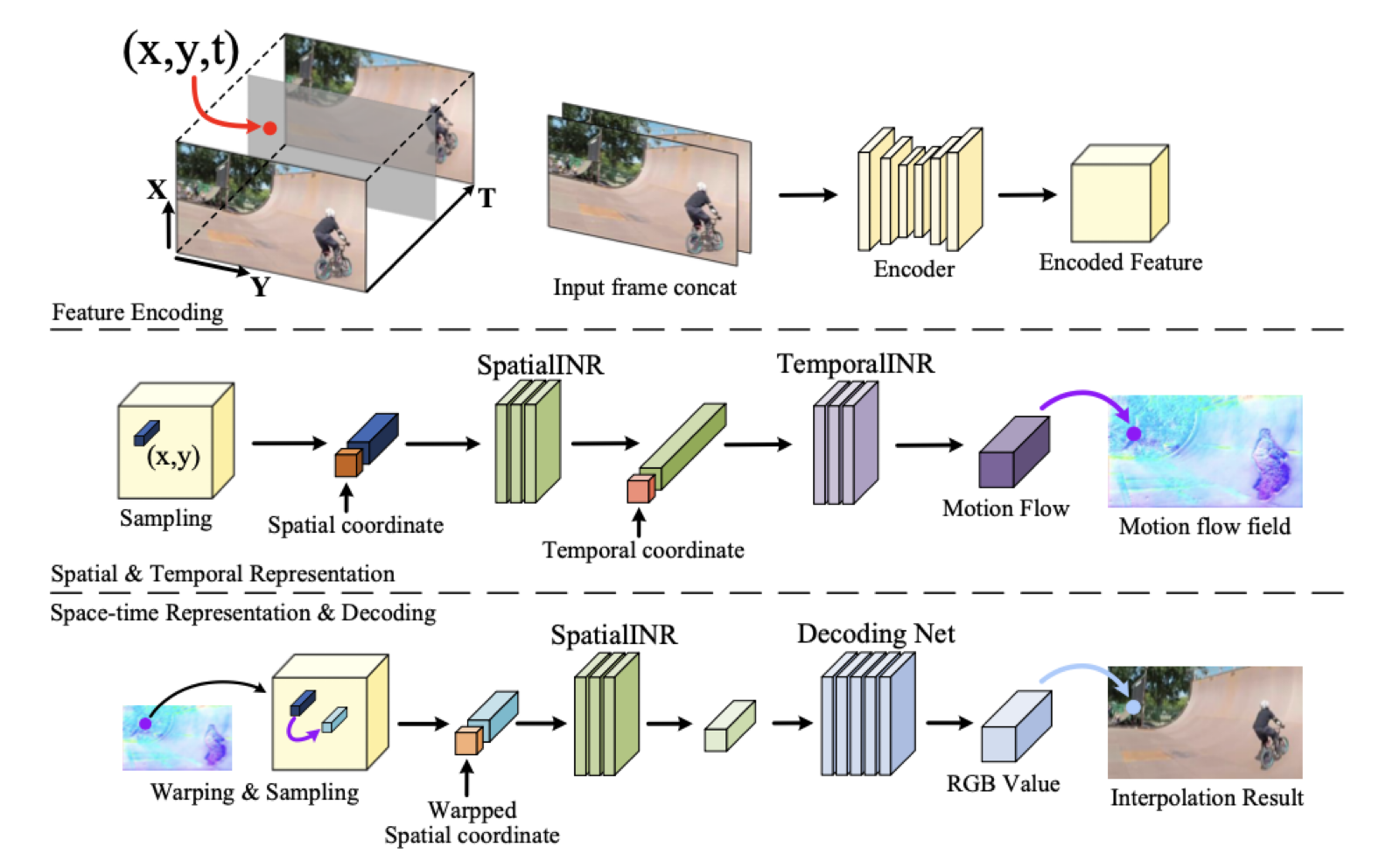
자세한 설명
1. feature map 만들기
: input에서 나온 좌표
: input에서 나온 프레임
: encoder와 sampling
output : Spatial bar
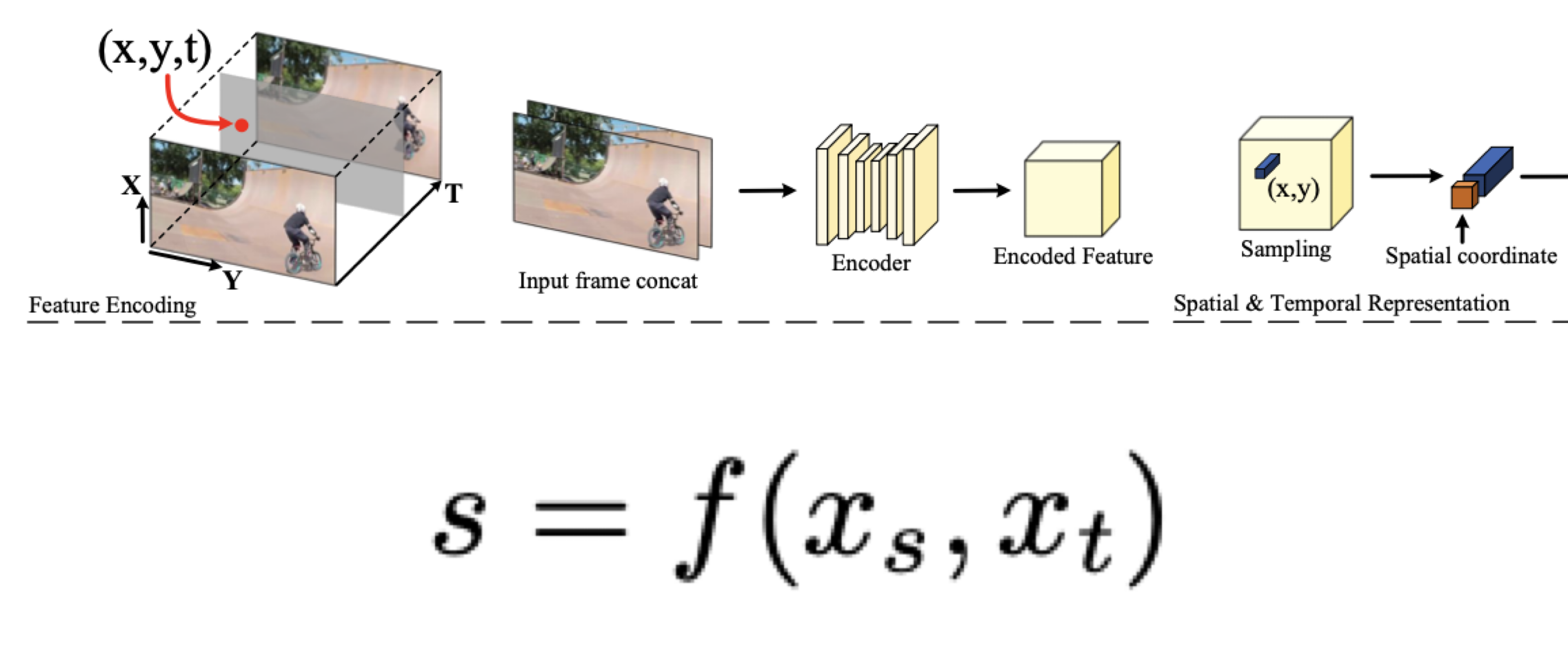
2. Continuous Spatial Representation
: 근처의 feature 정보
: 정보의 좌표
: 두 feature간의 거리 좌표 구하기 → 두 좌표간의 거리가 가까울 수록 중요한 정보이기 때문이다.
: SpatialINR
output : Temporal bar
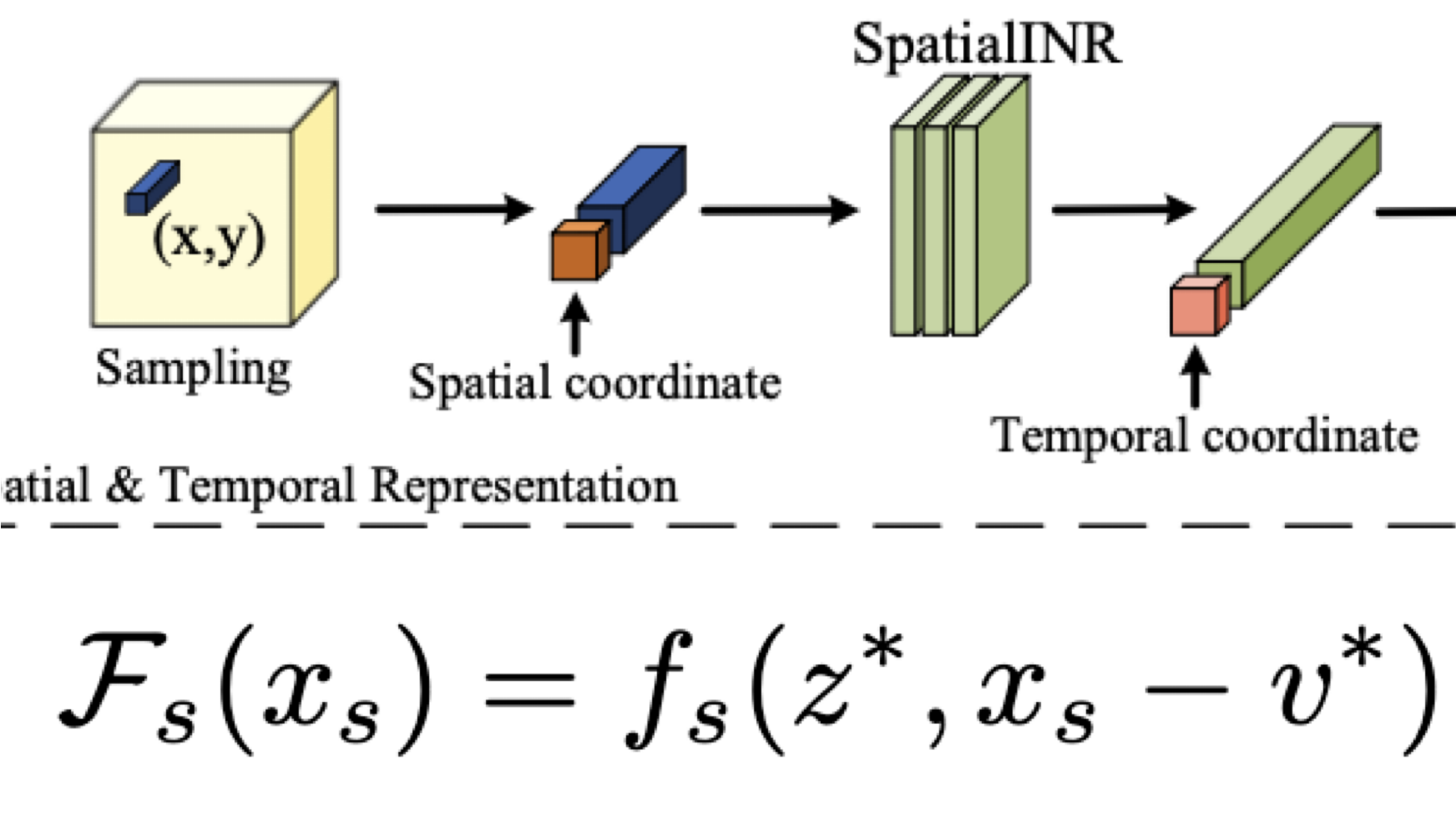
3. Continuous Temporal Representation
: TemporalINR → 좌표와 motion flow를 매핑한 것의 결과
: 공간
: 시간
: prev input frame
: next input frame
2D → 3D : motion patterns과 context information이 필요
: 와 에 대한 motion flow를 return 함.
Continuous Temporal Representation의 목표는 2D space를 3D time space로 만드는 것이다.
3D time space로 바꾸려면 motion patterns과 context information이 필요하다.
(temporalINR)는 motion patterns과 context information을 활용하여 motion flow를 return 한다.
과 , 각각 이전프레임과 다음프레임, 공간 정보를 의미하게 된다.
하지만 우리는 이것들의 역할을 SpatialINR로 대체할 수 있다.
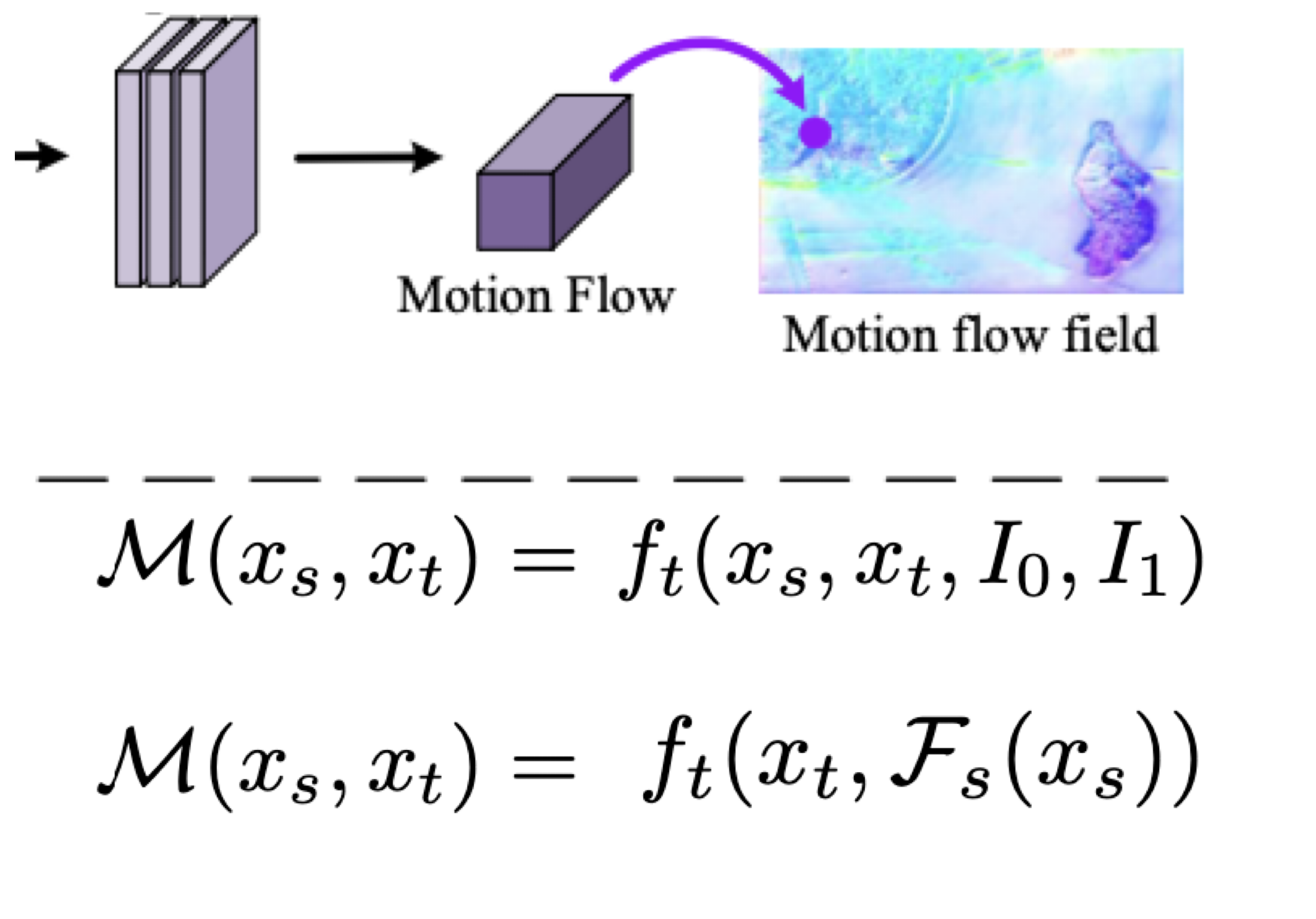
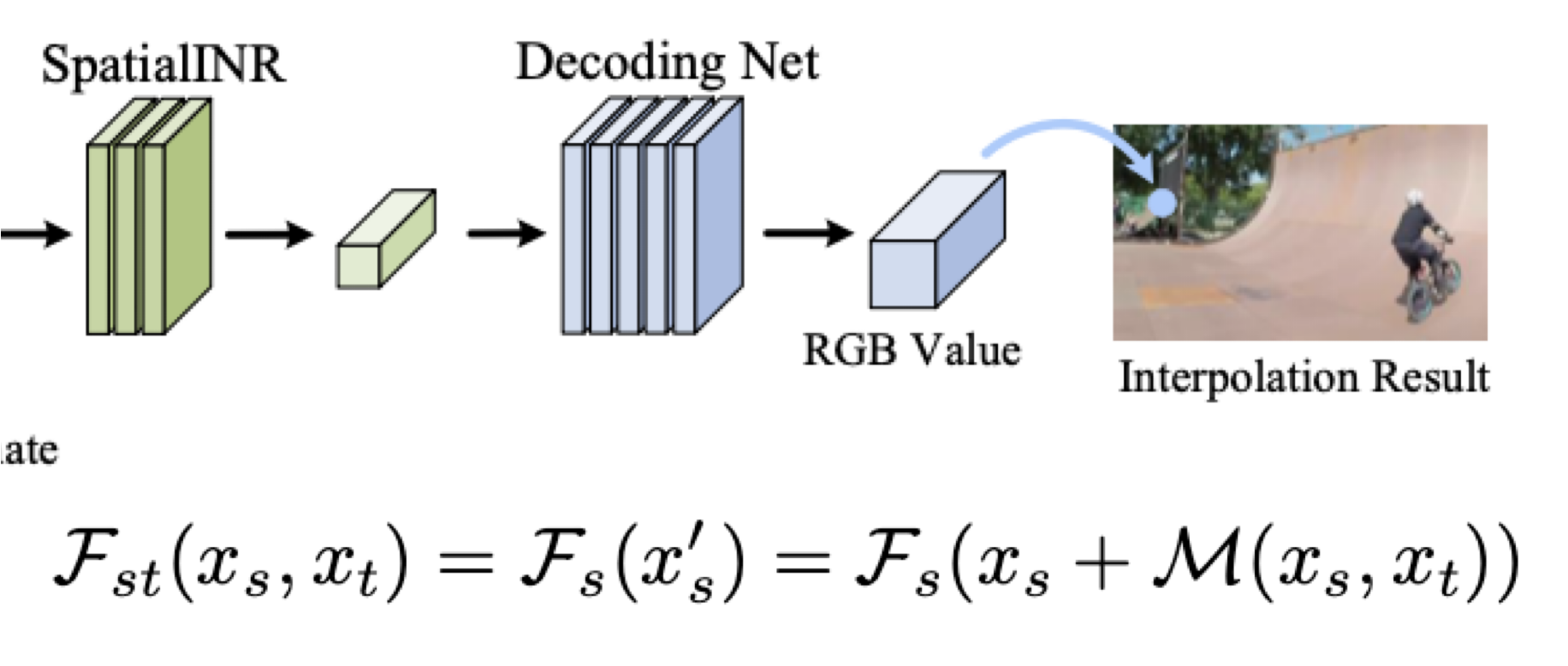
4. Space-Time Continuous Representation
: warp된 continuous feature
: 공간 좌표
: 와 에 대한 motion flow
를 더해주는 이유는 motion flow의 그 다음 motion의 좌표가 나온다.
output: warpped spatial bar
의 다음 행동 예측을 위해 TemporalINR 함수를 거쳐 나온 motion flow를 더해주어 결과적으로 즉 warp된 continuous feature를 만들어줍니다.
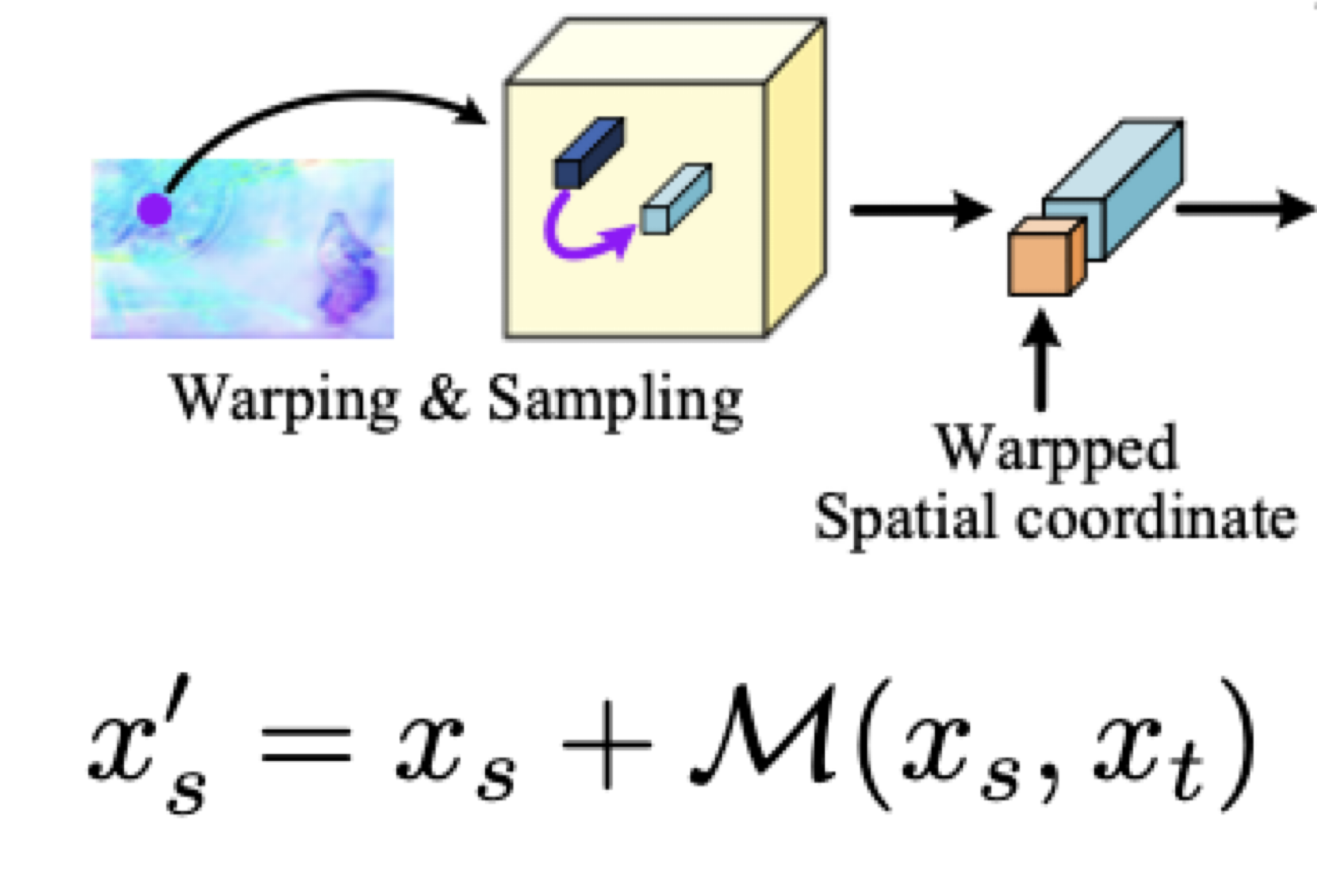
와 를 합치는 과정
: warpped spatial coordinate
: motion flow vector.
: 에 대한 motion flow를 만드는 것
warping된 spatial 좌표를 spatialINR의 contunuous feature를
Decoding Net을 거쳐 시간과 공간을 시공간으로 합친다.
여기서 RGB Value를 mapping 해주어 interpolation result를 얻는다.
마무리
VideoINR은 저해상도 영상을 사용자에게 다시 고화질, 고프레임의 영상으로 보여주기 위해 제작 되었습니다.
또한 이를 활용해 Object Detection을 수행하기 위해 Dataset의 품질을 올릴 수 있습니다.
결과는 VideoINR 공식 사이트 Video로 한눈에 보실 수 있습니다.
코드까지 나와있으니 관심 있으신 분들은 직접 사용해보시는 것을 추천드립니다!
필자는 기존에 논문을 읽으면 수식을 다 넘겼었는데, 처음으로 다 해석해본 논문이었습니다.
🐳 cv-jaeha Github 팔로우는 감사합니다 !
필자는 아직 구직중입니다. 필자에 대해 관심 있으신분들은 Portfolio를 보시고 편하게 연락 부탁드립니다.

고3 이신데 논문 리뷰를.... 정말 훌륭하시군요