IT 현장에서 사용할 수 있는 데이터 분석: 엔지니어가 알아야 할 10가지 기본 개념과 실천 기법

소개
안녕하세요! 백엔드 엔지니어 택입니다. 솔직히 말하자면, 제가 처음 데이터 분석을 접했을 때 완전히 혼란스러웠습니다. "상관계수가 뭐지?", "p값은 어떻게 해석하는 거지?", "이 데이터셋은 어떻게 전처리해야 하지?" 등 모르는 것투성이었습니다.
특히 어려웠던 것은 API에서 데이터를 가져오고 처리하는 방법이었습니다. CSV 파일을 다운로드해서 수작업으로 가공하는 날들... 지금 생각해보면 정말 비효율적이었죠.
이러한 제 경험을 바탕으로, IT 개발자와 엔지니어분들을 위해 처음에 알아두어야 할 10가지 기본 개념과 실제로 사용할 수 있는 유용한 도구를 소개해 드리겠습니다. 이것만 알아두면 시스템 모니터링부터 사용자 행동 분석까지, IT 현장에서의 데이터 활용이 훨씬 효율적이 될 것입니다!
※일부 도구에는 유료 플랜이나 기능 제한이 있을 수 있지만, 모두 무료로 기본적인 사용이 가능합니다.
1. 데이터 수집 (Data Collection)
데이터 분석의 첫 단계는 물론 데이터를 얻는 것입니다. 하지만 실무에서는 단순한 CSV나 Excel 파일뿐만 아니라, Web API에서 데이터를 가져오는 경우가 압도적으로 많습니다.
저의 경우, 처음에는 API 다루는 것에 많은 어려움을 겪었습니다. JSON 파싱 방법을 몰랐거나, 인증 오류로 몇 시간이나 고민했거나... 그럴 때 동료가 알려준 것이 Apidog이라는 도구였습니다. 이것이 정말 유용했습니다!
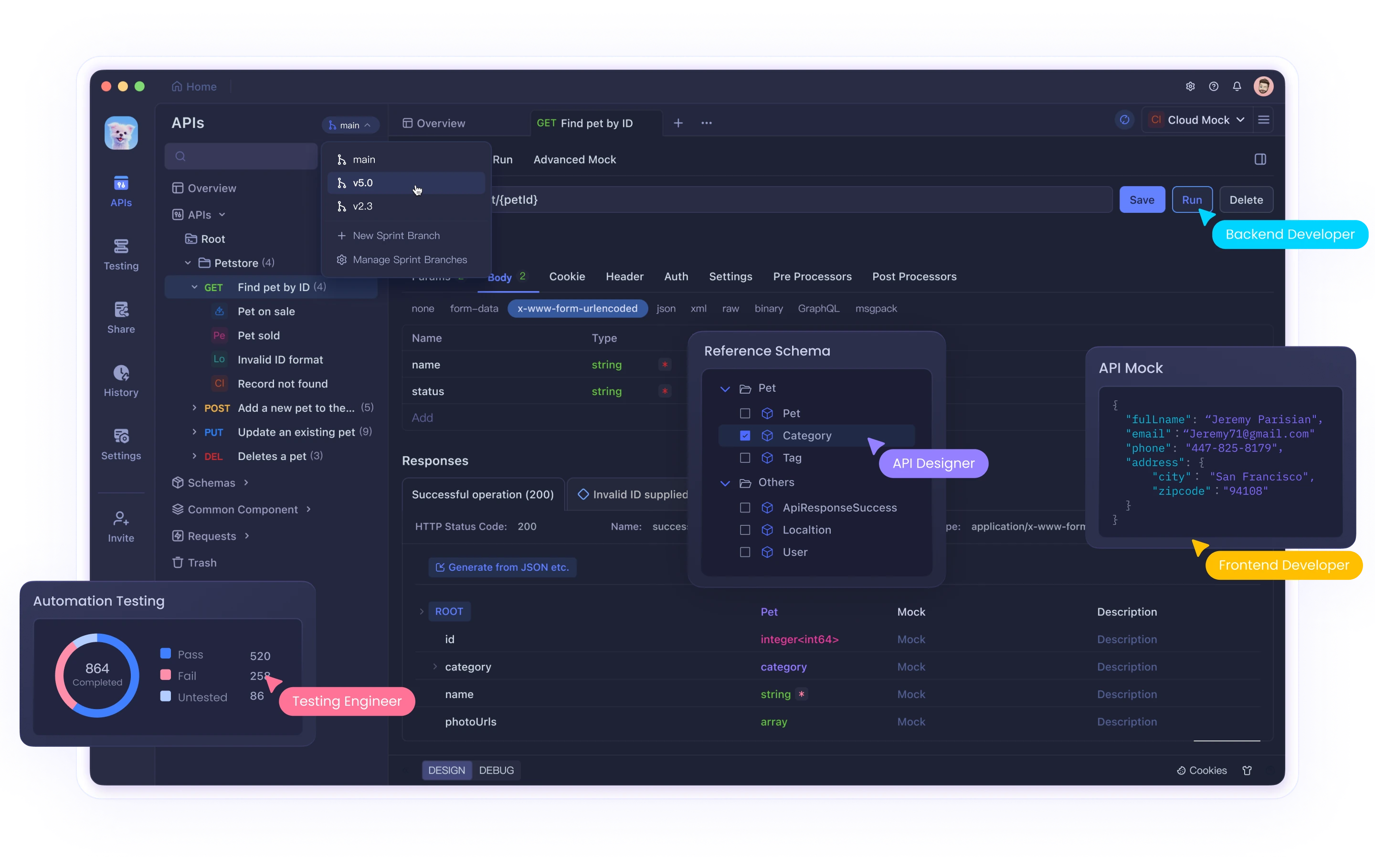
Apidog을 사용하면 코드를 작성하지 않고도 API 요청을 보내고 응답을 확인할 수 있습니다. 또한 결과를 CSV나 JSON으로 저장할 수 있어 그대로 데이터 분석 도구에 넣을 수 있습니다. 특히 Python이나 R 코드를 아직 작성할 수 없는 초보자에게는 강력한 도움이 됩니다.
IT 현장에서의 활용 예: 백엔드 엔지니어로 일하다 보면 로그 분석이나 사용자 행동 데이터 수집이 일상적입니다. 예를 들어, 마이크로서비스 아키텍처에서는 각 서비스의 API에서 데이터를 집계하여 분석함으로써 시스템 전체의 성능 병목 현상을 식별할 수 있습니다.
2. 데이터 품질 (Data Quality)
"쓰레기를 넣으면 쓰레기가 나온다"(Garbage In, Garbage Out)라는 말을 들어보셨나요? 데이터 분석에서는 매우 중요한 원칙입니다.
고품질 데이터에는 다음과 같은 특징이 있습니다:
- 완전성: 결측값이 없음(null이나 공백이 적음)
- 정확성: 입력 오류나 이상값이 없음
- 일관성: 데이터 형식이 통일되어 있음
- 신선도: 최신 정보가 반영되어 있음
제 실패담을 하나 말씀드리자면, 어떤 프로젝트에서 데이터 클렌징을 소홀히 했기 때문에 분석 결과가 완전히 잘못되었던 적이 있었습니다. 그 이후로는 데이터 전처리를 반드시 꼼꼼하게 하게 되었습니다.
IT 현장에서의 활용 예: 웹 애플리케이션 개발에서는 사용자 입력 데이터의 검증(밸리데이션)이 품질 보장의 기본입니다. 프론트엔드와 백엔드 모두에서 데이터 검증을 구현함으로써 데이터베이스의 일관성을 유지하고 버그 발생을 방지할 수 있습니다. CI/CD 파이프라인에 데이터 품질 체크를 포함하는 팀도 늘고 있습니다.
3. 기술적 분석 (Descriptive Analytics)
기술적 분석은 "과거에 무슨 일이 일어났는지"를 이해하기 위한 기본 중의 기본입니다.
제가 처음에 사용한 것은 단순한 Excel이었지만, 데이터 양이 증가하면 Pandas가 압도적으로 편리합니다. 예를 들어, 이런 코드로 간단하게 기본 통계량을 얻을 수 있습니다:
import pandas as pd
# CSV 파일 읽기
df = pd.read_csv('sales_data.csv')
# 기본 통계량 표시
print(df.describe())
# 특정 열의 평균값 계산
print(f"평균 매출: {df['sales'].mean()}원")도구 선택의 포인트는:
-
Excel/Google 스프레드시트: 소규모 데이터, 팀 공유가 필요한 경우
-
Pandas: 대규모 데이터, 반복 분석이 필요한 경우

IT 현장에서의 활용 예: 서버 성능 모니터링에서는 CPU 사용률이나 메모리 소비량 등의 시계열 데이터를 기술적 분석으로 파악합니다. 예를 들어, Prometheus로 수집한 메트릭을 Pandas로 분석하여 서버의 평균 응답 시간이나 95 퍼센타일 값을 산출함으로써 시스템의 건전성을 평가할 수 있습니다.
4. 데이터 시각화 (Data Visualization)
"이 데이터셋의 경향을 모르겠어..."라고 고민하고 있다면, 먼저 시각화해 보세요! 저도 처음에는 표만 보고 있었지만, 그래프로 만든 순간 "아, 이런 거였구나!"라고 깨닫는 경우가 많았습니다.
개인적으로 추천하는 도구는:
-
Tableau: 드래그 앤 드롭으로 직관적으로 조작할 수 있음(단, 유료)
-
Power BI: Microsoft 도구와의 연계가 강함
-
Matplotlib/Seaborn: Python 사용자라면 필수 스킬



특히 Seaborn은 적은 코드로 보기 좋은 그래프를 만들 수 있어서 중요하게 사용하고 있습니다. 예를 들어:
import seaborn as sns
import matplotlib.pyplot as plt
# 상관 히트맵 생성
sns.heatmap(df.corr(), annot=True, cmap='coolwarm')
plt.title('변수 간의 상관관계')
plt.show()이것만으로도 변수 간의 관계성이 한눈에 들어옵니다!
IT 현장에서의 활용 예: 네트워크 트래픽 분석에서는 시간대별 데이터 전송량을 히트맵으로 시각화함으로써 비정상적인 접근 패턴을 빠르게 감지할 수 있습니다. 또한, 마이크로서비스 아키텍처에서는 서비스 간의 의존 관계를 네트워크 그래프로 시각화하여 시스템 구조의 이해를 깊게 할 수 있습니다.
5. 탐색적 데이터 분석 (EDA)
EDA는 "데이터 탐험"이라고 생각하면 이해하기 쉽습니다. 어떤 전제도 가지지 않고, 데이터의 특성을 이해하는 프로세스입니다.
제가 EDA에서 반드시 하는 것은:
- 각 변수의 분포 확인(히스토그램)
- 이상치 체크(박스 플롯)
- 변수 간의 관계성 탐색(산점도 행렬)
Jupyter Notebook을 사용하면 코드와 결과, 그리고 고찰을 함께 기록할 수 있어서 나중에 "그때 뭘 했더라?"라고 고민하지 않아도 됩니다. 팀 내 공유에도 최적입니다.
IT 현장에서의 활용 예: 애플리케이션 로그 데이터 분석에서는 EDA를 통해 오류 발생 패턴이나 성능 저하의 징후를 발견할 수 있습니다. 예를 들어, 특정 API 엔드포인트의 응답 시간 분포를 조사하고 비정상적으로 느린 요청의 공통점을 찾음으로써 성능 최적화의 단서를 얻을 수 있습니다.
6. 추론 통계 (Inferential Statistics)
추론 통계는 솔직히 제가 가장 어려워했던 분야입니다. p값의 해석이나 귀무가설이나... 하지만 기본적인 개념만 이해하면 그렇게 어렵지 않습니다.
예를 들어, 새로운 웹 디자인이 전환율을 향상시키는지 여부를 검증하는 A/B 테스트를 생각해 봅시다. 이것은 전형적인 추론 통계의 응용 예입니다.
Python에서는 SciPy를 사용하여 쉽게 검정할 수 있습니다:
from scipy import stats
# A/B 테스트 결과(가상 데이터)
design_a = [0, 1, 0, 0, 1, 0, 1] # 0=비전환, 1=전환
design_b = [1, 1, 0, 1, 1, 1, 0]
# 카이제곱 검정 실행
chi2, p_value = stats.chi2_contingency([[sum(design_a), len(design_a)-sum(design_a)],
[sum(design_b), len(design_b)-sum(design_b)]])[0:2]
print(f"p값: {p_value:.4f}")
if p_value < 0.05:
print("디자인 B가 통계적으로 유의하게 우수합니다!")
else:
print("통계적인 유의한 차이가 없습니다")IT 현장에서의 활용 예: 웹사이트나 앱의 A/B 테스트는 추론 통계의 대표적인 IT 응용 예입니다. 예를 들어, 새 기능 출시 전에 사용자의 일부에게 새 기능을 제공하고 나머지에게는 기존 기능을 제공함으로써 새 기능의 효과를 통계적으로 검증합니다. 이를 통해 감각이 아닌 데이터에 기반한 의사결정이 가능해집니다.
7. 상관관계와 인과관계 (Correlation vs. Causation)
"아이스크림 판매량과 익사 사고 발생률 사이에는 강한 상관관계가 있다"
이 말을 듣고 "아이스크림을 먹으면 익사하기 쉬워진다"고 결론 내리시겠습니까? 물론 아니죠. 둘 다 "여름"이라는 제3의 요인에 영향을 받고 있을 뿐입니다.
이것이 "상관관계와 인과관계는 별개"라는, 데이터 분석에서 가장 중요한 교훈 중 하나입니다.
상관관계를 확인하려면 Seaborn의 heatmap이 편리합니다:
# 상관계수 행렬 계산
corr_matrix = df.corr()
# 히트맵으로 시각화
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('상관계수 행렬')
plt.show()IT 현장에서의 활용 예: 시스템 모니터링에서는 여러 메트릭 간의 상관관계를 분석하여 문제의 근본 원인을 식별할 수 있습니다. 예를 들어, 데이터베이스 응답 시간과 CPU 사용률 사이에 강한 상관관계가 있다면 CPU 리소스 증강이 해결책이 될 수 있습니다. 단, 둘 다 다른 요인(예: 피크 시간대의 트래픽 증가)에 의해 발생할 가능성도 고려해야 합니다.
8. 예측 분석 (Predictive Analytics)
"다음 달 매출은 어떻게 될까?", "이 사용자는 해지할 것 같을까?"
이러한 미래 예측에는 기계 학습 모델이 활약합니다. 초보자에게도 추천하는 것은:
- 선형 회귀: 연속값 예측(매출 예측 등)
- 로지스틱 회귀: 이진 분류(해지할지 말지 등)
- 결정 트리: 해석하기 쉬운 모델
scikit-learn을 사용하면 이런 식으로 쉽게 구현할 수 있습니다:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 특성과 타겟 분리
X = df[['feature1', 'feature2', 'feature3']]
y = df['target']
# 훈련 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 훈련
model = LinearRegression()
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 평가
mse = mean_squared_error(y_test, y_pred)
print(f"평균 제곱 오차: {mse:.2f}")시간이 없거나 코딩이 어려운 분들에게는 Google Cloud AutoML과 같은 노코드 도구도 추천합니다.
IT 현장에서의 활용 예: 서버 리소스 수요 예측은 클라우드 인프라의 효율적인 운영에 필수적입니다. 예를 들어, 과거 트래픽 패턴에서 기계 학습 모델을 구축하여 미래 리소스 수요를 예측함으로써 자동 스케일링 정책을 최적화할 수 있습니다. 또한, 사용자 행동 데이터에서 해지 위험이 높은 사용자를 예측하고 사전에 대책을 마련할 수도 있습니다.
9. 데이터 기반 의사결정 (Data-Driven Decisions)
"경영자의 직감"보다 "데이터의 사실"—이것이 데이터 기반 의사결정의 본질입니다.
제가 이전에 일했던 회사에서는 "왠지 이 기능이 인기 있을 것 같다"는 감각으로 개발을 진행했지만, 실제로 사용자 데이터를 분석해 보니 전혀 다른 기능이 요구되고 있었습니다. 그 이후로 "먼저 데이터를 보자"가 제 모토가 되었습니다.
데이터를 의사결정에 활용하기 위한 포인트:
- 적절한 KPI 설정: 무엇을 측정해야 하는지 명확히 하기
- 대시보드 작성: 실시간으로 데이터 모니터링
- A/B 테스트 실시: 가설을 검증한 후 구현
Metabase나 Looker와 같은 BI 도구를 사용하면 기술자가 아니더라도 직관적으로 데이터를 탐색할 수 있습니다.
IT 현장에서의 활용 예: 애자일 개발 팀에서는 스프린트별 속도나 버그 발생률 등의 메트릭을 추적하여 개발 프로세스 개선에 활용합니다. 또한, DevOps 맥락에서는 배포 빈도, 변경 리드 타임, 장애 복구 시간 등의 지표를 측정하여 지속적인 개선을 도모합니다. 이러한 데이터를 기반으로 팀 구성이나 도구 선정 등의 의사결정을 수행합니다.
10. 데이터 윤리와 개인정보 보호 (Ethics & Privacy)
마지막으로, 하지만 결코 가볍게 볼 수 없는 것이 데이터 윤리와 개인정보 보호 문제입니다.
우리 엔지니어들에게는 수집한 데이터를 책임감 있게 다룰 의무가 있습니다. 특히 개인정보를 포함하는 데이터를 다룰 때는 다음 포인트를 의식해야 합니다:
- 익명화: 개인을 식별할 수 있는 정보 제거 또는 변환
- 최소한의 수집: 필요한 데이터만 수집
- 투명성: 사용자에게 데이터 사용 목적 명시
- 보안: 데이터의 안전한 보관과 처리
한국에서는 개인정보 보호법, EU에서는 GDPR, 캘리포니아주에서는 CCPA 등 지역에 따라 다른 법규제가 있으므로 주의가 필요합니다.
IT 현장에서의 활용 예: 웹 애플리케이션 개발에서는 데이터 보호를 설계 단계부터 포함하는 "프라이버시 바이 디자인" 원칙이 중요합니다. 예를 들어, 사용자 데이터 암호화, 접근 제어 구현, 정기적인 보안 감사 등을 통해 데이터 유출 위험을 최소화합니다. 또한, 로그 수집 시 개인 식별 정보(PII)를 자동으로 마스킹하는 도구를 도입함으로써 개발 및 테스트 환경에서도 안전하게 데이터를 다룰 수 있습니다.
결론
여기까지 읽어주셔서 감사합니다! 데이터 분석의 세계는 방대하지만, 이 10가지 기본 개념을 알아두면 적어도 방향성을 잃지 않을 것입니다.
저 자신도 데이터 분석의 길을 걷기 시작했을 때는 정말 혼란스러웠지만, 기초를 단단히 다지면서 점차 자신감을 가지고 데이터와 마주할 수 있게 되었습니다.
특히 API에서 데이터를 가져올 기회가 많은 분들에게는 Apidog과 같은 도구가 큰 도움이 됩니다. 저도 일상 업무에서 활용하고 있지만, API 테스트부터 데이터 수집까지 원활하게 수행할 수 있어 분석 준비 시간이 크게 단축되었습니다.
여러분의 데이터 분석 여정이 풍요로운 것이 되기를 바랍니다. 질문이나 의견이 있으시면 언제든지 댓글로 공유해 주세요!
