오늘은 모델에서 발생할 수 있는 Underfitting과 Overfitting에 대해 알아보도록 하겠습니다.
Underfitting
underfitting이란, training과 testing 에서 모두 error가 높은 현상을 의미한다.
흔히 underfitting이 일어나는 현상은 다음과 같을 수 있다.
1. Model의 복잡도가 너무 낮아서 데이터를 학습하지 못한다.
2. 데이터의 양이 절대적으로 부족하다.
Overfitting
overfitting이란 training에서의 error는 낮지만, testing에서의 error가 높은 현상을 의미한다.
overfitting이 일어나는 이유는 다음과 같을 수 있다.
1. Model의 복잡도가 너무 높은경우
2. Data의 양이부족하거나, train data의 질이 좋지 못한 경우
Bias & Variance
overfitting과 underfitting을 이야기할때 절대적으로 빠져서는 안되는 2개념들이다.
Bias : 말 그대로 편향이다. 즉, 실제 값과 얼마나 멀리 떨어져있나 를 의미한다.
- Bias가 높다 -> 정답을 잘 맞추지 못한다.
- Bias가 낮다 -> 정답과 유사하다
Bias가 높은 이유 : Model이 너무 단순한경우.
Variance: 분산을 의미한다. variance는 모델이 새로운 data에 대해 얼마나 민감하게 반응하냐를 의미한다.
- Variance가 높다 -> 새로운 데이터를 잘 학습하지 못한다.
- Variance가 낮다 -> 새로운 데이터에 대해 안정적으로 예측이 가능하다.
Variance가 높은 이유 : overfitting된 경우.(모델이 복잡한 경우)
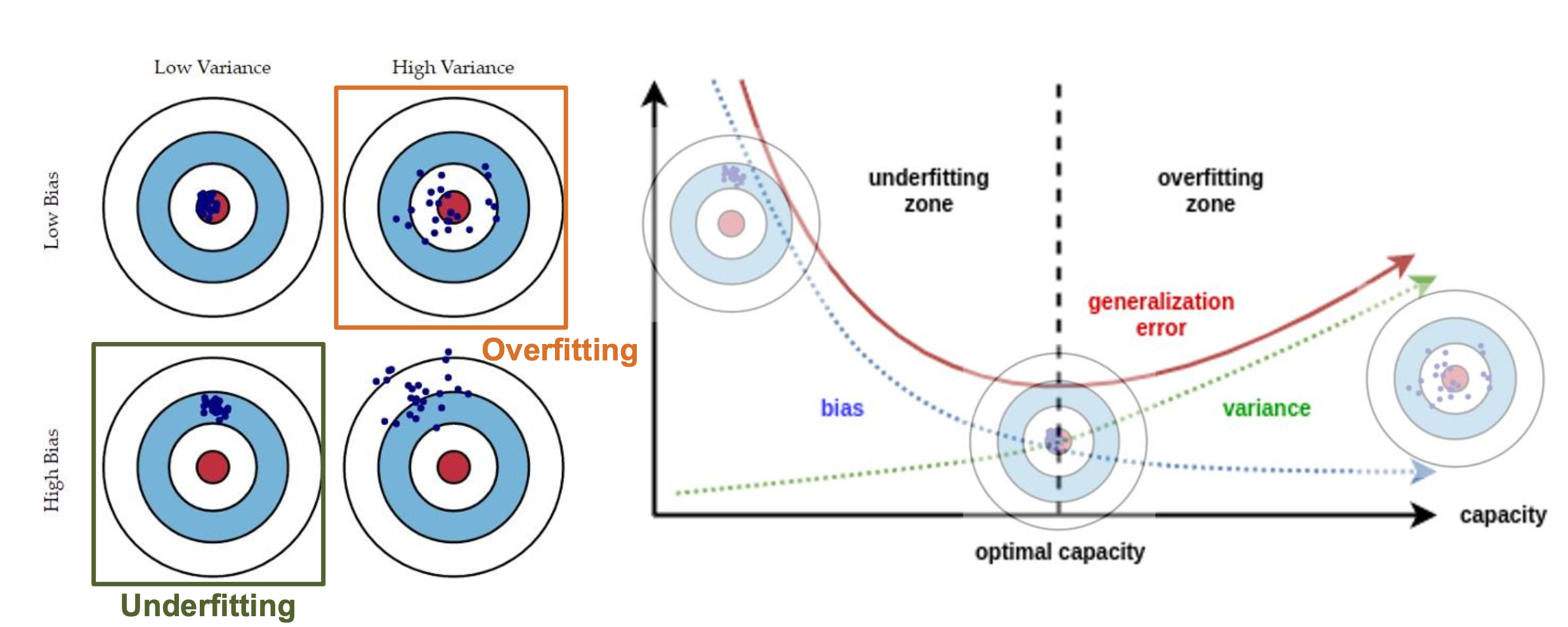
위 그림처럼 Bias와 Variance는 tradeoff의 관계를 가지고 있기 때문에 적정한 선을 선정하는 것이 중요하다.
위 그림에서 generalization error 라는 말은 새로운 데이터에 대해서 얼마나 잘 일반화 할수 있는지에 대한 수치입니다.
그렇다면 Underfitting과 Overfitting은 어떻게 막을 수 있을까.
주로 DeepLearning에서 Overfitting과 관련된 문제가 더욱 종요하기 때문에 Overffing 을 막는 법에 대해서만 자세히 알아보겠다.
Underfitting을 막는법은 단순히 데이터 양을 늘리거나, 모델의 복잡돌르 키워주면된다.
Prevent Overfitting
overfitting을 막는 방법에는 다양한 방법들이 존재하는데 우선 어떤 것들이 있는지 정리해보면 다음과 같다.
- Data 추가
- Mdoel 단순화
- 정규화 (Regularization)
- Dropout
- Early stopping
- Ensembling
- Batch normalization
이중에서 정규화, dropout, Batch normalization에 대해 알아보도록 하겠습니다.
Regularization(정규화)
정규화란, 모델이 너무 지나치게 데이터를 학습하는 것을 억제해주는 기법입니다.
만약에 특정 W에 대해서 모델이 너무 학습을 해버리면, 노이즈, 오류에 대해서 학습을 할수도 있고, 새로운 데이터에 대한 대응이 안되기 때문에 특정 가중치가 너무 커지는 것을 막아주므로써 일반화 능력을 올려줍니다.
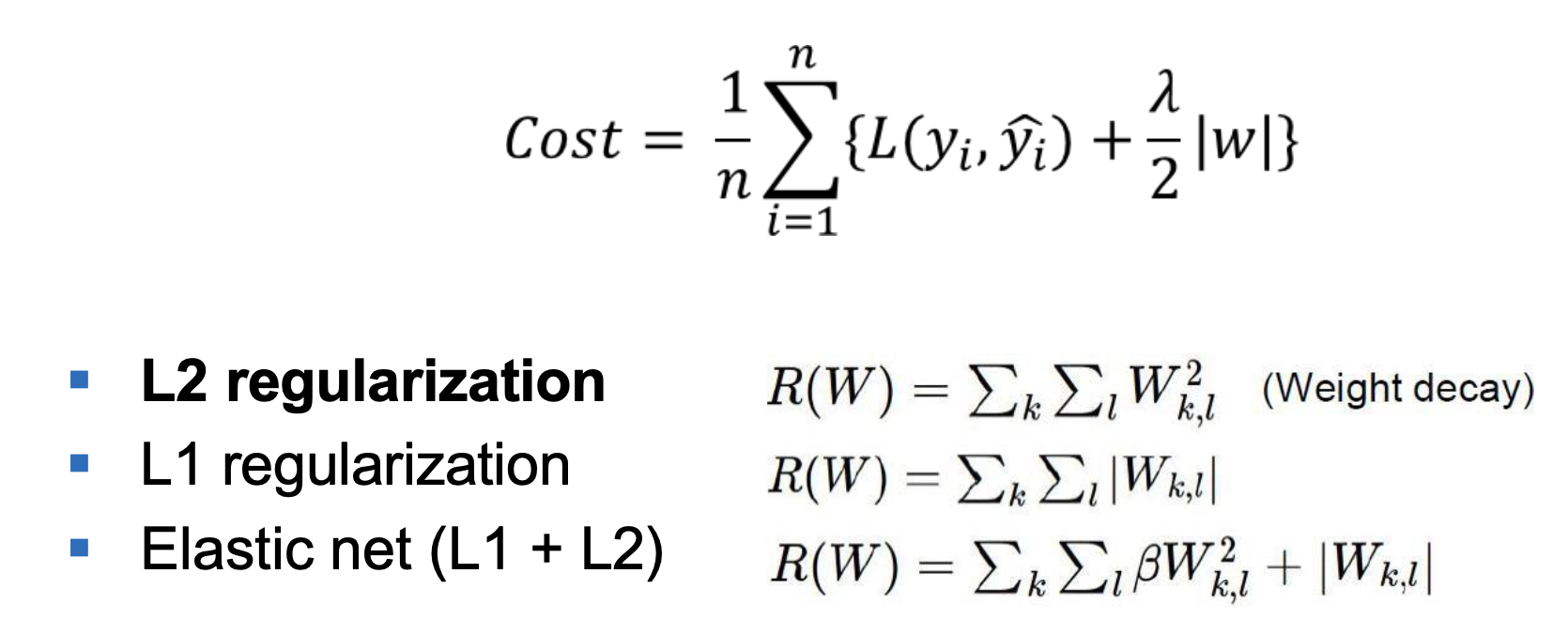
다음과 같이 수식으로 표현이 가능합니다.여기서 L()안의 값들은 이제 오차이고(즉, W값들이 포함되어 있다) 그리고 뒤에 + 로 penalty term을 추가해줍니다.
이렇게 penalty term을 W의 sum을 활용하게 되면 w를 너무 학습하는 경우 cost 가 올라가기 떄문에 특정 W를 너무 크게 학습하는 것을 막아줍니다.
그리고 penalty term에 N1, N2 norm등을 활용할수 있습니다.
L1 Norm을 사용하는 경우 :
특정 parameter를 0으로 만들어 특징을 두드러지게 만드는데 유리합니다.
희소성모델로(0이 많이 포함된 모델) 메모리 효율일 좋다.
L2 Norm을 사용하는 이유 :
모든 부분에 대해서 미분이 가능하며, 계산이 쉬워 계산적으로 효율적이다.
모든 W가 너무 커지는것을 방지하여 Overffing 방지에 유리하다.
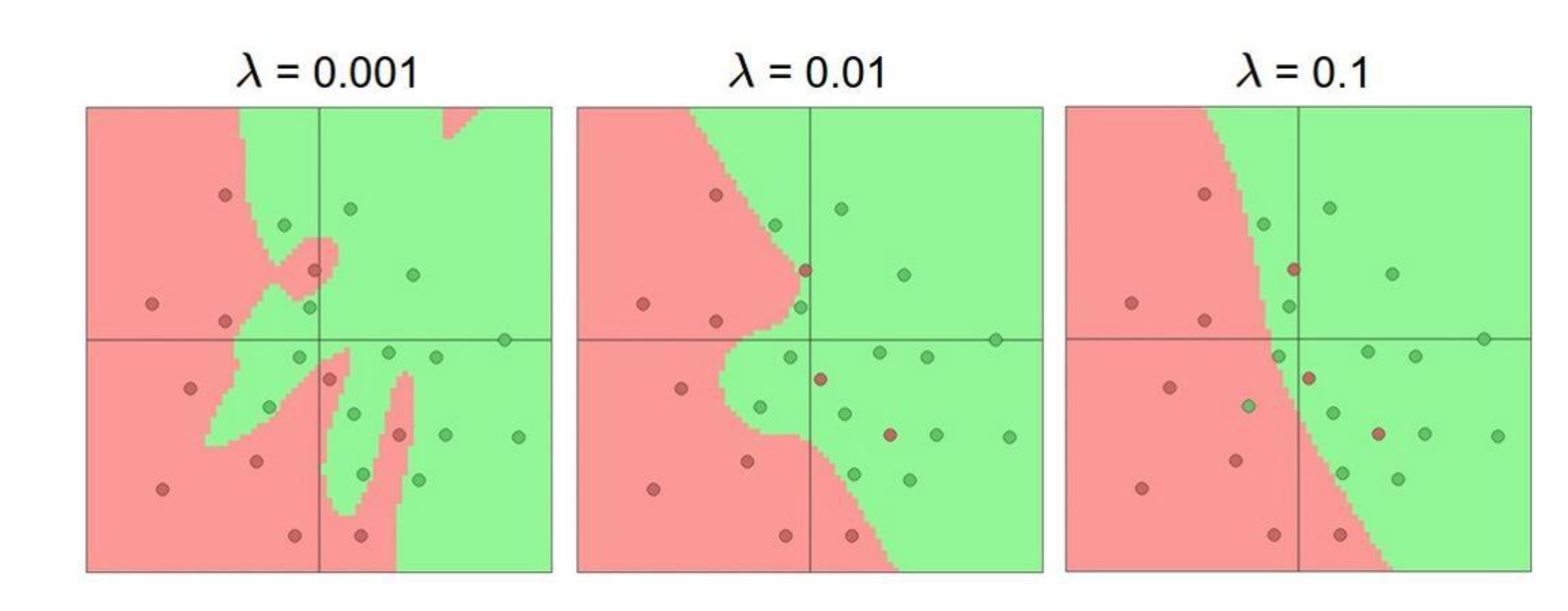
그리고 Regularization에는 hyperparameter가 하나 있는데, 바로 Norm 앞에 붙은 변수인데, 이는 penalty term의 영향을 어떻게 설정할지를 결정하는 변수야.
즉, 람다를 어떻게 설정하느냐에 따라서 overfitting을 막으수도, 막지 못할수도 있습니다.
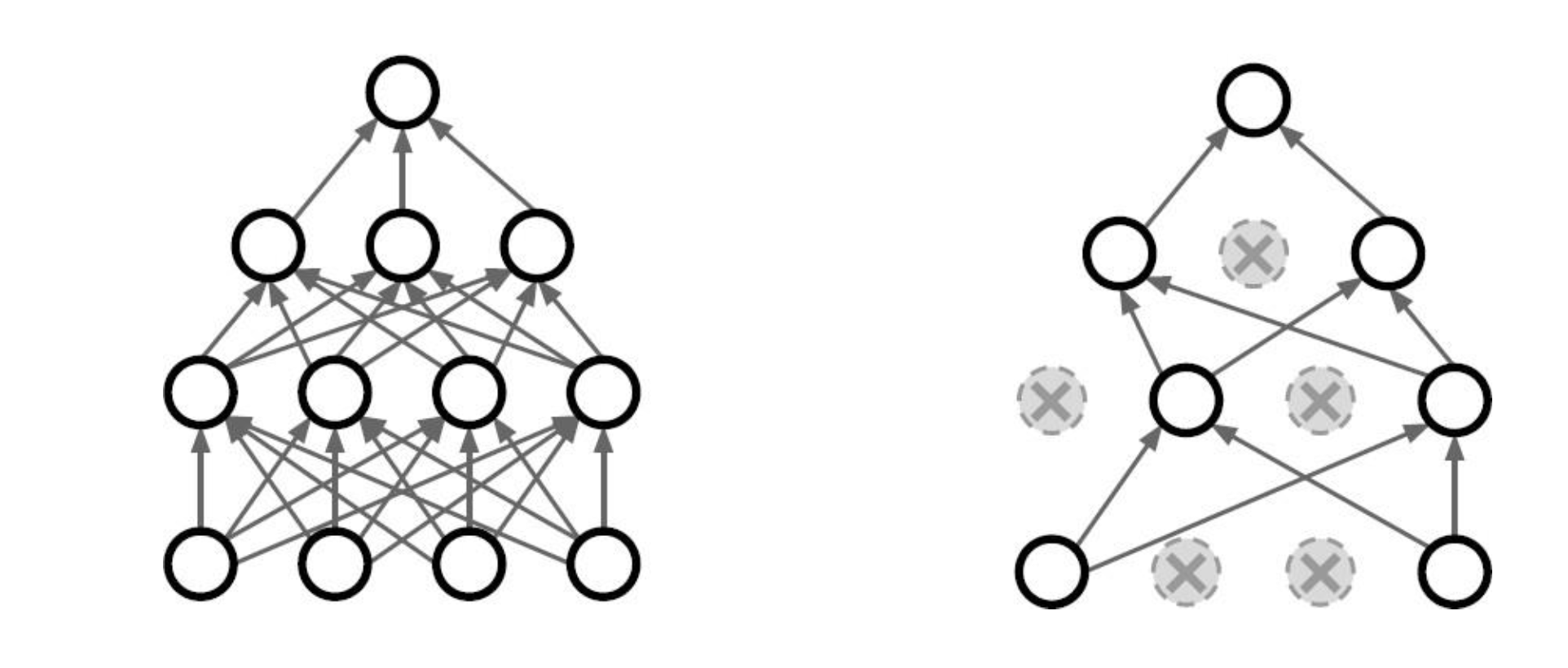
DropOut
Dropout 기법은 특정 노드를 제거하고 학습을 진행합니다..
특정 W가 지나치게 학습하는 것을 막기위해서 도입된 개념입니다.
특정 노드에 의존하지 않고, 학습시 계속 노드들의 조합이 달라져서 미니 앙상블과 같은 효과를 내기도 합니다.
Batch normalization
우선 normalization의 개념에 대해서 간단하게 살며보면, 우리가 normalizaiton을 사용하면 보다더 안정적으로 데이터를 만들어줄 수 있다.
그리고 Covariate shift problem에 대해서 간단하게 알아보자.
Covariate shfit 문제는 바로 train dat의 분포랑 test data의 분포가 달라서 우리가 train 할때 사용했던 w값들이 잘 작동하지 않아서 발생하는 문제이다.
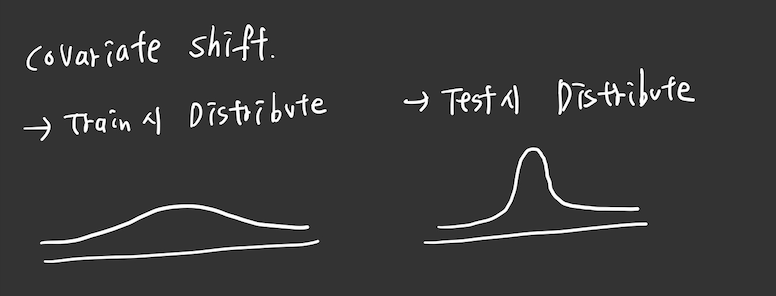
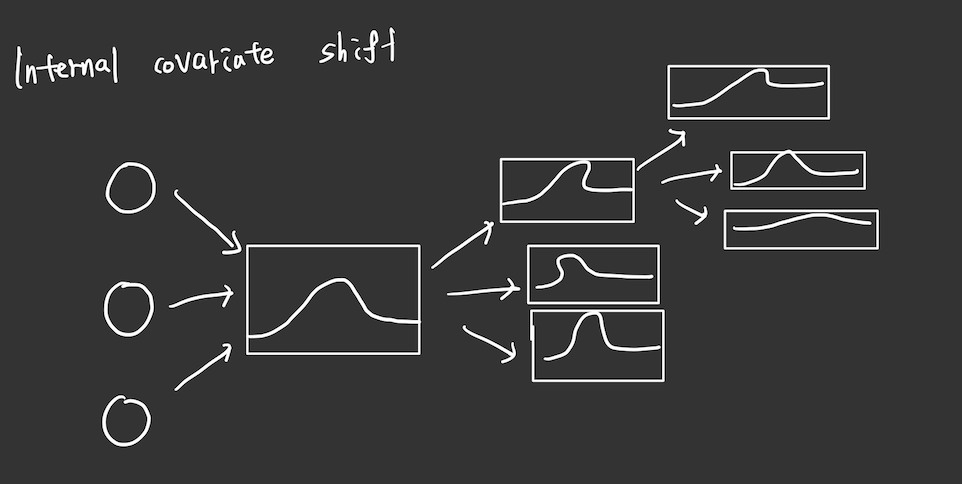
그런데 이러한 문제가 바로 하나의 모델안에서 일어난다는 것이다.
그게 바로 우리가 집중해서 봐야하는 문제는 Internal Covariate shfit 문제이다.
이는 모델을 학습할때 각각의 레이어에서 input data의 분폭 달라진다는 문제점이다. 한번 잘못된 분포는 계속 잘못된 방향으로 학습 될 가능성이 크기 떄문에 문제가 발생한다는 것이다.
그림으로 간단하게 그려보면 다음과 같은 현상이 일어난다는 것이다.
비록 whitening이라는 기법도 존재합니다. 하지만 whitening의 경우 backpropagation 과정과 분리되어 모든 input 값을 정규분포를 따르게 하는 기법인데, 너무나도 많은 연산량을 가지고 있어 자주 사용되는 기법은 아니라고 합니다.
하지만 Batch normalization의 경우 backpropagation 과정에서 data들을 정규화 하는 직접적인 방법이며, mini batch에서 평균, 분포를 가지고 정규화 하며 scale과 size 모두 학습이 가능하다는 장점이 있습니다.여기서 scale과 size를 도입한 이유는 단순히 분포를 일정하게 유지하는 것 뿐 아니라 최적의 분포를 찾아가도록 학습하기 위함입니다.
이렇게 backpropagation 과정중 input data들을 정규화 하는 과정 자체가 간접적으로 overfitting을 방지해주는 역할을 수행하기에 overffitng을 막는 기법으로 자주 사용된다고 합니다.
오늘은 이렇게 overfitting과 underfitting이 일어나는 이유와, overfitting을 막는 다양한 방법들에 대해서 알아보았습니다.
