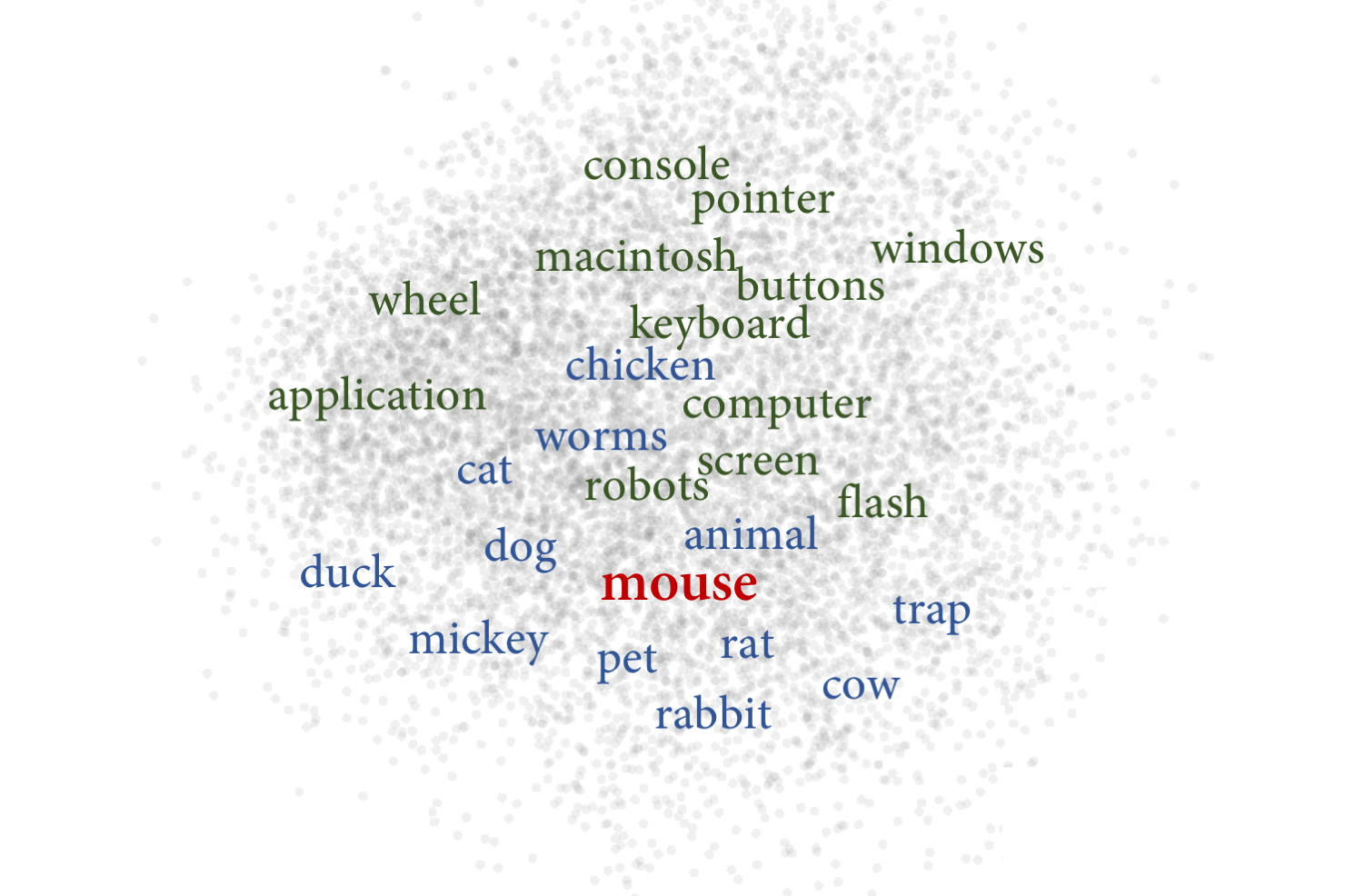
애랑 나랑 얼마나 비슷해?
NLP에서 Vector의 역할은?
Bag-of-Word (BoW) vector 또는 tf-idf vector는
문장을 단어의 빈도수를 계산해 N차원의 column vector로 표현한 것을 배웠다.
N은 전체 단어의 숫자
word embedding은 각 단어들 GloVe, skipgram같은 알고리즘으로
단어들 비교적 작은 100차원, 300차원 등 vector로 줄여서 만들 수 있다.
핵심은 문장, 문서, 그리고 단어를 숫자들로 이루어진 vector로 만들어
N차원의 공간의 하나의 점으로 바꾸어 표현한다는 것
두개의 vector 사이의 거리를 재보자: Eucliedian Distance

2차원에서 두 점 사이의 거리를 재는 것을
N차원으로 확대한 식
개념적으로 본다면 두 점 사이에 줄을 긋고, 그 줄의 길이를 계산하는 것이다.

두 개의 vector 사이의 각을 재보자: Cosine Similarity
Cosine similarity는 두개의 vector들 사이의 각도 계산한다.
그 때문에 크기는 무시되고, 방향의 차이만 계산 된다.
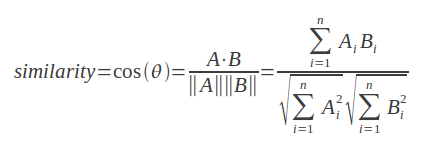
vector A와 vector B의 Cosine similarity 계산 방법
위의 수식 풀어보자면, 만약 vector A와 vector B가:
- 같은 방향(0°)이라면 1,
- 완전히 반대 방향(180°)이라면 -1,
- 서로 독립적(90°)이라면 0
cosine distance는 cosine similarity랑 같은 걸 그냥 뒤집어 생각한것이다.
Cosine Distance = 1 - Cosine Similarity
만약 vector A와 vector B가:
- 같은 방향(0°)이라면 0,
- 완전히 반대 방향(180°)이라면 2,
- 서로 독립적(90°)이라면 1
그래서 뭘 써야할까?
NLP 문제에서는 cosine similarity가 주로 쓰인다.
왜냐면 vector를 단어의 빈도 수로 계산하는 경우가 많기 때문이다.
Word2vec 공간을 cosine distance로 explore 하기
가장 많이 쓰이는 word embedding인 word2vec를 3D로 표현하면 어떻게 될까?
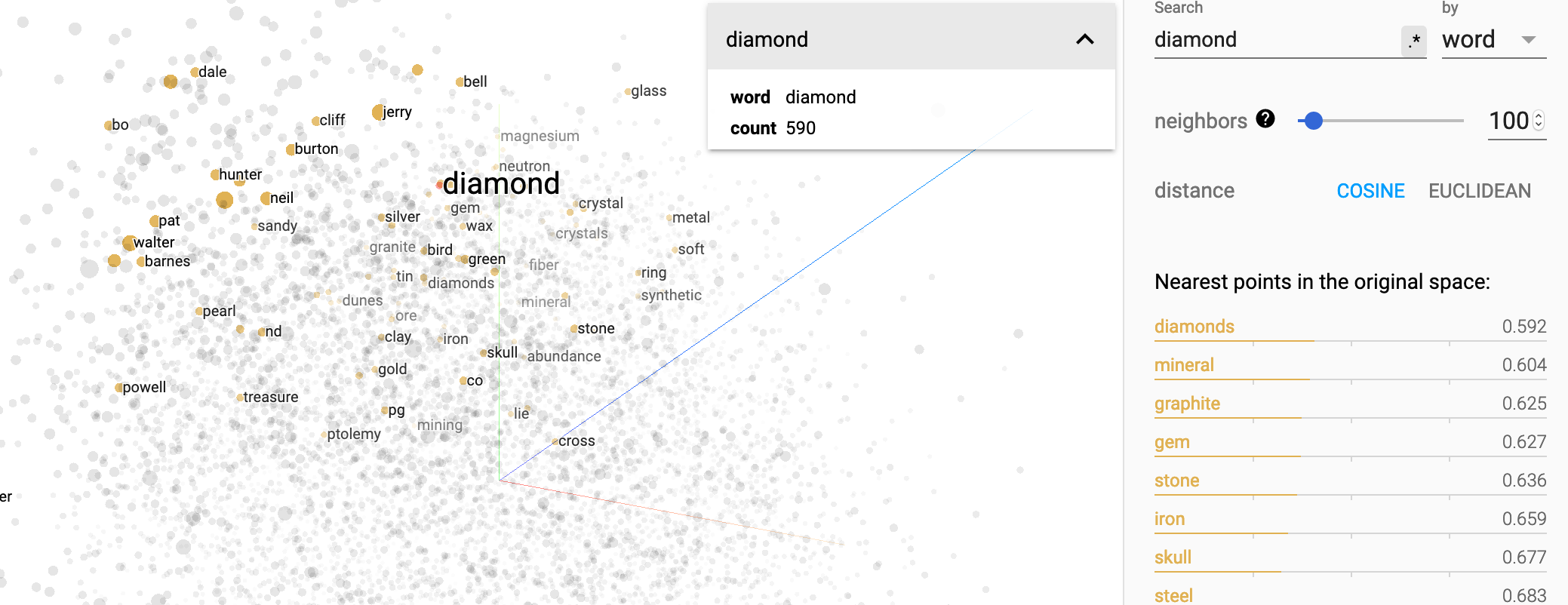
Tensorflow에 포함된 embedding projector라는 tool 통해 살펴본 결과다.
https://projector.tensorflow.org/
diamond와 가까운 단어로 diamonds, mineral, graphite, gem, stone 등 나온다. 주변 단어들을 통해 단어의 의미를 파악하는 skipgram 알고리즘의 원리를 안다면 왜 이런 결과가 나오는지 알 수 있다.
skipgram 알고리즘 원리
먼저 임의의 값으로 벡터들을 초기화한 후, 특정 단어가 주어졌을 때 그 주변 단어들의 등장 확률을 증가시키는 방향으로 학습하는 알고리즘
