
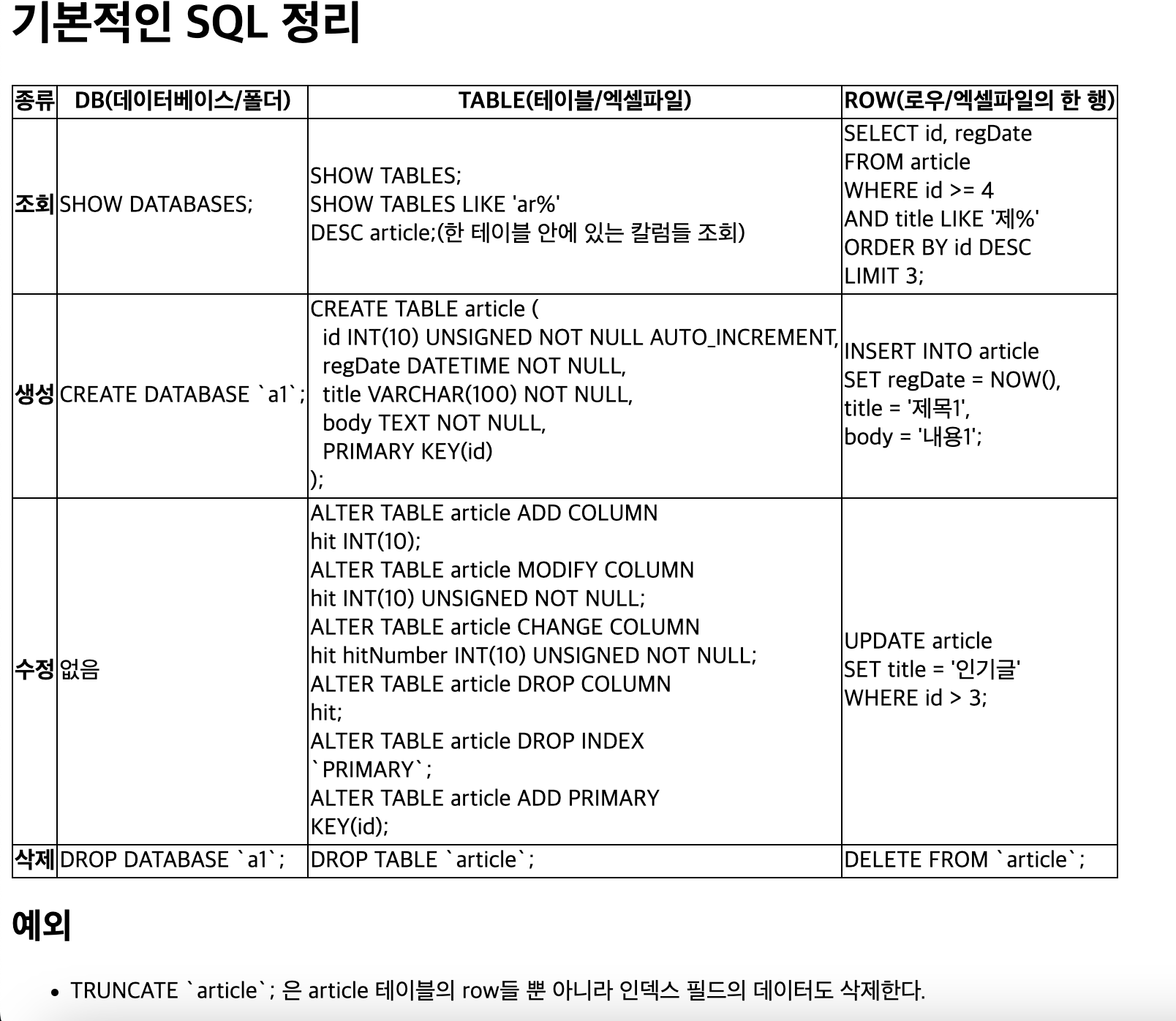
# 전체 데이터베이스 리스팅
SHOW DATABASES;
# `mysql` 데이터 베이스 선택
USE mysql;
# 테이블 리스팅
SHOW TABLES;
# 특정 테이블의 구조
DESC `user`;
# `test` 데이터 베이스 선택(없으면 먼저 만들어주세요.)
CREATE DATABASE IF NOT EXISTS test;
USE test;
# 테이블 리스팅
SHOW TABLES;
# 기존에 a1 데이터베이스가 존재 한다면 삭제
DROP DATABASE IF EXISTS `a1`;
# 새 데이터베이스(`a1`) 생성
CREATE DATABASE `a1`;
# 데이터베이스(`a1`) 선택
USE `a1`;
# 데이터베이스 추가 되었는지 확인
SHOW DATABASES;
# 테이블 확인
SHOW TABLES;
# 게시물 테이블 article(title, body)을 만듭니다.
# VARCHAR(100) => 문자 100개 저장가능
# text => 문자 많이 저장가능
CREATE TABLE article (
title VARCHAR(100),
`body` TEXT
);
# 잘 추가되었는지 확인, 리스팅과 구조까지 확인
SHOW TABLES;
DESC article;
# 데이터 하나 추가(title = 제목, body = 내용)
INSERT INTO article
SET title = '제목',
`body` = '내용';
# 데이터 조회(title 만)
SELECT title
FROM article;
# 데이터 조회(title, body)
SELECT title, `body`
FROM article;
# 데이터 조회(body, title)
SELECT `body`, title
FROM article;
# 데이터 조회(*)
SELECT *
FROM article;
# 데이터 또 하나 추가(title = 제목, body = 내용)
INSERT INTO article
SET title = '제목',
`body` = '내용';
# 데이터 조회(*, 어떤게 2번 게시물인지 알 수 없음)
SELECT *
FROM article;
# 테이블 구조 수정(id 칼럼 추가, first)
ALTER TABLE article ADD COLUMN id INT FIRST;
# 데이터 조회(*, id 칼럼의 값은 NULL)
SELECT *
FROM article;
# 기존 데이터에 id값 추가(id = 1, id IS NULL)
UPDATE article
SET id = 1
WHERE id IS NULL;
# 데이터 조회(*, 둘다 수정되어 버림..)
SELECT *
FROM article;
# 기존 데이터 중 1개만 id를 2로 변경(LIMIT 1)
UPDATE article
SET id = 2
LIMIT 1;
# 데이터 조회(*)
SELECT *
FROM article;
# 데이터 1개 추가(id = 3, title = 제목3, body = 내용3)
INSERT INTO article
SET id = 3,
title = '제목3',
body = '내용3';
# 데이터 조회(*)
SELECT *
FROM article;
# 2번 게시물, 데이터 삭제 => DELETE
DELETE FROM article
WHERE id = 2;
# 데이터 조회(*)
SELECT *
FROM article;
# 날짜 칼럼 추가(id 칼럼 뒤에) => regDate DATETIME
ALTER TABLE article ADD COLUMN regDate DATETIME AFTER id;
# 테이블 구조 확인
DESC article;
# 데이터 조회(*, 날짜 정보가 비어있음)
SELECT *
FROM article;
# 1번 게시물의 비어있는 날짜정보 채움(regDate = 2018-08-10 15:00:00)
UPDATE article
SET regDate = '2018-08-10 15:00:00'
WHERE id = 1;
# 데이터 조회(*, 이제 2번 게시물의 날짜 정보만 넣으면 됩니다.)
SELECT *
FROM article;
# NOW() 함수 실행해보기
SELECT NOW();
# 3번 게시물의 비어있는 날짜정보 채움(NOW())
UPDATE article
SET regDate = NOW()
WHERE id = 3;
# 데이터 조회(*)
SELECT *
FROM article;# 기존에 a2 데이터베이스가 존재 한다면 삭제
DROP DATABASE IF EXISTS `a2`;
# 새 데이터베이스(`a2`) 생성
CREATE DATABASE `a2`;
# 새 데이터베이스(`a2`) 선택
USE `a2`;
# article 테이블 생성(id, regDate, title, body)
CREATE TABLE article (
id INT,
regDate DATETIME,
title VARCHAR(100),
`body` TEXT
);
# article 테이블 조회(*)
SELECT *
FROM `article`;
# article 테이블에 data insert (regDate = NOW(), title = '제목', body = '내용')
INSERT INTO article
SET regDate = NOW(),
title = '제목',
`body` = '내용';
# article 테이블에 data insert (regDate = NOW(), title = '제목', body = '내용')
INSERT INTO article
SET regDate = NOW(),
title = '제목',
`body` = '내용';
# article 테이블 조회(*)
## id가 NULL인 데이터 생성이 가능하네?
SELECT *
FROM `article`;
# id 데이터는 꼭 필수 이기 때문에 NULL을 허용하지 않게 바꾼다.(alter table, not null)
## 기존의 NULL값 때문에 실패가 뜬다.
# ALTER TABLE article MODIFY id INT NOT NULL;
# 기존의 NULL값이 0으로 바뀐다.
UPDATE article SET id = 0;
# NULL을 허용하지 않게 바꾼다.(alter table, not null)
ALTER TABLE article MODIFY id INT NOT NULL;
# article 테이블 조회(*)
SELECT *
FROM `article`;
# 생각해 보니 모든 행(row)의 id 값은 유니크 해야한다.(ADD PRIMARY KEY(id))
## 오류가 난다. 왜냐하면 기존의 데이터 중에서 중복되는게 있기 때문에
# ALTER TABLE article ADD PRIMARY KEY(id);
# id가 0인 것 중에서 1개를 id 1로 바꾼다.
UPDATE article
SET id = 1
WHERE id = 0
LIMIT 1;
# article 테이블 조회(*)
SELECT *
FROM article;
# id가 0인것을 id 2로 바꾼다.
UPDATE article
SET id = 2
WHERE id = 0;
# 생각해 보니 모든 행(row)의 id 값은 유니크 해야한다.(ADD PRIMARY KEY(id))
## 이제 적용이 잘 된다.
ALTER TABLE article ADD PRIMARY KEY(id);
# id 칼럼에 auto_increment 를 건다.
## auto_increment 를 걸기전에 해당 칼럼은 무조건 key 여야 한다.
ALTER TABLE article MODIFY COLUMN id INT NOT NULL AUTO_INCREMENT;
# article 테이블 구조확인(desc)
DESC article;
# 나머지 칼럼 모두에도 not null을 적용해주세요.
ALTER TABLE article MODIFY COLUMN regDate DATETIME NOT NULL;
ALTER TABLE article MODIFY COLUMN title VARCHAR(100) NOT NULL;
ALTER TABLE article MODIFY COLUMN `body` TEXT NOT NULL;
# id 칼럼에 UNSIGNED 속성을 추가하세요.
ALTER TABLE article MODIFY COLUMN id INT UNSIGNED NOT NULL AUTO_INCREMENT;
DESC article;
# 작성자(writer) 칼럼을 title 칼럼 다음에 추가해주세요.
ALTER TABLE article ADD COLUMN writer VARCHAR(100) NOT NULL AFTER title;
# 작성자(writer) 칼럼의 이름을 nickname 으로 변경해주세요.(ALTER TABLE article CHANGE oldName newName TYPE 조건)
ALTER TABLE article CHANGE `writer` `nickname` VARCHAR(100) NOT NULL;
DESC article;
# nickname 칼럼의 위치를 body 밑으로 보내주세요.(MODIFY COLUMN nickname)
ALTER TABLE article MODIFY COLUMN nickname VARCHAR(100) NOT NULL AFTER body;
DESC article;
# hit 조회수 칼럼 추가 한 후 삭제해주세요.
ALTER TABLE article ADD COLUMN hit INT UNSIGNED NOT NULL AFTER nickname;
DESC article;
ALTER TABLE article DROP COLUMN hit;
DESC article;
# hit 조회수 칼럼을 다시 추가
ALTER TABLE article ADD COLUMN hit INT UNSIGNED NOT NULL AFTER nickname;
DESC article;
# 기존의 비어있는 닉네임 채워넣기(무명)
UPDATE article
SET nickname = '무명'
WHERE nickname = '';
# article 테이블에 데이터 추가(regDate = NOW(), title = '제목3', body = '내용3', nickname = '홍길순', hit = 10)
INSERT INTO article
SET regDate = NOW(),
title = '제목3',
`body` = '내용3',
nickname = '홍길순',
hit = 10;
# article 테이블에 데이터 추가(regDate = NOW(), title = '제목4', body = '내용4', nickname = '홍길동', hit = 55)
INSERT INTO article
SET regDate = NOW(),
title = '제목4',
`body` = '내용4',
nickname = '홍길동',
hit = 55;
# article 테이블에 데이터 추가(regDate = NOW(), title = '제목5', body = '내용5', nickname = '홍길동', hit = 10)
INSERT INTO article
SET regDate = NOW(),
title = '제목5',
`body` = '내용5',
nickname = '홍길동',
hit = 10;
# article 테이블에 데이터 추가(regDate = NOW(), title = '제목6', body = '내용6', nickname = '임꺽정', hit = 100)
INSERT INTO article
SET regDate = NOW(),
title = '제목6',
`body` = '내용6',
nickname = '임꺽정',
hit = 100;
# 조회수 가장 많은 게시물 3개 만 보여주세요., 힌트 : ORDER BY, LIMIT
SELECT * FROM article ORDER BY hit DESC LIMIT 3;
# 작성자명이 '홍길'로 시작하는 게시물만 보여주세요., 힌트 : LIKE '홍길%'
SELECT * FROM article WHERE nickname LIKE '홍길%';
# 조회수가 10 이상 55 이하 인것만 보여주세요., 힌트 : WHERE 조건1 AND 조건2
SELECT * FROM article WHERE hit >= 10 AND hit <= 55;
# 작성자가 '무명'이 아니고 조회수가 50 이하인 것만 보여주세요., 힌트 : !=
SELECT * FROM article WHERE nickname != '무명' AND hit <= 50;
# 작성자가 '무명' 이거나 조회수가 55 이상인 게시물을 보여주세요. 힌트 : OR
SELECT * FROM article WHERE nickname = '무명' OR hit >= 55;SELECT * FROM emp, dept;
# 여기서 쉼표(,) 는 INNER JOIN 과 똑같은 말이다.
SELECT * FROM emp INNER JOIN dept;위에서 쉼표는 INNER JOIN 과 똑같다는 걸 알아두자. 따라서 두 sql문의 결과는 같다.
이런 무지성적인 JOIN은 원하는 결과 도출이 안될 수 있다. 따라서 추가 조건을 명시해줘야 한다. 따라서 ON 을 통해 쓸데없는 조합까지 가져오는 것을 막을 수 있다.
SELECT emp.*, dept.id, dept.name AS `부서명`
FROM emp
INNER JOIN dept
ON emp.deptId = dept.id;# a5 데이터베이스 삭제/생성/선택
DROP DATABASE IF EXISTS a5;
CREATE DATABASE a5;
USE a5;
# 부서(dept) 테이블 생성 및 홍보부서 기획부서 추가
CREATE TABLE dept (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
PRIMARY KEY(id),
regDate DATETIME NOT NULL,
`name` CHAR(100) NOT NULL UNIQUE
);
INSERT INTO dept
SET regDate = NOW(),
`name` = '홍보';
INSERT INTO dept
SET regDate = NOW(),
`name` = '기획';
SELECT *
FROM dept;
# 사원(emp) 테이블 생성 및 홍길동사원(홍보부서), 홍길순사원(홍보부서), 임꺽정사원(기획부서) 추가
CREATE TABLE emp (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
PRIMARY KEY(id),
regDate DATETIME NOT NULL,
`name` CHAR(100) NOT NULL,
deptName CHAR(100) NOT NULL
);
INSERT INTO emp
SET regDate = NOW(),
`name` = '홍길동',
deptName = '홍보';
INSERT INTO emp
SET regDate = NOW(),
`name` = '홍길순',
deptName = '홍보';
INSERT INTO emp
SET regDate = NOW(),
`name` = '임꺽정',
deptName = '기획';
SELECT *
FROM emp;
# 홍보를 마케팅으로 변경
## 부서명 변경(홍보 => 마케팅)
SELECT *
FROM dept;
UPDATE dept
SET `name` = '마케팅'
WHERE `name` = '홍보';
SELECT *
FROM dept;
## 사원테이블에서 부서명 변경(홍보 => 마케팅)
SELECT *
FROM emp;
UPDATE emp
SET deptName = '마케팅'
WHERE deptName = '홍보';
SELECT *
FROM emp;
# 마케팅을 홍보로 변경
## 부서명 변경(마케팅 => 홍보)
SELECT *
FROM dept;
UPDATE dept
SET `name` = '홍보'
WHERE `name` = '마케팅';
SELECT *
FROM dept;
## 사원테이블에서 부서명 변경(마케팅 => 홍보)
SELECT *
FROM emp;
UPDATE emp
SET deptName = '홍보'
WHERE deptName = '마케팅';
SELECT *
FROM emp;
# 홍보를 마케팅으로 변경
## 구조를 변경하기로 결정(사원 테이블에서, 이제는 부서를 이름이 아닌 번호로 기억)
ALTER TABLE emp ADD COLUMN deptId INT UNSIGNED NOT NULL;
SELECT *
FROM emp;
UPDATE emp
SET deptId = 1
WHERE deptName = '홍보';
UPDATE emp
SET deptId = 2
WHERE deptName = '기획';
SELECT *
FROM emp;
ALTER TABLE emp DROP COLUMN deptName;
## 이제 더 이상 emp 테이블에 부서명이 없다.
SELECT *
FROM emp;
## 부서명 변경(홍보 => 마케팅)
SELECT *
FROM dept;
UPDATE dept
SET `name` = '마케팅'
WHERE `name` = '홍보';
SELECT *
FROM dept;
# 사장님께 드릴 인명록을 생성
SELECT *
FROM emp;
# 사장님께서 부서번호가 아니라 부서명을 알고 싶어하신다.
## 그래서 dept 테이블 조회법을 알려드리고 혼이 났다.
SELECT *
FROM dept
WHERE id = 1;
# 사장님께 드릴 인명록을 생성(v2, 부서명 포함, ON 없이)
## 이상한 데이터가 생성되어서 혼남
SELECT emp.*, dept.name AS `부서명`
FROM emp
INNER JOIN dept; /* 2개 테이블의 모든 데이터들의 조합으로 구성된 무지성병합테이블이 생성되고 거기서 내용을 가져온다. */
# 사장님께 드릴 인명록을 생성(v3, 부서명 포함, 올바른 조인 룰(ON) 적용)
## 보고용으로 좀 더 편하게 보여지도록 고쳐야 한다고 지적받음
SELECT emp.*, dept.id, dept.name AS `부서명`
FROM emp
INNER JOIN dept
ON emp.deptId = dept.id; /* 무지성병합테이블에서 이상한 데이터를 없앤다, 즉 이 조건을 만족하지 못하는 녀석은 필터링 한다. INNER JOIN 사용할 때 ON 은 필수 */
# 사장님께 드릴 인명록을 생성(v4, 사장님께서 보시기에 편한 칼럼명(AS))
SELECT emp.id AS `사원번호`,
emp.name AS `사원명`,
DATE(emp.regDate) AS `입사일`,
dept.name AS `부서명`
FROM emp
INNER JOIN dept
ON emp.deptId = dept.id
ORDER BY `부서명`, `사원명`;
# 사장님께 드릴 인명록을 생성(v5, 테이블 AS 적용)
SELECT E.id AS `사원번호`,
E.name AS `사원명`,
DATE(E.regDate) AS `입사일`,
D.name AS `부서명`
FROM emp AS E
INNER JOIN dept AS D
ON E.deptId = D.id
ORDER BY `부서명`, `사원명`;
# 추가내용
# 기획부서에 김영희가 배속되었다.
## 먼저 기획부서의 번호가 몇번인지 확인
SELECT *
FROM dept;
INSERT INTO emp
SET regDate = NOW(),
`name` = '김영희',
deptId = 2
# 신설 IT부서에 김철수가 배속되었다.
INSERT INTO dept
SET regDate = NOW(),
`name` = 'IT';
## IT 부서의 번호가 3번임을 확인
SELECT *
FROM dept;
INSERT INTO emp
SET regDate = NOW(),
`name` = '김철수',
deptId = 3;JOIN 연습
JOIN은 곱이다.
ON 은 쓸데없는 데이터를 걸러준다.
# DB a3 삭제, 생성, 선택
DROP DATABASE IF EXISTS a3;
CREATE DATABASE a3;
USE a3;
# article 테이블 생성
CREATE TABLE article (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
regDate DATETIME NOT NULL,
`subject` VARCHAR(100) NOT NULL,
`body` TEXT NOT NULL
);
# article 테이블에 데이터 3개 넣기
INSERT INTO article
SET regDate = NOW(),
`subject` = '제목1',
`body` = '내용1';
INSERT INTO article
SET regDate = NOW(),
`subject` = '제목2',
`body` = '내용2';
INSERT INTO article
SET regDate = NOW(),
`subject` = '제목3',
`body` = '내용3';
# article 확인
SELECT * FROM article;
# comment 테이블 생성
CREATE TABLE `comment` (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
regDate DATETIME NOT NULL,
articleId INT UNSIGNED NOT NULL,
`body` TEXT NOT NULL
);
# comment 테이블에 데이터 3개 넣기
## 1번글에 댓글 2개
## 2번글에 댓글 1개
## 3번글에 댓글 0개
INSERT INTO `comment`
SET regDate = NOW(),
articleId = 1,
`body` = '댓글 내용 1';
INSERT INTO `comment`
SET regDate = NOW(),
articleId = 1,
`body` = '댓글 내용 2';
INSERT INTO `comment`
SET regDate = NOW(),
articleId = 2,
`body` = '댓글 내용 3';
# comment 확인
SELECT * FROM `comment`;
# 요구사항 1 : 댓글 리스트
SELECT *
FROM `comment` AS C;
# 요구사항 2 : 댓글 리스트(ON 사용금지)(게시물 번호, 댓글 번호, 댓글 내용)
## 쓸데없는 조합이 생겨버렸다.
SELECT C.articleId, C.id, C.body
FROM `comment` AS C
# 요구사항 3 : 댓글 리스트(게시물 번호, 게시물 제목, 댓글 번호, 댓글 내용)
SELECT A.id, A.subject, C.id, C.body
FROM `comment` AS C
INNER JOIN article AS A
ON C.articleId = A.id;Group 함수, Group 조건 , 서브쿼리
group 조건이 없으면 sum, max와 같은 그룹합수로 인해 여러 데이터가 하나로 압축되어 표현된다.
SELECT SQL 각 구문별 실행 순서
-
FROM, JOIN
-
ON, WHERE
-
2차 테이블 완성
-
GROUP BY
-
그룹함수
-
3차 테이블 완성(그룹작업이 있을 경우에만)
-
HAVING
-
4차 테이블 완성(HAVING작업이 있을 경우에만)
-
ORDER BY
-
LIMIT
-
고객(MySQL 클라이언트, 대표적으로 Sequel Pro, SQLYog, JDBC Driver 등)에게 전달
# 현재 세션에서 `ONLY_FULL_GROUP_BY` 모드 끄기
## 영구적으로 설정되는 것은 아닙니다.
SET SESSION sql_mode = (SELECT REPLACE(@@sql_mode, 'ONLY_FULL_GROUP_BY', ''));
SET sql_mode = (SELECT REPLACE(@@sql_mode, 'ONLY_FULL_GROUP_BY', ''));
# a6 DB 삭제/생성/선택
DROP DATABASE IF EXISTS a6;
CREATE DATABASE a6;
USE a6;
# 부서(홍보, 기획)
CREATE TABLE dept (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
regDate DATETIME NOT NULL,
`name` CHAR(100) NOT NULL UNIQUE
);
INSERT INTO dept
SET regDate = NOW(),
`name` = '홍보';
INSERT INTO dept
SET regDate = NOW(),
`name` = '기획';
# 사원(홍길동/홍보/5000만원, 홍길순/홍보/6000만원, 임꺽정/기획/4000만원)
CREATE TABLE emp (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
regDate DATETIME NOT NULL,
`name` CHAR(100) NOT NULL,
deptId INT UNSIGNED NOT NULL,
salary INT UNSIGNED NOT NULL
);
INSERT INTO emp
SET regDate = NOW(),
`name` = '홍길동',
deptId = 1,
salary = 5000;
INSERT INTO emp
SET regDate = NOW(),
`name` = '홍길순',
deptId = 1,
salary = 6000;
INSERT INTO emp
SET regDate = NOW(),
`name` = '임꺽정',
deptId = 2,
salary = 4000;
# 사원 수 출력
SELECT COUNT(*)
FROM emp;
# 가장 큰 사원 번호 출력
SELECT MAX(id)
FROM emp;
# 가장 고액 연봉
SELECT MAX(salary)
FROM emp;
# 가장 저액 연봉
SELECT MIN(salary)
FROM emp;
# 회사에서 1년 고정 지출(인건비)
SELECT SUM(salary)
FROM emp;
# 부서별, 1년 고정 지출(인건비)
SELECT deptId, SUM(salary)
FROM emp
GROUP BY deptId;
# 부서별, 최고연봉
SELECT deptId, MAX(salary)
FROM emp
GROUP BY deptId;
# 부서별, 최저연봉
SELECT deptId, MIN(salary)
FROM emp
GROUP BY deptId;
# 부서별, 평균연봉
SELECT deptId, AVG(salary)
FROM emp
GROUP BY deptId;
# 부서별, 부서명, 사원리스트, 평균연봉, 최고연봉, 최소연봉, 사원수
## V1(조인 안한 버전)
### IF문 버전
SELECT IF(deptId = 1, '홍보', '기획') AS `부서명`,
GROUP_CONCAT(`name` ORDER BY id DESC SEPARATOR ', ') AS `사원리스트`,
CONCAT(FORMAT(AVG(E.salary), 0), '만원') AS `평균연봉`,
CONCAT(MAX(salary), '만원') AS `최고연봉`,
CONCAT(MIN(salary), '만원') AS `최소연봉`,
CONCAT(COUNT(*), '명') AS `사원수`
FROM emp
GROUP BY deptId;
### CASE문을 사용하고, GROUP_CONCAT의 결과에서 중복제거도 처리도 한 버전
SELECT CASE
WHEN deptId = 1
THEN '홍보'
WHEN deptId = 2
THEN '기획'
ELSE '무소속'
END AS `부서명`,
GROUP_CONCAT(DISTINCT `name` ORDER BY id DESC SEPARATOR ', ') AS `사원리스트`,
CONCAT(FORMAT(AVG(E.salary), 0), '만원') AS `평균연봉`,
MAX(salary) AS `최고연봉`,
MIN(salary) AS `최소연봉`,
COUNT(*) AS `사원수`
FROM emp
GROUP BY deptId;
## V2(조인해서 부서명까지 나오는 버전)
SELECT D.name AS 부서,
GROUP_CONCAT(E.name) AS 사원리스트,
CONCAT(FORMAT(AVG(E.salary), 0), '만원') AS `평균연봉`,
MAX(E.salary) AS 최고연봉,
MIN(E.salary) AS 최소연봉,
COUNT(*) AS 사원수
FROM emp AS E
INNER JOIN dept AS D
ON E.deptId = D.id
GROUP BY E.deptId;
## V3(V2에서 평균연봉이 5000이상인 부서로 추리기)
SELECT D.name AS 부서,
GROUP_CONCAT(E.name) AS 사원리스트,
TRUNCATE(AVG(E.salary), 0) AS 평균연봉,
MAX(E.salary) AS 최고연봉,
MIN(E.salary) AS 최소연봉,
COUNT(*) AS 사원수
FROM emp AS E
INNER JOIN dept AS D
ON E.deptId = D.id
GROUP BY E.deptId
HAVING `평균연봉` >= 5000;
## V4(V3에서 HAVING 없이 서브쿼리로 수행)
### HINT, UNION을 이용한 서브쿼리
# SELECT *
# FROM (
# SELECT 1 AS id
# UNION
# SELECT 2
# UNION
# SELECT 3
# ) AS A
SELECT *
FROM (
SELECT D.name AS `부서명`,
GROUP_CONCAT(E.`name`) AS `사원리스트`,
TRUNCATE(AVG(E.salary), 0) AS `평균연봉`,
MAX(E.salary) AS `최고연봉`,
MIN(E.salary) AS `최소연봉`,
COUNT(*) AS `사원수`
FROM emp AS E
INNER JOIN dept AS D
ON E.deptId = D.id
WHERE 1
GROUP BY E.deptId
) AS D
WHERE D.`평균연봉` >= 5000;서브쿼리란?
서브쿼리란 하나의 SQL 쿼리 안에 또 다른 SQL 쿼리를 포함하는 것. 서브쿼리는 주로 SELECT, FROM, WHERE, HAVING, 또는 INSERT, UPDATE, DELETE 문에서 사용됩니다. 서브쿼리는 외부 쿼리에 의존하며, 외부 쿼리의 결과에 따라 실행되어 결과를 반환합니다.
CREATE TABLE board (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
regDate DATETIME NOT NULL,
`name` CHAR(100) NOT NULL UNIQUE
);
INSERT INTO board
SET regDate = NOW(),
`name` = '공지';
INSERT INTO board
SET regDate = NOW(),
`name` = '자유';
SELECT *
FROM board
WHERE `name` = '공지';
# 쿼리 1 : 테이블에서 바로 꺼내오는 경우
SELECT *
FROM board;
# 쿼리 2 : SELECT의 결과를 테이블삼아서 거기에서 꺼내오는 경우
SELECT *
FROM (
SELECT 1 AS id, NOW() AS regDate, '공지' AS `name`
UNION
SELECT 2 AS id, NOW() AS regDate, '자유' AS `name`
) AS board;
# 쿼리 3 : SELECT의 결과를 테이블삼아서 거기에서 꺼내오는 경우
SELECT *
FROM (
SELECT * FROM board
) AS board;
백엔드 개발자를 꿈꿉니다