https://github.com/raypretam/adaptive_llm_selection
https://arxiv.org/abs/2602.11931
모델 선택 자동화 LLM orchestration Framework
문제 정의 :
- 모델을 선택할때의 이슈는 토큰이 적은대신 정확도가 낮은 slm 을 사용할것인가, 아니면 토큰 사용량이 비싼 대형 모델을 사용할것인가의 트레이드 오프 문제
AS-IS:
- 기존에는 정적 규칙 즉 정확도의 threshold를 인간이 설정하는 방식으로 멀티 모델 선택을 자동화 했었음.
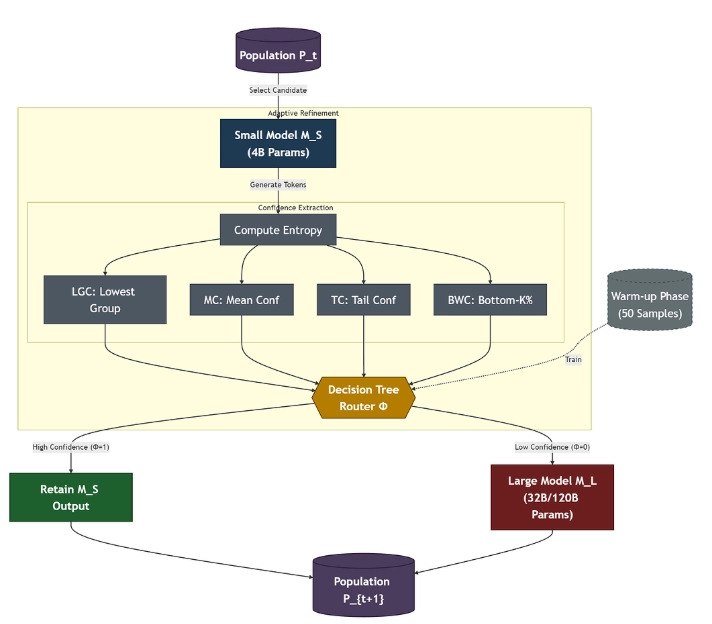
그림 이해
- population은 해결해야하는 문제의 답. 즉 문제 학습을 여러번 루프를 돌면서 하는데 이것은 한 타임스텝에 대한 도표임.
- 이걸 먼저 작은 모델에 돌림.
- 그 결과를 AdaptiveEvolve 프레임워크에서는 엔트로피 4가지 기준으로 점수를 냄.
- lgc: 가장 신뢰도 낮은 토큰 그룹
- mc: 평균 신뢰도
- tc: 가장 낮은 신뢰도 영역
- bwc: 신뢰도 낮은 토큰 K%
- 이걸 decision tree =if 문 을 통해 좀더 큰 모델로 갈지 말지를 고민.
- 신뢰도가 1이면 작은 모델로 남고, 0이면 더 큰 모델로 넘어감.
- 이 프레임워크를 사용하려면 샘플로 50개 질문을 학습시켜야함.
여기서 질문 population이 정확히 어떤 개념임?
질문이 “통영시에서 가장 오래된 노인정을 찾는 sql을 생성해줘” 이면
population = [”sql1”, “sql2”, “sql3” ]
여기서 질문! entropy 신뢰도는 어떻게 나오는 값임?
이걸 설명하려면 llm이 다음 토큰을 찾을때 어떻게 찾는지 알아야함.
llm은 다음 토큰을 낼때, 각 토큰 후보 예) 서울, 도쿄, 부산 와 도큰 후보의 확률 서울:0.9, 도쿄:0.05, 부산:0.01 을 계산함.
[ 신뢰도 높음 ]
A → 0.95
B → 0.02
C → 0.02
D → 0.01
[ 신뢰도 낮음 ]
A → 0.25
B → 0.25
C → 0.25
D → 0.25
그래서 결과
l* lm 토큰 비용 38% 절감
- 정확도 97%
의의
- 우리 회사 챗봇에 사용해볼만한 프레임워크라 생각함. 실제 깃허브도 있어서 시도해볼만함.
- 웍스 ai 블로그에도 모델 선택 자동화에 대한 이야기가 있었던 만큼 실제 챗봇 시장에서 유의미한
- 다만 테스트셋 50개가 필요한데, 통영처럼 타게팅된 질문이 있는 경우에 더욱 적절하다 생각.

그때 그때 꽂힌것 하는 개발블로그