https://arxiv.org/abs/2602.11151
왜 퍼플랙시티는 이렇게 빠를까???
웹 규모의 검색을 위한 다국어 임베딩 모델 패밀리
웹 스케일 검색·RAG에서 고품질 텍스트 임베딩 제공.
| backbone | 디퓨전(diffusion) 사전학습 LM |
|---|---|
| traning | 다단계 대조 학습(multi-stage contrastive learning) |
모델 종류
- pplx-embed-v1 - 0.6B 표준 검색용
- pplx-embed-context-v1 - 4B 문서 전체 문맥을 청크에 유지하는 임베딩용

디퓨전?
- = 노이즈 복원 학습 방식
- 완전 노이즈에서 스탭별로 점진적으로 노이즈를 줄여가면서 생성하는 생성형 모델

각 모델별 학습 방식
- GPT
- I love → [ ? ]
- 이전 토큰을 기반으로 이후 토큰을 예측
- 단방향
- BERT
- I [mask] you
- 랜덤하게 마스킹 하는 방식으로 학습
- 양방향
- Diffusion
- I [noise] you [noise] much → I [noise] you so much → I love you so much
- 스탭별로 점진적 노이즈 제거
- 양방향
PPLX Embedding 학습 과정
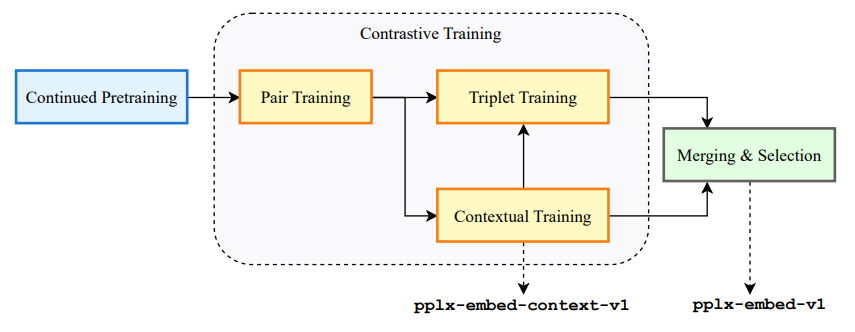
1. Continued Pretraining
Decoder-only LLM(Qwen3)을 diffusion objective로 재학습해 bidirectional attention 기반 인코더로 전환한다. 이후 모든 단계의 베이스 모델이 된다.
2. Pair Training
쿼리–문서 쌍을 InfoNCE 기반 contrastive loss로 학습한다. English → cross-lingual → multilingual 순서의 커리큘럼으로 진행된다.
3. Triplet Training
Pair Training 체크포인트에서 hard negative를 포함한 triplet 형식으로 추가 학습한다. 의미적으로 유사하지만 관련 없는 문서 간 구분력을 높이는 단계다.
4. Contextual Training
Pair Training과 병렬로 진행된다. 문서를 청크로 나눌 때 청크 임베딩에 문서 전체의 전역 컨텍스트를 반영하도록 학습한다. pplx-embed-context-v1 전용 단계다.
5. Merging & Selection
Triplet Training 결과와 Contextual Training 결과 두 체크포인트를 spherical interpolation으로 병합해 최종 모델 두 가지를 산출한다.
최종 출력
- pplx-embed-v1: 범용 검색용 임베딩 모델
- pplx-embed-context-v1: 긴 문서의 전역 컨텍스트를 청크 단위 임베딩에 반영한 모델

그때 그때 꽂힌것 하는 개발블로그