기초개념
1. GAN (generative adversary network)
- 이미지를 생성하는 생성자 모델, ai가 만든 이미지와 진짜 이미지를 판별하는 판별자 모델을 만들어서
- 둘을 경쟁시켜서 모델의 생성된 이미지의 결과를 높이는 모델
2. 멜-스펙트로그램(Mel-spectrogram)
- 오디오 신호 처리에서 AI가 소리를 이해하기 가장 좋게 가공한 '소리의 지도’
- Mel Scale: 인간의 청각 특성을 반영하여, 저음역대는 세밀하게 나누고 고음역대는 뭉뚱그려서 표현한 척도
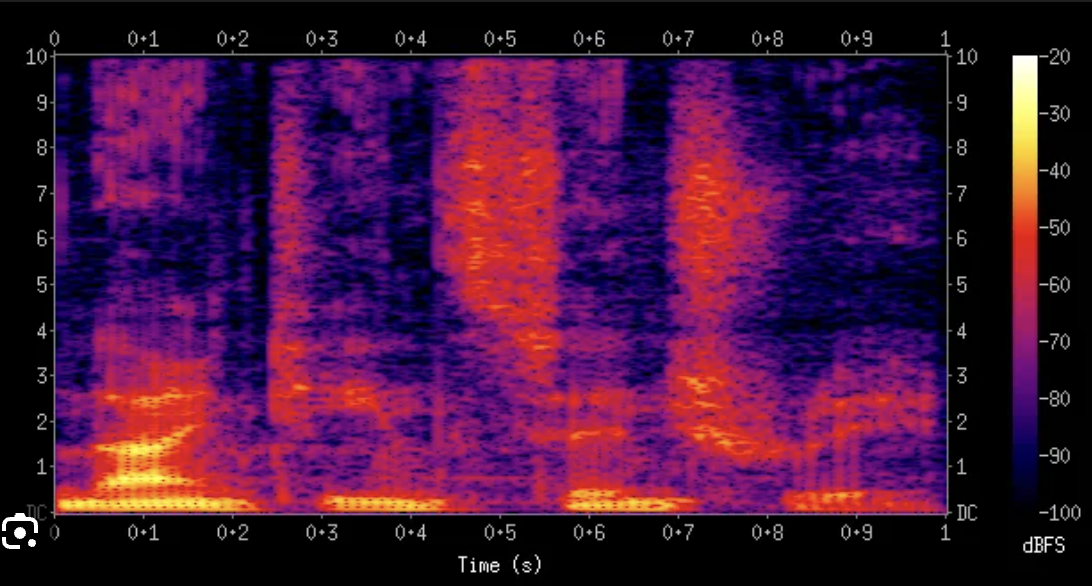
- 스펙트로그램 (Spectrogram) : 소리는 시간에 따라 변하는 파동이지만 이 파동 데이터만 봐서는 어떤 주파수(고음/저음)가 섞여 있는지 알기 어려움
- 푸리에 변환(STFT): 복잡한 파동을 쪼개서 "이 시간에는 100Hz가 이만큼, 2000Hz가 이만큼 들어있어"라고 주파수 성분으로 분해
- 이걸 이미지로 시각화한 것이 스펙트로그램.
- X축: 시간 (Time)
- Y축: 주파수 (Frequency)
- 밝기(색상): 해당 주파수의 에너지 강도 (Magnitude)
- Periodic activation function (주기적 활성화 함수): 활성함수를 보통 ReLu나 뭐 시그모이드 이런거 쓰겠지. 그런데 여기서는 소리의 주기성을 표현하기 위해 사인 함수를 사용.
- Anti-aliased representation (안티-앨리어싱 표현): 디지털 신호를 처리할 때 고주파 성분이 깨지거나 왜곡되는 현상을 '앨리어싱'이라고 하는데, 이걸 막는 기법을 넣어서 소리를 더 매끄럽게 만들었다는 것.
- Inductive bias (귀납적 편향): "오디오는 원래 이런 거야"라는 일종의 사전 지식을 모델 구조 자체에 심음
- scale up to 112M parameters :대규모 파라미터
- 제로샷

그때 그때 꽂힌것 하는 개발블로그