왜 Mamba인가?
transfomer의 시간복잡도O(N2)가 주는 비효율성이 큼
→ 더 효율적으로 GPU 메모리를 쓸 수 있는 방법이 없을까?
특히 gpt계열은 모든 데이터를 인코딩하지 않고 그대로 kv-cache화해서 저장하는 만큼 메모리 비효율성 + 연산량 + 시간이 크다. 그래서 현재 state을 일관적으로 저장하고 기존 데이터 기억을 날리는 방식을 쓰고 싶음.
이전 flow
ssm
-
SSM은 원래 제어 공학에서 쓰던 상태 공간 방정식
-
보행자가 지금 어디()에 있고, 이전에 어떻게 걸어왔는지()를 알면, 다음 위치()를 예측할 수 있다.
-
- 현재 보행자의 위치(x)에 이전 상태 =h를 섞어서 새로운 상태= h_dot을 만든다
-
- 새로운 상태 h를 바탕으로 다음위치 y를 예측
-
왜 'Structured(구조적)'인가?
그냥 SSM은 계산이 너무 복잡해서 딥러닝에 쓰기 어려웠어요. 그래서 '구조(Structure)'를 줬습니다.
• **행렬 $\mathbf{A}$의 마법:** 행렬 $\mathbf{A}$를 아주 특수한 형태(주로 대각 행렬 등)로 설계해서,
아주 긴 시퀀스 데이터도 **병렬 처리(Convolution)**할 수 있게 만들었습니다.
• **결과:** 트랜스포머처럼 N2으로 느려지지 않고, 아주 긴 궤적 데이터도 순식간에 학습할 수 있게 된 거죠.기존 SSM은 '고정된' 필터(A,B,C) 를 써서 데이터와 무관하게 동일하게 반응
맘바
맘바는 여기에 Selection 을 넣는다.
"어? 지금 보행자가 코너를 도네? 그럼 이번 입력은 아주 중요하니까 상태를 세게 업데이트해!"라고 입력값에 따라 필터를 실시간으로 바꿀 수 있음
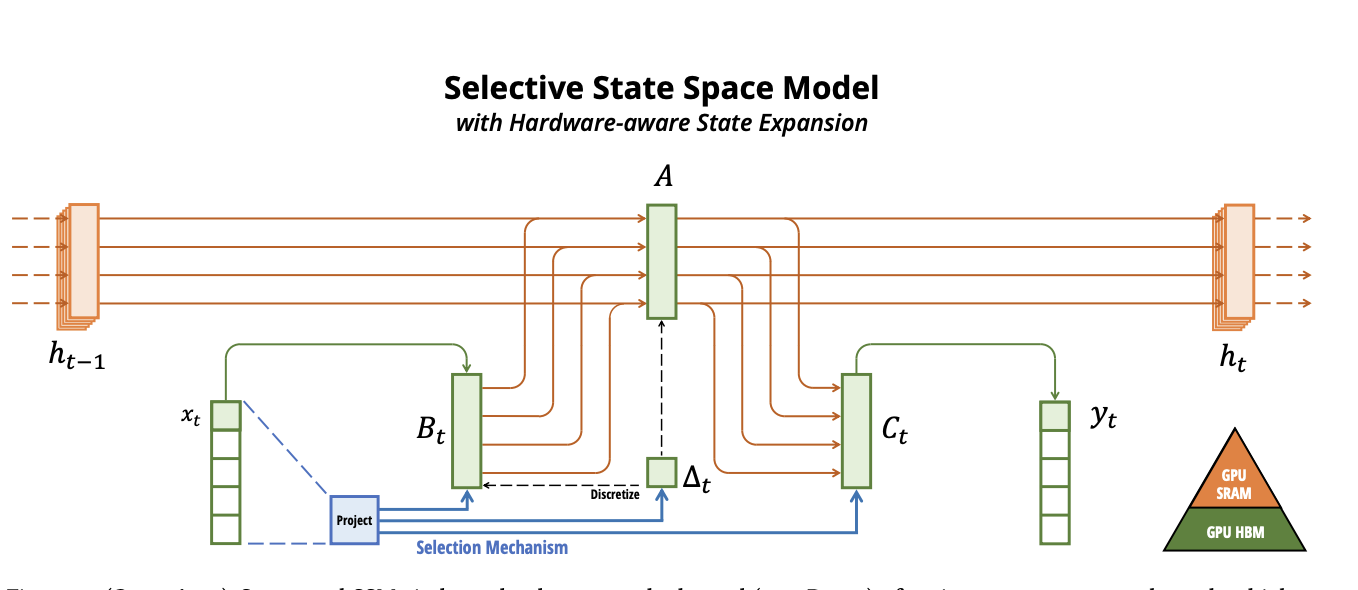
- 수식은 똑같음. 이전 hidden state에 현재 위치 x를 넣어서 필터 A,B,C를 통과하고 그걸로 결과 y를 만듬.
- 근데 여기서 A,B,C가 x에 따라 변동됨 즉 selective ssm
- 현재 보행자의 위치(x)에 이전 상태 =h를 섞어서 새로운 상태= h_dot을 만든다
- 여기서 delta_t는 작으면 옛날 기억을 더 유지하는 방향이고 크면 지금 상황을 더 중요하게 여기는 방향
- GPU SRAM = 빨리 계산가능 GPU HBM=느리지만 오래 유지 → 빨리 빨리연산하는 것만 sram에 올려서 쓰자!
- 핵심: 트랜스포머는 N^2 연산 때문에 데이터를 느린 HBM에서 계속 왔다 갔다 해야 하지만, 맘바는 핵심 연산(Selective Scan)을 빠른 SRAM 안에서 한 번에 끝내버림.
3.2 그래서 어떻게?
기존 RNN & SMM 은 Time-invariant(시불변)
- 시간이 지나도 모델의 파라미터()가 고정되어 있음.
- 파라미터가 모양입니다. 시퀀스 길이가 100이든 1000이든 똑같은 가중치를 씁니다. 보행자가 뛰든 걷든 똑같은 필터를 적용
MAMBA는 Time-variant
( dimension 추가): 파라미터가 모양이 됨. 여기서 L은 시퀀스의 길이(Length). 즉, 매 timestamp 마다 파라미터가 새로 생성된다는 뜻

또한 파라미터가 특정 변수가 아니라 함수로 작동.
3.5
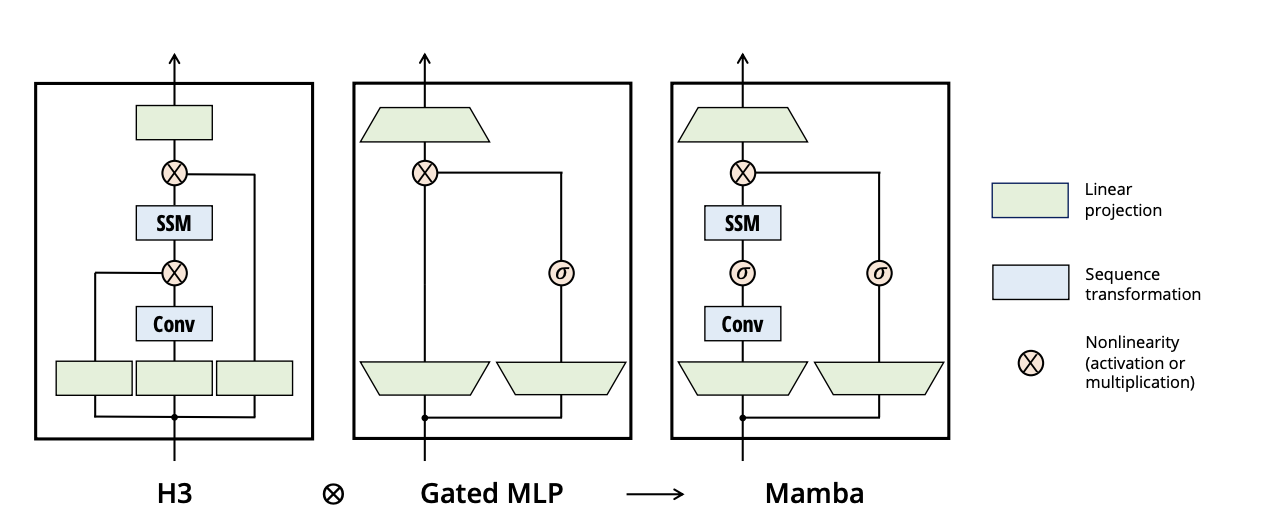
X : 두 경로를 곱해서, 한쪽이 다른 쪽을 조절한다
σ : 활성함수.. 보통 시그모이드를 써서 게이트를 잠그거나 여는걸 하는데 여기서는 SiLU (Swish) 를 씀. Swish는 x에 시그모이드를 곱한값
- H3 = SSM(장기 시퀀스에 강함, attention보다 ) 에 Conv1d(지역 시퀀스에 강함)을 더한 구조
- Gated MLP = 이 정보가 중요한지 여부를 활성함수로 조절
- Conv1d가 주변 4개 토큰 정도를 들고 그 지역의 피처를 뽑는다
- SSM 은 전체 State를 들고 앞에서 본 정보를 누적한다
- 거기에 GatedMLP로 SiLu를 써서 얼마나 SSM+Conv로 만들어진 피처를 얼마나 통과시킬지 결정한다
- 그 결과 히든 스테이트가 새로 갱신되고 피처는 다음 스텝으로 넘어간다
Mamba2
. Mamba-1의 한계: Sequential Bottleneck
• 방식: 데이터를 하나하나 순차적으로 훑으며 상태를 갱신(Recurrent).
• 문제: 아무리 SRAM을 잘 써도, 본질적으로 앞의 계산이 끝나야 뒤를 계산 할 수 있음
• 결과: GPU의 병렬처리.. 안 쓰고 뭐해?
Mamba-2 SSD (Structured State Space Duality)
Mamba-2는 SSM(스캔)을 Attention(행렬 곱)처럼 계산할 수 있다
• 핵심: 데이터를 하나씩 훑는 대신, 시퀀스 전체를 거대한 블록 행렬(Block Matrix)로 변환.
• 작동 원리: 반대각선(Semiseparable) 행렬 구조를 활용해, 복잡한 스캔 과정을 행렬곱 연산으로 치환.
• 결과: GPU가 가장 잘하는 '행렬 곱하기'로 계산하니까, Mamba-1보다 연산 속도가 2~8배 빨라짐. NVIDIA Tensor Core를 풀가동!
